url: https://arxiv.org/pdf/1312.6184.pdf
year: NIPS2014
浅网络学习深网络的函数表示, 训练方法就是使用深网络的 logits(softmax input) 作为标签来训练浅网络
简介
目前,深层神经网络在语音识别和计算机视觉等问题上的研究上达到了 SOTA(state of the art). 本文通过实验证明, 浅层前馈网络可以学习到以前只有深层网络可以学习到的复杂函数, 达到以前只有深网模型才能达到的精度。此外,在某些情况下,浅网可以使用与原始深层模型相同数量的参数来学习这些深层函数。
当你拥有一百万的带标签的训练数据, 当您在这些数据上训练一个带有一个完全连接的前馈隐藏层的浅层神经网络时,在测试集上, 您可以获得86%的准确度。当您训练更深层的神经网络时,如在相同数据上由卷积层,池化层和三个完全连接的前馈层组成,您可以在同一测试集上获得91%的准确度。
性能提升的来源是什么?
a)dnn具有更多参数;
b)dnn可以在给定相同数量的参数的情况下学习更复杂的函数,
c)dnn具有更好的归纳偏差,因此学习更有趣/有用的功能(例如,因为深网更深,它学习层次表示[5]);
d)非卷积网络很难学习到卷积网络可以学习到的特征表示
e)相较于比浅层架构, 当前的优化算法和正则化方法在深层架构中更加有效
f)以上全部或部分内容;
g)以上都不是?
理论上来说, 只要以sigmoid为激活函数的网络足够大, 那么它就可以近似任何决策边界. 然而实验表明, 浅层模型很难达到深层模型所能达到性能.
文中实验表明,即浅层模型能够学习与dnn相同的函数,并且在某些情况下, 只需要与dnn相同数量的参数。
实验方法
实验方法
首先, 训练一个性能良好的的dnn,然后训练浅模型来模拟dnn, 我们可以使得训练的浅层网络与某些深层模型一样准确. 尽管浅层网络在标注数据上直接训练时是没法达到这样的准确度的。这说明, 具有与dnn相同数量的参数的浅层网络可以高保真地学习到dnn的特征表示, 这表明了由该深网学习的函数实际上并非只有比较深的网络才能学习的到。
实验设置
深层 CNN ensemble 模型用于 CIFAR-10 用于生成 logits(before the softmax activation.), 然后使用老师的 logits 作为回归目标来训练学生网络, 从而完成对老师网络的模仿. 通过直接在logits上训练学生模型,学生可以更好地学习老师学到的内部模型,而不会丢失掉因由于softmax的竞争性特性会损失掉输入的信息.
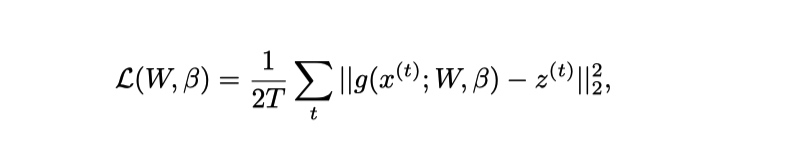 

论文中, 选择了不同的 loss 函数用于监督学生和老师的后验分布, 如 KL 散度, L2 距离, 实验表明 L2 距离表现更好.
实验细节
我们发现,通过减去平均值并将训练集中每次训练的标准差除以标准偏差,可以在训练期间略微改善L2损失,但归一化对于获得优秀学生模仿模型并不重要。
实验结果
| 术语 | 解释 |
|---|---|
| DNN | Deep Neural Net, 3 层 FC 层, 每层包含 2000 ReLU |
| CNN | Conv->Pooling-> 3 层 FC 层, 每层包含 2000 ReLU |
| ECNN | Ensemble of 9 CNN models |
| SNN | Shallow Neural Net Only Consisting of FC w/o Conv, Pooling |
| SNN-8k, SNN-50k, SNN-400k | SNN with 8000, 50,000, and 400,000 hidden units |
TIMIT Phoneme Recognition
语音识别任务
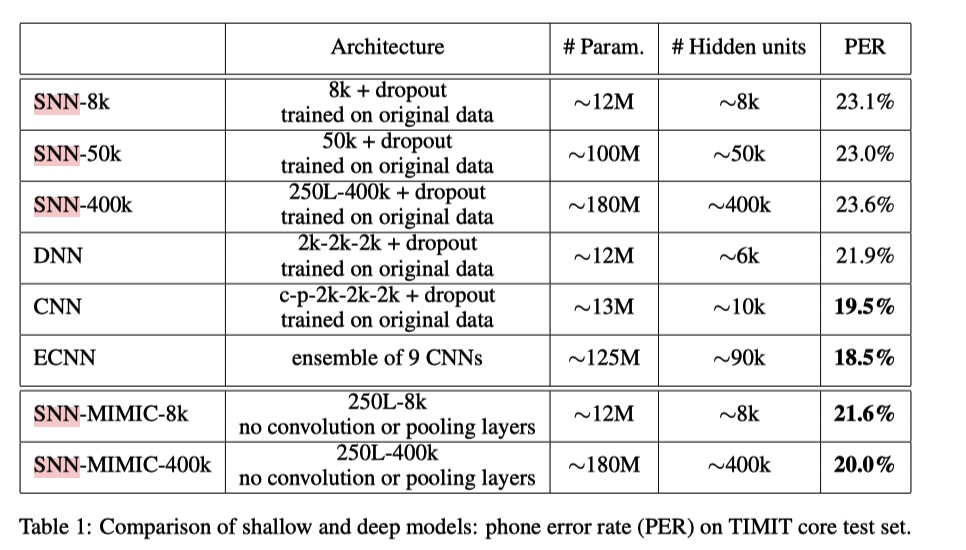 

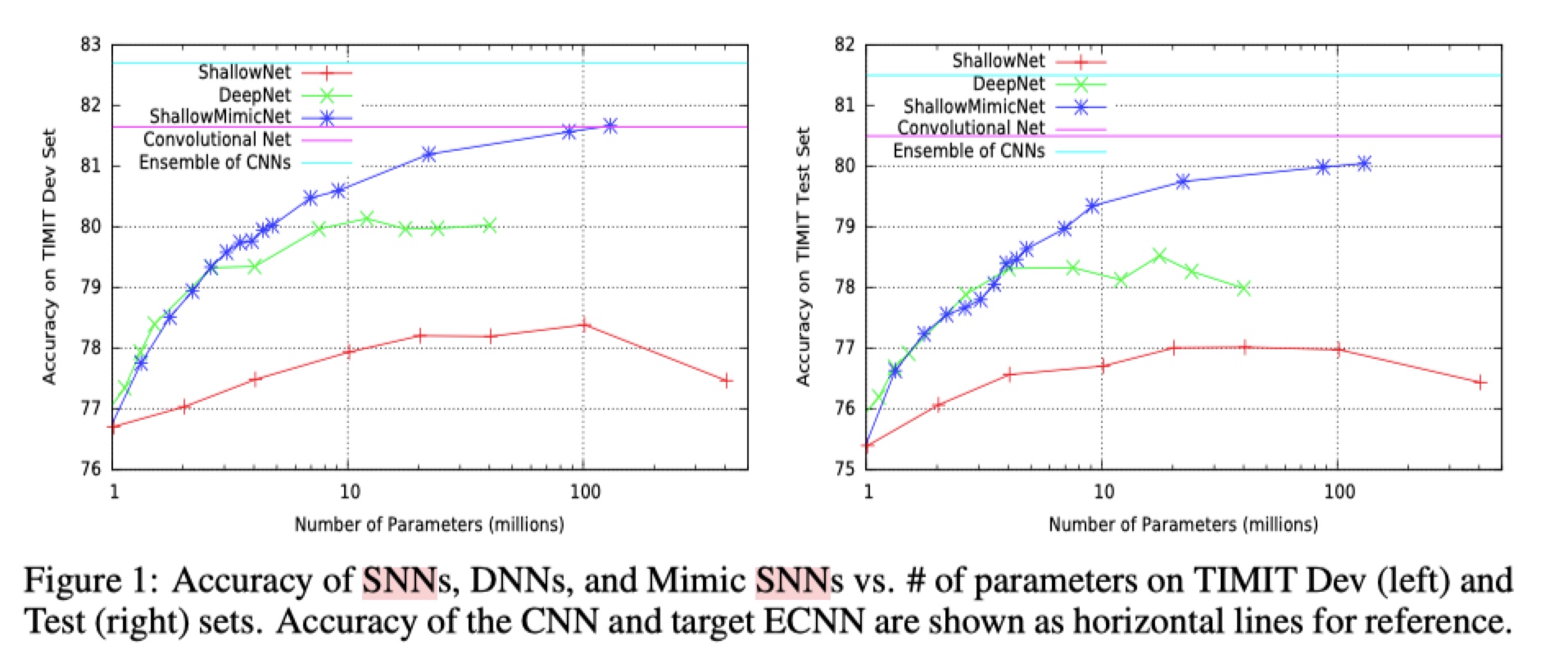 

如上图所示,
- 相对于深层模型, 浅层模型更加容易过拟合(模型容量小, 就拼命记下非泛化特征, 从而拟合训练集?)
- 学生模型性能好, 且不容易过拟合
- 学生模型的性能不会超过老师(ECNN)的性能, 不过可以看出可以比较接近 ECNN 中单个 CNN 的性能.
Object Recognition: CIFAR-10
在初步实验中,我们观察到非卷积网在CIFAR-10上表现不佳,无论它们的深度如何。
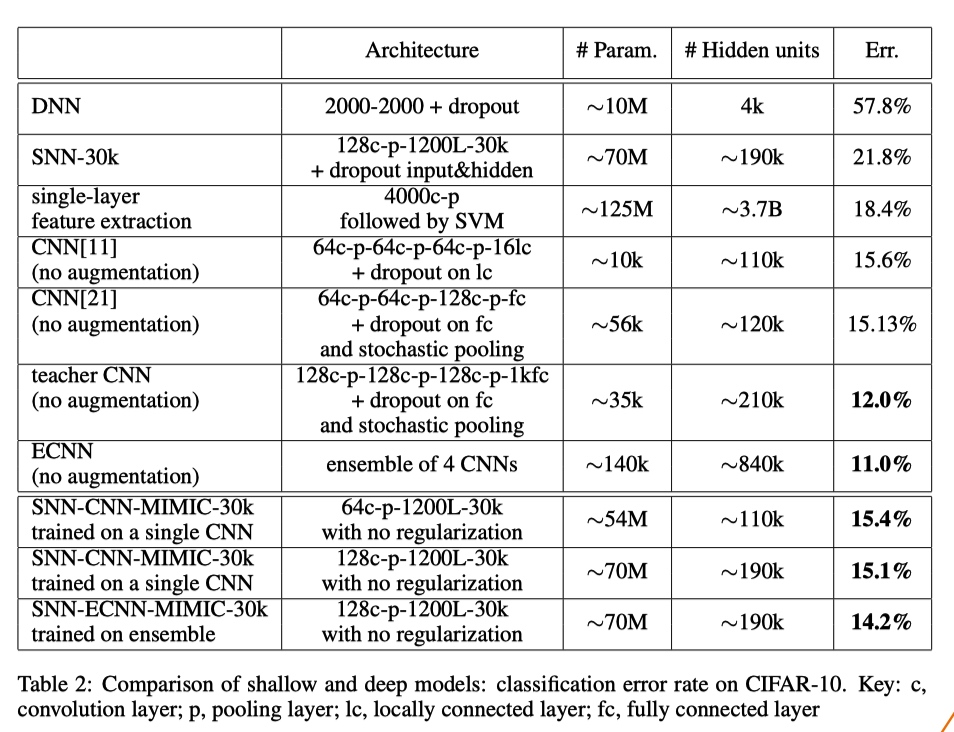 

如上图所示,
- 非卷积网络无论深浅, 在计算机视觉任务上表现都不佳, CNN 在计算机视觉任务上的优势
- 老师越好, 学生模仿的越好
实验分析
为什么通过模仿老师模型学习的学生模型比原始标签上的训练更准确
令人惊讶的是,在其他模型预测的目标上训练的模型可能比在原始标签上训练的模型更准确。造成这种情况的原因有多种:
- 如果某些标签有错误,教师模型可能会剔除其中一些错误(校正数据),从而使学生模型更容易学习。
- 由于同样的原因,过滤目标可以冲走复杂性,如果p(y | X)中存在复杂区域,考虑到特征和样本密度,难以学习,教师可以为学生提供更简单,软的标签。
- 从原始的硬0/1标签中学习可能比从教师的条件概率中学习更困难:在TIMIT每个训练样例中,183个输出中只有一个非零,但模拟模型看到大多数输出的非零目标教师模型的不确定性为学生模型提供了更多信息。通过对logits的训练进一步增强了这种好处。
- 原始的学习目标可以部分依赖于输入中不可得到的特征,但是学生模型的学习目标仅仅依赖于输入的特征, 这是由于由老师模型生成的学习目标是可得到的实际输入(available inputs)的函数。 对于未知特征的依赖通过老师网络所剔除.
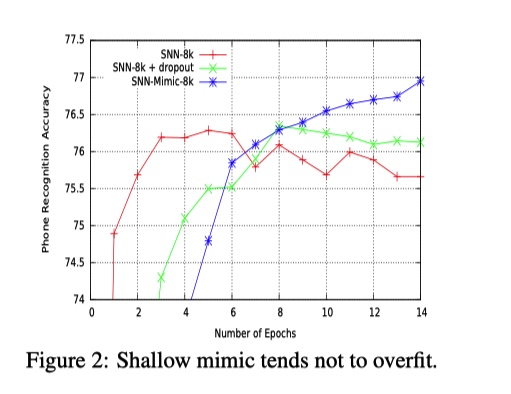 

上述机制可以看成一种正则化的形式,有助于防止学生模型中的过度拟合。通常,在原始目标上训练的浅模型比深度模型更容易过拟合(why?)---即使使用 dropout, 浅层模型在还未学习到深层模型学习到的准确特征之前就先过拟合了(见Figure2). 模型压缩似乎是一种有效减少这种差距的正则化形式。如果我们对浅层模型有更有效的正则化方法,那么浅层和深层模型之间的一些性能差距可能已经消失。
浅层模型的容量和表征能力
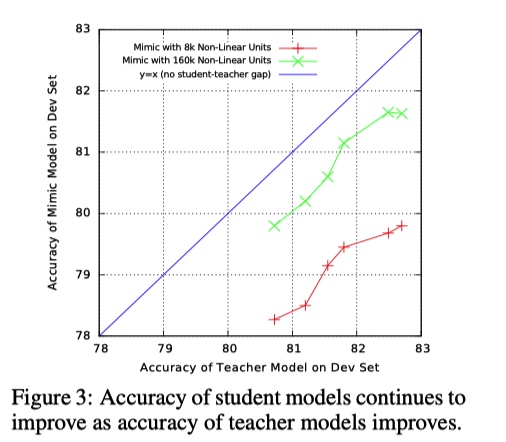 

如上图所示, x轴显示教师模型的准确性,y轴是模拟模型的准确性。SNN-MIMIC-160K的参数是SNN-MIMIC-8k的10倍
- 与对角线平行的线表明,教师模型的准确性的提高产生了学生模型的准确性的类似增加。尽管数据并不完全落在对角线上,但有充分的证据表明学生模型的准确性随着教师模型精确度的提高而持续增加.
- 学生模型不会运行比老师更好。虽然尺寸不同,两个模型之间以及与老师模型之间存在一致的性能差距,较小的浅模型最终能够通过向更好的教师学习而获得与较大的浅网相当的性能,并且两种模型的准确性仍在继续随着教师准确度的提高而增高.
- SNN-MIMIC-8k总是比SNN-MIMIC-160K表现更差,SNN-MIMIC-160K的参数是SNN-MIMIC-8k的10倍。这表明如果有更准确的教师和/或更多未标记的数据可用。具有与深模型相当的许多参数的浅模型可能能够学习更准确的函数。
思考
这里有意思的一点就是, 这里提到如果有更多与原始训练集相似的未标记的数据可用, 即使老师模型的性能不变, 随着数据的增多, 学生模型的性能也会提高, 可以试一下.