可以毫无讳言的说:算法能力是进入名企和获得高薪的最重要的能力。有一个著名的等式就是:程序设计语言 + 算法 = 软件。因此程序员要想提高自己的编程能力,写出优秀的软件,必须具备扎实的编程语言应用能力,灵活的算法设计能力,此外还应具备丰富的某个专业领域技能和经验(这一点对于非应届的朋友来说,非常重要。如果你之前没有搜索引擎开发经验,那么很少有搜索公司对你的简历感兴趣;如果你没有过安全软件开发,系统内核开发经验,那么也很少有安全公司对你的简历感兴趣),但归根结底还是算法设计。算法设计是计算机软件设计与开发的核心。编程语言与开发领域可以变化,你可以今天用C,明天用Java,你也可以今天做Web开发,明天做底层安全开发,但是算法设计以及数据结构却是相通的。
实际上,从开发经验来讲,程序 = 算法(包括数据结构)+ API调用 + “Hello world” + 字符串处理 + 内存管理(部分语言如java,python等无内存管理)。其中算法是程序的核心和灵魂。API是程序调用开发库中的接口,用来实现特定的功能和任务。一个程序不可能不调用API来完成功能。无论学哪个方面的编程,我们都可以从最简单的“Hello world”开始,学习它的开发环境搭建,程序结构框架,调试以及编译执行。剩下就是可能的大量字符串的处理和内存的操作,其中字符串处理会占程序代码中至少10%以上,这也是为什么很多企业(包括微软)会特别喜欢考查与字符串相关的算法题。
算法说白了,就是指程序员的编程能力,它是IT新手最需要训练和提高的地方,算法问题也是IT面试中的最具挑战性的问题,这直接反应了程序员的基本素质,因此答不好算法问题(一般就是在纸上或者黑板上甚至上机写代码解决问题),一般很难通过面试,那么离名企和高薪就会很遥远。算法能力(也就是编程能力)
1,确定函数名字与原型
一旦拿到有关算法的问题,那么就应该分析问题,找到对应的输入输出,从而确定出算法的函数原型。我们写算法,其实就是写一个或者若干个普通的函数(而不是main函数)。因此,需要分析出,应该传什么参数给函数(作为输入参数),函数处理完后,应该把什么数据作为结果返回(作为输出参数)。最后还要给函数取一个符合算法意义的名字,名字最好用英语表示,如果用拼音,会显得特别山寨的感觉。函数的命名方式与变量的命名方式都有相关的约定,比如匈牙利命名法,Linux命名法或者驼峰命名法等。
比如,有这么一个典型的算法问题:将一个字符串逆置,比如:”hello world”-->”dlrow olleh”
对于这道题,我们分析之后,应该知道,输入是一个普通的字符串,输出是将这个字符串逆置之后的字符串,因此,可以确定函数的原型:
void reverse_str(char *str);//str既是输入,也是输出 { } 或者 void reverse_str(char *str, size_t len)//str既是输入又是输出,len是字符串的长度 { }
很多初学者在这里容易犯的错误包括:只对字符串“hello world”进行了逆置而忽视了算法解决的是通用的一般性问题,或者把相关的代码直接写在了main()函数里。
此外,就是需要有模块化的思想。一个函数只单独完成一个单一的功能,函数的代码行数一般很少超过100行,加上注释不会超过300行。
因此,要把那些频繁使用而功能又比较单一的代码放在一个独立的函数里。不要在一个函数里完成N个功能,这不利于调试和维护,也和模块化是相背离的。
2,严进宽出
确定好了函数的原型之后,紧接着在完成这个函数的功能一开始的地方,就需要严格判断函数输入参数的合法性,我们称之为:严进宽出。具体点说,就是要判断:
a,函数参数中的指针是否为NULL
b,函数参数中缓存的长度是否在合理范围
c,甚至还要利用C++中的RTTI对参数的类型进行检查。
以上a,b,c三点非常的重要。
比如同样对于第1点里的函数原型,那么我们就需要作出如下的判断:
void reverse_str(char *str, size_t len) { /*首先判断str指针是否为NULL或者len是否为0和1,这些都是特殊情况或者非法输入,因此要严格检查,严进宽出。*/ if(str== NULL || *str=='�'|| len==0 || len==1) { return; } //程序如果执行到这里,那么参数检测就完成了并合法了。因此可以继续完成相应的功能了。 ...... }
严进宽出是写程序的一个非常好的习惯,可以避免程序在运行中出错,甚至避免各种严重漏洞的产生。比如曾经十分严重的SSL协议中的心脏流血漏洞,就是因为服务端程序在处理的时候,没有验证来自客户端对应的缓存长度的有效性,而造成了该漏洞的产生。同样,对于号称漏洞核弹的微软CVE-2017-0290漏洞,也是因为在扫描引擎MsMpEng的NScript模块中没有对输入的参数类型进行检查就默认当做字符串来处理造成的。
此外,在函数内部定义的局部变量,都应该进行初始化,因为未初始化的变量,包含的都是一些没有意义的随机值,初始化可以防止在使用过程中使用了垃圾值的变量,影响程序的判断,尤其是指针,可以防止野指针破坏程序中的数据。常见数据类型的初始化包括:
1 int x = 0; 2 char *pstr = NULL; 3 Bool bOpened = FALSE; 4 char Name[100] = {0}; 5 char *szName = “hello world”; 6 char szName[] = “hello world”; 7 char szName[100] = “hello world”; 8 UNICODE_STRING ustrName = {0}; 9 CString szName = _T(“”); 10 memset(buffer, 0, 1024);
3,边界考虑
边界考虑就是要考虑程序中各种各样的特殊情况,而不是只考虑其中的一种情况。我们在写算法的时候,经常会忘记多种情况的周全考虑,而忽略了很多特殊的情况,对程序的健壮性带来影响。
1.边界条件是指软件计划的操作界限所在的边缘条件。数据类型:数值、字符、位置、数量、速度、地址、尺寸等,都会包含确定的边界。应考虑的特征:第一个/最后一个、开始/完成、空/满、最慢/最快、相邻/最远、最小值/最大值、超过/在内、最短/最长、最早/最迟、最高/最低。这些都是可能出现的边界条件。边界条件测试通常是对最大值简单加1或者很小的数和对最小值减少1或者很小的数,例如:
l 第一个减1/最后一个加1;
l 开始减1/完成加1;
l 空了再减/满了再加;
l 慢上加慢/快上加快;
l 最大数加1/最小数减1;
l 最小值减1/最大值加1;
l 刚好超过/刚好在内;
l 短了再短/长了再长;
l 早了更早/晚了更晚;
l 最高加1/最低减1。
另一些该注意的输入:默认,空白,空值,零值和无;非法,错误,不正确和垃圾数据。根据边界来选择等价分配中包含的数据。然而,仅仅测试边界线上的数据点往往不够充分。提出边界条件时,一定要测试临近边界的合法数据,即测试最后一个可能合法的数据,以及刚超过边界的非法数据。
2.默认值测试(默认、空白、空值、零值和无)
好的软件会处理这种情况,常用的方法:一是将输入内容默认为合法边界内的最小值,或者合法区间内某个合理值;二是返回错误提示信息。
这些值在软件中通常需要进行特殊处理。因此应当建立单独的等价区间。在这种默认下,如果用户输入0或-1作为非法值,就可以执行不同的软件处理过程。
3.破坏测试(非法、错误、不正确和垃圾数据)
数据测试的这一类型是失败测试的对象。这类测试没有实际规则,只是设法破坏软件。不按软件的要求行事,发挥创造力吧。
举一个例子:实现C库中的memmove函数。
很多程序员可能会很快写出如下程序:
void memcpy(void *pDst,const void *pSrc, size_t size) { assert(pDst != NULL); assert(pSrc != NULL); char *pstrSrc= (char *)pSrc ; char *pstrDst = (char *)pDst ; /* 从起始部正向拷贝 */ while(size--) *pstrDst++ = *pstrSrc++; }
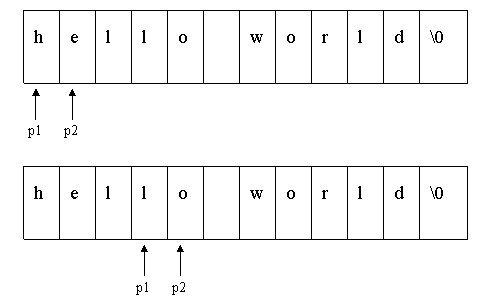
但是,这里忽略了一个很重要的情况就是:pDst和pSrc指定的内存有可能是重叠的。如果按照这样拷贝的话,那么如果:
(pSrc<pDst) && ((char*)pSrc+size > pDst)
那么,按照上面的程序代码拷贝,将会把pSrc尾巴部分的数据覆盖污染了。
因此,必须清楚的考虑pSrc和pDst二者之间的关系,采取不同的算法,实际上,pSrc和pDst的位置关系有如下图4种情况,其中第2种情况,需要特殊处理。

如上图的位置关系所示,在第2种位置中,也就是当(pSrc<pDst) && ((char*)pSrc+size > pDst)时,从前往后拷会有问题。必须从后往前面拷贝:
1 void memcpy(void *pDst,const void *pSrc, size_t size) 2 { 3 assert(pDst != NULL); 4 assert(pSrc != NULL); 5 /* pSrc与pDst共享同一块内存区域 */ 6 if((pSrc<pDst) && ((char*)pSrc+size > pDst)) 7 { 8 char *pstrSrc= (char *)pSrc + size -1; 9 char *pstrDst = (char *)pDst + size -1; 10 / * 从尾部逆向拷贝 */ 11 while(size--) 12 *pstrDst -- = *pstrSrc--; 13 } 14 else 15 { 16 char *pstrSrc= (char *)pSrc ; 17 char *pstrDst = (char *)pDst ; 18 /* 从起始部正向拷贝 */ 19 while(size--) 20 *pstrDst++ = *pstrSrc++; 21 } 22 }
4,出错处理
出错处理,是指当代码在执行过程中,如果发生了异常或者错误,就必须要处理,否则程序就无法继续执行了,如果强制继续执行,往往可能会导致程序或者系统崩溃。
比如我们在打开文件的时候,如果文件不存在或者打开失败了;在分配内存的时候,返回内存为NULL,这些情况都需要及时处理。一般处理程序错误或者异常的方法有goto
err或者try_except等方式。
出错处理的方式方式很多,也很灵活。只要不遗漏对错误的处理就行。现在介绍两种错误处理方式:
1) goto error方式
语句goto是大家不大喜欢使用的,也是程序设计专家建议不要使用的一句话。因此goto语句似乎就要退出历史的舞台。但幸好它找到了一个用武之地,那就是用goto error方式来处理出错。下面是一个例子:
1 NTSTATUS QueryObjectName(HANDLE h) 2 { 3 int ret; 4 NTSTATUS st; 5 char *str = "Hello, how are u?"; 6 char *pstr = (char *)malloc(256); 7 8 if (pstr == NULL) 9 { 10 printf("No more memory "); 11 goto Error; 12 } 13 int len = strlen(str)>255?255:strlen(str); 14 strncpy(pstr, str, len); 15 pstr[len+1] = '�'; 16 17 char *namebuf = (char *)malloc(1024); 18 if (buf == NULL) 19 { 20 printf("No more memory "); 21 goto Error; 22 } 23 st = NtQueryObject(h, FileNameInformation, namebuf, ret, NULL); 24 if (!NT_SUCCESS(st)) 25 { 26 printf("No more memory "); 27 goto Error; 28 } 29 ... 30 Error: 31 if (buf) 32 { 33 free(buf); 34 } 35 if (pstr) 36 { 37 free(pstr); 38 } 39 return st; 40 }
goto error方式把错误进行了集中处理,防止了在分支复杂的程序中错误情况的遗漏。
2) SHE:__try__leave__exception方式
SEH( structured exception handling ),即结构化异常处理方式,它是Windows系统独有的异常处理模型,主要由try-except语句来完成,与标准的try-catch相似。C++异常处理模型使用catch关键字来定义异常处理模块,而SEH是采用except关键字来定义;catch关键字后面像接受一个函数参数一样,可以是各种类型的异常数据对象,except关键字则不同,它后面跟的是一个表达式。
1 NTSTATUS QueryObjectName(HANDLE h) 2 { 3 int ret; 4 NTSTATUS st; 5 __try 6 { 7 char *str = "Hello, how are u?"; 8 char *pstr = (char *)malloc(256); 9 10 if (pstr == NULL) 11 { 12 printf("No more memory "); 13 __leave; 14 } 15 int len = strlen(str)>256?256:strlen(str); 16 strncpy(pstr, str, len); 17 pstr[strlen(str)] = '�'; 18 19 char *namebuf = (char *)malloc(1024); 20 if (buf == NULL) 21 { 22 printf("No more memory "); 23 __leave; 24 } 25 st = NtQueryObject(h, FileNameInformation, namebuf, ret, NULL); 26 if (!NT_SUCCESS(st)) 27 { 28 printf("NtQueryObject failed "); 29 __leave; 30 } 31 } 32 __except(EXCEPTION_EXECUTE_HANDLER) 33 { 34 //获得异常代码 35 st = GetExceptionCode(); 36 } 37 if (buf) 38 { 39 free(buf); 40 } 41 if (pstr) 42 { 43 free(pstr); 44 } 45 return st; 46 }
5,性能优化(时间复杂度,空间复杂度)
大家有时候去参加面试,自我感觉良好,面试官出的算法题,自己感觉也做出来了,也做对了,可为什么面试结束后,迟迟等不来Offer呢?那就很可能是因为你的算法题虽然做出来了,但不是最优的。
总的来说,衡量算法的优劣有2种标准:时间复杂度和空间复杂度。简单的来说,所谓时间复杂度,就是嵌套的循环越少越好,比如一层循环优于二层循环,面试中一般很少有三层循环的算法;而所谓空间复杂度,就是尽量不要调用malloc或者new来分配额外的内存。复杂度可以用O()来表示,它们之间的效率关系为:
O(1)>logn>O(n)>O(nlogn)>O(n²)>O(2^n)
对于第1点中的字符串逆置的问题,有如下2种解决方法:
//算法1:直接基于str所在内存进行逆置 void reverse_str(char* str, size_t len) { if (NULL == str || '�' == *str || 0==len || 1==len) { return; } char *p1=str; char *p2=str+len-1; while(p1<p2) { char c = *p1; *p1 = *p2; *p2 = c; p1++; p2--; } } //算法2,分配一个额外的内存,把字符串从后往前拷贝到内存中 char *reverse_str(char* str, size_t len) { if (NULL == str || '�' == *str || 0==len || 1==len) { return; } char *buf=malloc(len+1); char *p2=str +len-1; char *p1=buf; if(buff == NULL) { return NULL; } memset(buf, 0,len+1); while(len--) { *p1++=*p2--; } return buf; }
2种解法都能够完成把字符串逆置的任务。但是,第二种算法,额外分配了内存(复杂度为O(n)),空间复杂度上第一种占据了优势。
空间复杂度很好理解。而时间复杂度,想要容易的写出O(n)或者O(1)的算法,就需要仔细思考问题和设计算法了,并且还应该学习一些常见的算法技巧。比如:2个指针跑步,比如hash算法,比如递归等,详见下面的方法总结。
思考题:用尽量高效的方法(比如O(1))来删除单向非循环链表中的某个结点。
原型:bool delete_node(node *&head, node *p)
6,循环的掌握
一个再复杂的算法程序,都是由循环,条件,顺序三种语句构成的(switch语句也可以转化为条件语句)。而这三种语句中,循环语句的使用是其中的关键。循环语句用来遍历和操作对应的数据结构,在遍历的过程中,完成对数据的处理和问题的解决。前几节中,几乎每个算法都用到了循环语句。以循环语句为核心,循环语句把其他语句联系起来。因此,算法中,最重要的地方就是对循环的熟练掌握与使用。
下面把常用的各种数据结构的循环语句列出,方便大家在编程的时候使用:
1.数组 for (int i = 0; i < n; i++) { printf(“%d ”, a[i]); } 2.字符串 while (*str !=’0’) { str++; } 3.链表 while (p) { p = p->next; } 4.栈空/栈满/队空/队满 while(栈非空) { 出栈; 操作出栈元素 } 5.指针大小比较 while (pStart < pEnd) { pStart++; } 6.数为正 while (size--) { } do { }while(size--) 7.反复循环直到条件成熟 while(1) { if (something is true) break; }
熟练各种循环语句的写法,为实现各种复杂的算法奠定了基础。因此,要在各种循环语句上下功夫,达到熟练书写,灵活运用的程度。
7,递归的应用
对于一些复杂的算法问题,还可以通过递归的思想来解决。有的问题,用传统的方法来解决,显得很复杂。这个时候,可以考虑是不是可以用递归来解决。因为用递归的思想解决问题,既简单,又清晰,往往让看似复杂的问题得到简单解决的可能。
对于树的问题,几乎都可以考虑用递归的方法去实现,按照递归的方法,首先分析了这个问题最简单的情况(即递归的出口),然后再对复杂的情况利用递归方法调用它自身。
1 题目:用一条语句,不声明临时变量,实现strlen来计算一个字符串的长度。 2 如strlen(“hello world”)=11 3 size_t strlen (const char * str )//常规方法 4 { 5 const char *eos = str; 6 while( *eos++ ) ; 7 return( eos - str - 1 ); 8 } 9 10 size_t strlen(const char *str)//递归方法 11 { 12 return (str==NULL || *str==’0’)?0:1+strlen(str+1); 13 } 14 15 16 题目:将一个字符串逆置。 17 比如:”hello world”-->”dlrow olleh” 18 void reverse_str(char* str, unsigned int len)//常规方法 19 { 20 if (NULL == str) 21 { 22 return; 23 } 24 char *p1=str; 25 char *p2=str+len-1; 26 while(p1<p2) 27 { 28 char c = *p1; 29 *p1 = *p2; 30 *p2 = c; 31 p1++; 32 p2--; 33 } 34 } 35 36 void reverse_str(char *str, size_t len)//递归方法 37 { 38 if(len==0 || len==1 || str == NULL || *str=='�') 39 { 40 return; 41 } 42 43 char tmp = str[0]; 44 str[0]=str[len-1]; 45 str[len-1]=tmp; 46 47 reverse_str(str+1, len-2); 48 49 }
递归算法的关键是找到递归的出口和递归公式。
8. 2个指针跑步
2个指针跑步法,是麦洛克菲在算法教学过程中总结的一个很好的编程方法。就是在算法实现过程中,我们可以定义2个(有时候甚至是3个或者多个)指针,一前一后同向或者相向而行,同时遍历对应的数据结构(如数组,链表,字符串等),在遍历过程中解决对应的问题。如果我们把循环比喻成算法问题中的导演,那么2个指针就是算法中的男女主角,对问题的解决起着重要的作用。在大量的名企面试题中,都可以使用该方法来解决并降低算法的复杂度。下面的例子详细的描述了这个方法的使用方法:
题目1:计算一个链表的中间节点。
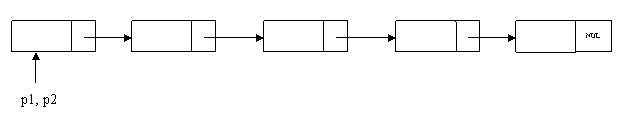
思路:定义2个指针,一个跑2步,一个跑1步,当跑2步的到链表终点,跑1步的正好到达中间结点
node * find_list_middle_node(node * list) { if(list == NULL || list->next == NULL) { return list; } node *p1 = list; node *p2 = list; while(p1&&p2&&p2->next) { p1=p1->next; p2=p2->next->next; } if(p2->next==NULL || p2==NULL) return p1; }
题目2:判断一个单向链表是否存在循环。
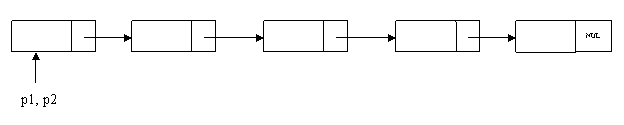
思路:定义2个指针,一个指针跑一步,一个指针跑2步;如果2个指针相遇,就存在循环,否则不存在循环。
int find_loop(node *head) { node *p = NULL; node *q = NULL; if (head == NULL) return 0; p = head; q = head->next; while (p!=NULL && q!=NULL&&q->next!=NULL&&p!=q) { p = p->next; q = q->next->next } if (p==q) return 1; else return 0; }
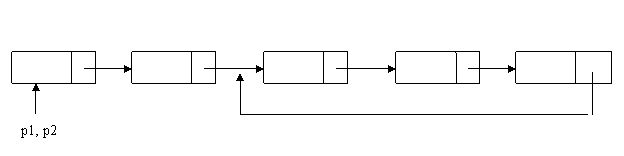
题目3:从一个字符串中删除某一个特定的字符。
如:”hello world”,’o’-->”hell wrld”
思路:定义2个指针,一个是读指针,一个是写指针。读指针从头到尾扫描字符串,遇到不需要删除的字符,传递给写指针保存对应的字符,如果遇到要删除的字符直接忽略。
char* del_char(char *str,char ch) { char *p1=str,*p2=str; if(NULL==str) { return NULL; } while(*p2!='�') { if(*p2!=ch) { *p1++=*p2++; } else { p2++; } } *p1='�'; return str; }
9. Hash算法
Hash算法一般是用一个hash数组来记录一个key对应的有无或者统计对应的个数,用key作为hash数组的下标,而下标对应的值用来表示该key的存在与否以及统计对应的个数。
例1:请编写一个高效率的函数来找出字符串中的第一个无重复字符。例如,"total"中的第一个无重复字符上一"o"
char find_first_single_char(const char *str) { int tmp[256]={0};//hash数组 char *s= (char *)str; while(*s!='�') { tmp[*s]++; s++; } s=(char*)str; while(*s!='�') { if(tmp[*s]==1) { return *s; } s++; } return '�'; }
找出一系列整数(都小于65536)中存在的重复数字。 #define MAXMUM 65536 void find_repeated_number(int a[], in n) { int tmp[MAXMUM];//hash数组 int i; for (i = 0; i < MAXMUM; i++) { tmp[i] = 0; } for (i = 0; i < n; i ++) { tmp[a[i]]++; } for (i = 0; i < MAXMUM; i++) { if (tmp[i]>1) printf(“%d:%d”, i, tmp[i]); } }