第七章:查找
7.1折半查找
折半查找又叫二分查找,首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
折半查找过程演示,如下图所示,表中元素按升序排列:

假如要查找一个数据253。那么首先查看表中中间位置(0+8)/2即位置为4的元素:53。因为253比53要大,所以丢弃表中0到4的子表数据,剩下5到8的字表数据。然后再计算5到8的子表的中间位置(5+8)/2即6的位置的元素:101。因为253比101的数据要大,所以丢掉5到6子表中的元素,剩下7到8子表的元素。然后找到7到8中间位置(7+8)/2即7所在位置的元素:253,二者相等,那么查找成功,即所在位置为7。
假如要查找一个为3的数据。那么首先查看表中中间位置(0+8)/2即位置为4的元素:53。因为3比53要小,所以丢掉4到8之间的子表元素,保留0到3之间的子表元素。然后在计算0到3之间的中间元素(0+3)/2即1所在位置的元素:9。因为3比9要小,所以丢掉1到3之间子表元素,留下0位置的元素1,但3比1要大。所以整个表查完,没有找到该元素,查找失败。
下面是折半查找算法:
//a为存放数据的有序表,n为数据元素个数,k为要查找的元素
int BinSearch(int a[], int n, int k)
{
int low, high, mid, find, i;
find = 0;
low = 0;
high = n-1;
while (low <= high && !find)
{
mid = (low + high)/2;
if (a[mid] < k)
low = mid + 1;
else if (a[mid] > k)
high = mid - 1;
else
{
i = mid;
find = 1;
}
}
if (!find)
i = -1;
return i;
}
递归版本:
int IterBiSearch(int data[], const int x, int beg, int last)
{
int mid = -1;
mid = (beg + last) / 2;
if (x == data[mid])
{
return mid;
}
else if (x < data[mid])
{
return IterBiSearch(data, x, beg, mid - 1);
}
else if (x > data[mid])
{
return IterBiSearch(data, x, mid + 1, last);
}
return -1;
}
int BinSearch(int a[], int n, int k)
{
return IterBiSearch(a,k,0,n-1);
}
注意:折半查找必须满足两个条件:一,元素必须是连续存储;二,元素必须有序。时间复杂度:O(logn)
7.2Hash查找
Hash表用于存放key-value数据。比如一个学生的成绩,那么学生的学号可以当做key,成绩当做value,存放与hash表中。
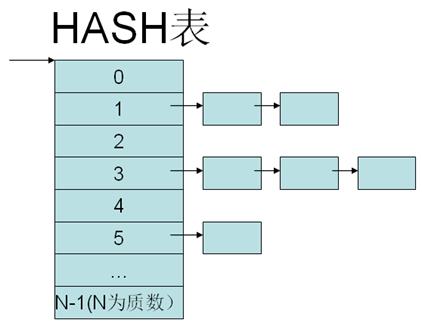
Hash查找必须提供一个Hash函数,用于通过Key来计算数据存放在hash表中的位置。一般hash函数可以设计为key%N,其中N为hash表中元素的个数(一般为质数)。假如HASH表的大小为N,那么Hash函数为:
Hash(key)=key%N
当对于不同的两个key,计算出来的hash值可能相同,在相同的时候,就叫做hash冲突。解决hash冲突的方法不止一种,比如通过链式法解决,即将所有含有相同hash值的数据存放在同一个链表中,而将链表的头结点存放在HASH表中。
所谓hash查找,就是通过对应的key,按照hash函数,计算出数据在hash表中的位置。Hash查找的复杂度为O(1),所以具有较高的查找效率。
请编写一个高效率的函数来找出字符串中的第一个无重复字符。例如,"total"中的第一个无重复字符是’o’。
int hash(char ch)
{
return ch;
}
char find_first_norepeat_ch(const char *str)
{
int hasharr[256]={0};
char *s=(char *)str;
while(*s)
{
hasharr[hash(*s)]++;
s++;
}
s=(char *)str;
while(*s)
{
if(hasharr[*s]==1)
{
return *s;
}
s++;
}
return '�';
}
7.3二叉搜索树查找
在第五章《树》,我们学习了什么叫做二叉排序树,即二叉搜索树。很多时候,我们也可以将数据存放在平衡二叉排序树里。那么如何使用它来进行查找数据呢?
struct _node
{
int data;
struct _node *left;
struct _node *right;
} node, btree;
btree *search(btree *b, int x)
{
if (b == NULL)
{
return NULL;
}
else
{
if (b->data == x)
{
return b;
}
else if (x < b->data)
{
return (search(b->left));
}
else
{
return (search(b->right));
}
}
}
平衡二叉排序树的查找复杂度为O(logn),因此也具有较高的查找效率。