寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》提出问题,实现WordCount程序,记录PSP表格 |
其它参考文献 |
结对编程 技能的反面 PSP |
| GitHub项目地址 | https://github.com/NOS-AE/PersonalProject-Java |
阅读《构建之法》并提问
-
书中第二章第三小节介绍了PSP 的特点,其中一点是
PSP不依赖于考试,而主要靠工程师自己收集数据,然后分析,提高。
我有个这个问题:对于一开始自己十分不熟悉的项目或者技术,或者说未知领域的探索,这本身是一件复杂的事情,如同软件开发的“没有银弹”一样,预估耗时也没有公式可用,PSP的预估耗时一栏可能会出现很大偏差,偏差太大的话对于之后的总结分析会有什么样的影响,应该如何正确预估耗时。其中还说到了可以根据PSP数据提高自身,我查了资料,其中说到
- 稳定、成熟的PSP可以使你
- 估计和计划自己的工作
- 满足自己的承诺
- 拒绝不合理的承诺
- PSP提供了
- 一个得到证明的用于开发的基础框架
- 告诉你怎么来改进自己个体过程
- 持续改进工作效率、工作质量、工作可预测性的相关数据
但对于具体该怎么根据PSP来提高工程师自身能力还是不太懂
- 稳定、成熟的PSP可以使你
-
书中第三章第一节说到了团队对个人的期望
交流、收到做到、全力投入、积极讨论、理性地工作....
做项目是为了自身收益,组成团队是为了更快更好地完成一个好的项目,这门课程的组队项目开发总有人处于类似“临时的寄托或工作(Temporary Work)”,处于低动力、低技能的状态,这与团队对个人的期望相悖,不利于整个项目的完成,该如何正确应对。
-
书中在第三章第三节说专和精的关系的时候提到
有人说一个人就可以快速成长为一名全栈工程师,这让我想起街头卖艺的单人乐队,他们什么都会一些,可以很快地演奏一些曲子...
当我们谈论“全栈工程师”的时候,我们说的究竟是“交响乐作曲家写各个乐器的乐谱”,还是“演奏家满场奔走,操作各种乐器”呢?
在谈论“技能的反面”的时候,说其是“解决问题”。
我又了解到运维工程师在软件产品的整个生命周期中运维工程师都需要适时地参与并发挥不同的作用,因此运维工程师的工作内容和方向非常多,那么运维工程师究竟是什么都会一点的艺人还是谱写乐章的作曲者呢?运维需要对产品上线期间出现的各种问题进行解决,所以运维是属于“解决问题”也就是“技能的反面”吗,但是网上说运维可以说是越老越吃香,所以我又想到他是在将手上的技能不断打磨直至精通,而且对产品的各个方面都有所了解与掌控,属于“技能”吗。我觉得这个职业属于运用自己的技能去解决问题,属于技能的正面,虽然技能没有在某个领域十分深入,比如维护linux服务器,不需要对linux如何运行起来、源码等全面掌握,但运维工程师做好了本职工作——维护服务器运行,利用了维护服务器的知识,并随着不断地工作而越发熟练与精通。
-
书中第四章第五节说到了结对编程,可以做到边开发边复审,提高代码质量,运用得当还可以取得更高的投入产出比。
但是网上资料显示国内很少人实施结对编程,很大一部分取决于结对伙伴的性格、编码能力,以及来源于上司的压力
CEO:那个A和B最近走的很近,每天上班在一起很大声不知道说些什么,你要提醒下,对别的部门影响不好。
技术总监:那个是我们正在采用的结对编程的实验,可以大幅提高工作效率的。
CEO:哦,反正你注意点,不要出乱子。CEO:这个么简单个项目为什么要两个人去做,你不是说这个很简单么?
技术总监:不是的,我们现在在做敏捷,所有的项目都两个人一起做,这样效率高。
CEO:那个敏捷我不太懂哦,但是这么简单个项目要两个人一起搞,我觉得有点问题,你重新安排下。
技术总监边擦汗边说:好的,我们一定重新安排。结对编程适用范围看起来比书上说的更窄。我认为一个好的公司,应该充分考虑到员工的意见,将适合结对编程的人组合在一起,其他人则使用别的模式,使得效率最大化,或者实行少数服从多数的规则。
-
书上第三章第二节说到了过早泛化的问题。面对软件开发中日后各种变化以及新增的需求,或者是技术上的抽象需求,应该提早作出预测而在早期就作出大量抽象,还是应该面对新需求见招拆招,局部性地逐步拓展和抽象代码逻辑,如何控制“度”,使得不过度泛化/过早泛化
冷知识和故事
史上第一款电脑病毒,竟然是由防御技术专家Fred Cohen亲手设计出来的。他创造电脑病毒的目的仅仅是为了证明程序对电脑感染的可行性,从未希望借此对电脑造成任何危害。但这款程序却能够对电脑进行感染,并且能通过软盘等移动介质在不同计算机之间进行传播,因而命名为病毒。后来,他又创造出一种主动式电脑病毒,主要目的是帮助电脑用户找到未受感染可执行文件。https://zhuanlan.zhihu.com/p/59565938
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | ||
| Development | 开发 | 400 | 608 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 48 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 20 |
| Design | 具体设计 | 60 | 150 |
| Coding | 具体编码 | 180 | 280 |
| Code Review | 代码复审 | 20 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 40 | 40 |
| Test Report | 测试报告 | 10 | 20 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 440 | 648 |
解题思路
代码运行流程:
- 用字符读取流打开输入文件并读取数据
- 统计字符数
- 统计单词数
- 统计有效行数
- 统计出现最高频率单词top10
- 用字符输出流打开输出文件并输出数据
其中只需要查找API就能解决的有
-
用字符读取流打开输入文件并读取数据
为了效能,使用BufferedReader
-
用字符输出流打开输出文件并输出数据
为了效能,使用BufferedWriter
-
统计字符数
因为只需要考虑ascii码,每个字符长度都是1字节,读取数据后直接获取数据长度即可
其中需要思考的是:
- 统计单词数
- 按顺序读取全文
- 使用正则表达式匹配并统计单词
- 统计有效行数
- 按顺序读取全文
- 使用正则表达式匹配并统计空行
- 统计出现最高频率单词top10
- 按顺序读取全文
- 使用 1.统计单词数 中的正则匹配单词,用Map<String, Integer>存放单词个数,按value递减排序
代码规范
设计实现过程
Note: 只给出核心代码,完整代码见Github
-
主要方法的及其功能的设计
为了便于Lib使用者的使用,经过不断改动,设计了如下公有方法
/** * 构造Lib * @param inFile 需要从中读取数据的文件 * @param outFile 需要将计算的数据输出的文件 */ public Lib(String inFile, String outFile) /** * 相当于对下列所有processXXX的一次性调用 * 但只读取一次文件,提高效率 */ public void process() /** * 计算单词数 * 计算top10出现次数的单词 */ public void processWord() /** * 计算有效行数 */ public void processLineNum() /** * 计算字符数 */ public void processCharNum() /** * 将以上计算好的数据写入到输出文件中 */ public void output()以上设计的好处是,当使用者只需要某部分数据的时候,只需要调用对应的处理方法即可,另外output的公开使得对于数据的生成可以由调用者决定
我将具体的算法放在processXXX对应的processXXXInternal私有方法中,比如下面的统计单词
private void processWordInternal(String str) { // ... }该接收待处理的字符串的算法,不需要关心字符串从哪里来(字符串的获取放在了processXXX中)
以上设计的好处是,隐藏和封装处理(process)的算法细节,提高了公有API的稳定性,以及方便对算法本身进行测试,另外方便将processXXXInternal方法组合起来放到其它函数中,只读取一次文件,提高效率,比如process函数。
-
I/O
对于读取文件和读入文件,为了简化外界对WordCount的使用,故对外界隐藏I/O的细节
读文件
- 读入文件不需要外界控制时机,设为private
- 使用
BufferedReader,利用缓存的特性,提高读取效率 - 使用
StringBuilder提高性能,避免对需要多次拼接的字符串用+运算符导致多次构造String - 使用
BufferedReader的read函数逐字符读取
/** * @return the content of the file */ private String readFile() throws IOException { while ((c = reader.read()) != -1) { if (c != 13) { builder.append((char) c); } } return builder.toString(); }写文件
-
写文件即输出结果,输出格式固定,故直接硬编码写在方法内
-
使用
BufferedWriter提高写入效率
/** * write data to file in a hard-encoding format */ public void output() throws IOException { // 此处疯狂调用BufferedWriter的write方法,就不展示了 } -
处理单词
统计单词出现频率需要遍历所有单词,与统计单词数有重叠部分,故将统计单词数与统计单词出现频率合并在一个函数中
处理单词部分较为复杂,做流程图以辅助
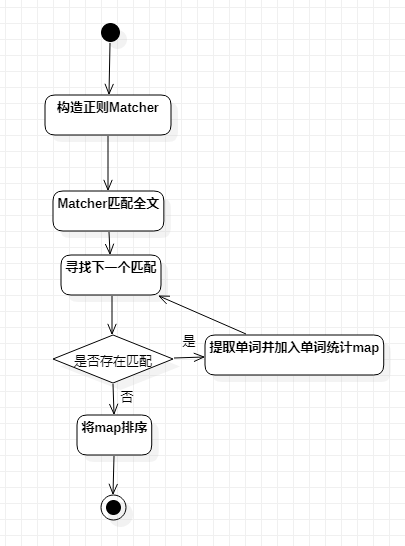
- Java正则API的组匹配:
find()返回true表明找到一处匹配,group(2)表示从正则提取单词,其中组匹配的第1组为整个匹配的字符串,剩余的组为括号对应的项,比如此处要提取的单词为第3组,故使用group(2) - 提取单词转为小写后,出现次数记录在map中
- 全部单词都提取完并存到map后,使用
Stream API将map排序
private void processWordInternal(String str) { while (matcher.find()) { // regex:(^|[^A-Za-z0-9])([A-Za-z]{4}[A-Za-z0-9]*) // 正则的组匹配,从符合正则表达式的串中提取单词 String word = matcher.group(2).toLowerCase(); Integer count = topWord.get(word); if (count == null) { count = 0; } topWord.put(word, count + 1); wordNum++; } // 将结果排序 topWord = topWord.entrySet().stream() .sorted( Map.Entry.<String, Integer>comparingByValue() .reversed() .thenComparing(Map.Entry.comparingByKey())) .limit(10) .collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new)); } - Java正则API的组匹配:
-
统计有效行数
注意到有效行指的是包含非空白字符的行,故也用了正则匹配
- 此处正则直接匹配有效行
private void processLineNumInternal(String str) throws IOException { // regex: (^| )\s*\S+ Matcher matcher = linePattern.matcher(str); while (matcher.find()) { lineNum++; } } -
统计字符数
将读取文件得到的字符串获取长度即可
private void processCharNumInternal(String str) { charNum = str.length(); }
性能改进
- I/O使用缓冲流,提高读写效率
- 对于不同类型数据的统计,只读取一次文件,提高效率
单元测试
单元测试使用JUnit5测试框架进行测试(步骤:构建测试对象 -> 测试函数正确性 -> 测试函数性能)
构建测试对象
构造Lib对象供测试使用,由于Lib在每次调用处理文件的时候都重新打开文件并初始化参数,故放在@BeforeAll中构造
private static Lib lib;
@BeforeAll
static void setUp() {
lib = new Lib(inFile, outFile);
}
测试函数正确性
-
测试统计字符数正确性,其中包括了可能出现的:字母、数字、空白字符(h,e]l8 )
- 使用
assertEquals测试函数比对正确行数与结果单行数
/** * 测试统计字符数 */ @Test void testProcessCharNum() throws IOException { assertEquals( testString.length() * loopCount, lib.getCharNum() ); } - 使用
-
测试统计单词数正确性,其中包含了可能出现的:开头不足四个英文字母的词语、被分隔符分割的词语( h,e]l8 wordne[ss1 fqsq1a )
- 使用
assertEquals测试函数比对正确单词数与结果单词数
/** * 测试统计单词数 */ @Test void testProcessWordNum() throws IOException { assertEquals( wordNum * loopCount, lib.getWordNum() ); } - 使用
-
测试统计词频前十正确性,其中设置了11个单词,每个单词的词频、字典顺序都不同
- 使用
assertEquals测试函数对比正确单词排序顺序与结果单词排序顺序
/** * 测试统计单词频率前10 */ @Test void testProcessWordRank() throws IOException { Map<String, Integer> topWord = lib.getTopWord(); topWord.forEach(new BiConsumer<String, Integer>() { int index = words.length - 1; @Override public void accept(String s, Integer integer) { assertEquals(index + 1, integer); assertEquals(words[index--], s); } }); } - 使用
-
测试统计单词时出现大写的情况
- 使用
assertEquals测试函数对比单词正确数目与结果数目
/** * 大小写测试 */ @Test void testProcessCapital() throws IOException { assertEquals( words.length * loopCount, lib.getWordNum() ); assertEquals(words.length, lib.getTopWord().keySet().size()); } - 使用
-
测试统计词频前十的排序正确性
- 使用
assertTrue测试函数对比单词字典顺序、出现频率
/** * 测试统计单词频率前10的排序正确性 */ @Test void testProcessWordRankSort() throws IOException { Map<String, Integer> topWord = lib.getTopWord(); topWord.forEach(new BiConsumer<String, Integer>() { int lastVal = 11; String lastKey = ""; @Override public void accept(String s, Integer integer) { assertTrue(lastVal >= integer); if (lastVal == integer) { assertTrue(lastKey.compareTo(s) < 0); } lastKey = s; lastVal = integer; } }); } - 使用
-
测试统计有效行数,其中包括只有空白字符的空行、无字符空行(h,e]l8 wordne[ss1 fqsq1a )
- 使用
assertEquals测试有效行数正确性
/** * 测试统计有效行数 */ @Test void testProcessLineNum() throws IOException { assertEquals( wordNum * loopCount, lib.getLineNum() ); } - 使用
测试函数性能
- 主要测试process处理全过程的用时(ms),比如
@Test
void testProcessPerformance0() throws IOException {
long time = System.currentTimeMillis();
lib.process();
lib.output();
System.out.println("use:" + (System.currentTimeMillis() - time) + "ms");
}
- 构造字符串为
h,e]l8 wordne[ss1 fqsq1a - 以下全部使用该写法,故下方省略代码
-
测试2w个6字符长单词的处理全过程运行时长(另外有其它不能组成单词的英文、数字、空白字符,下同)
用时
use:278ms运行结果文件
characters: 340000 words: 20000 lines: 20000 fqsq1a: 10000 wordne: 10000 -
测试20w个6字符长单词的处理全过程运行时长
用时
use:957ms运行结果
characters: 3400000 words: 200000 lines: 200000 fqsq1a: 100000 wordne: 100000 -
测试20w个12字符长单词的处理全过程运行时长
用时
use:1002ms运行结果
characters: 4600000 words: 200000 lines: 200000 fqsq1afqsq1a: 100000 wordnewordne: 100000 -
测试200w个6字符长单词的处理全过程运行时长
用时
use:3504ms运行结果
characters: 34000000 words: 2000000 lines: 2000000 fqsq1a: 1000000 wordne: 1000000
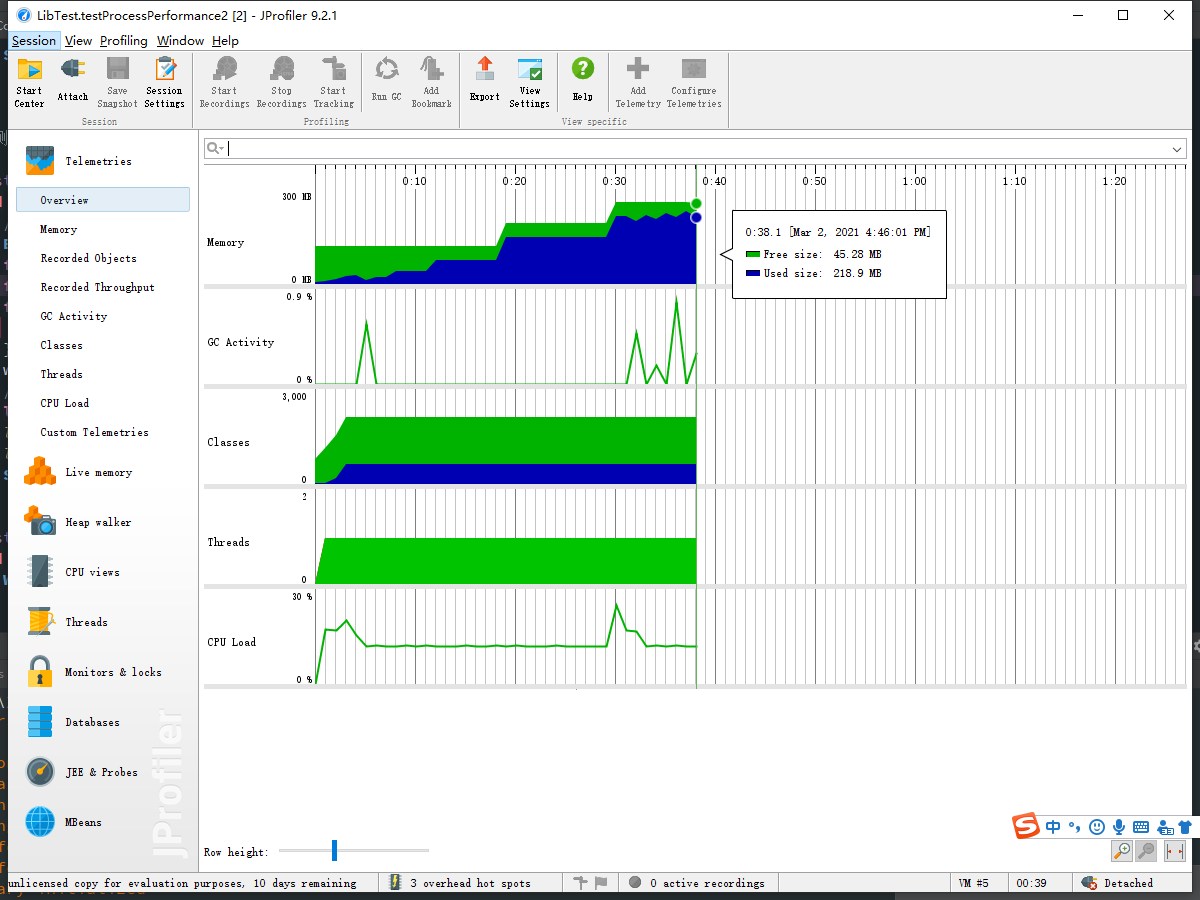
测试总结
200w行运行性能检测
覆盖率
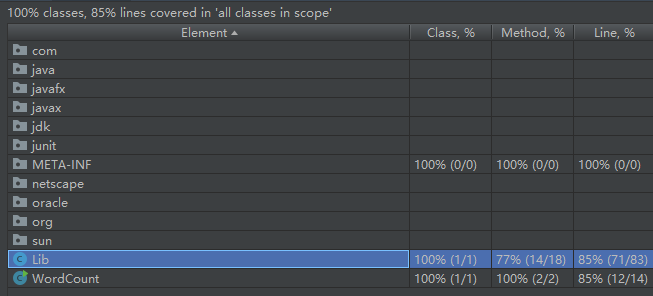
Lib类中没有测试到的方法/行
- 一些无需测试的getter/setter
- I/O异常catch块
异常处理
Lib出现并需要开发者处理的异常只有I/O异常
Lib对于文件的处理中可能出现的异常,采用先catch异常,正常关闭文件,再将异常抛出到外层,给开发者处理
心路历程与收获
收获
- 学会了如何使用JUnit进行单元测试
- 了解了白盒测试
- 进一步掌握了正则表达式处理的方法
- 了解并初步使用了语言新特性来更方便处理
Map的排序
历程
- 前期分析设计不得当,还有技术上对
readline函数不够熟悉,符合不了我的需求,导致后面重新修改了一次架构 - 因为开发中修改了架构,以及各种小地方修补,导致测试与开发的同步未能如约进行
- PSP的估计耗时与实践耗时偏差大
可改进的地方
- 前期应该花更多的时间进行架构设计,还要充分了解框架提供的API后再进行对应编码
- 应该增加更多测试来验证正确性