一 NetCat Source
NetCat Source:采集端口数据
创建配置文件netcat-flume-logger.conf
# 给三大组件取名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置 NetCat Source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # 配置 Logger Sink a1.sinks.k1.type = logger # 配置 Memory Channel a1.channels.c1.type = memory # channel最大容量为1000个event a1.channels.c1.capacity = 1000 # 每次事务传输100个event a1.channels.c1.transactionCapacity = 100 # 配置三大组件的绑定关系 # 一个source可以通过多个channel传输 a1.sources.r1.channels = c1 # 一个sink只能接受唯一的channel传输的数据 a1.sinks.k1.channel = c1
启动flume,此时flume充当netcat服务器
bin/flume-ng agent --conf conf/ --conf-file job/netcat-flume-logger.conf --name a1 -Dflume.root.logger=INFO,console
启动命令也可以简写如下
bin/flume-ng agent -c conf -f job/netcat-flume-logger.conf --n a1 -Dflume.root.logger=INFO,console
发送端口消息
[atguigu@hadoop102 ~]$ nc localhost 44444 hello OK flume OK
flume采集并打印消息到控制台
2020-06-05 17:57:40,069 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F hello }
2020-06-05 17:57:41,813 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 66 6C 75 6D 65 flume }
二 Exec Source
Exec Source:通过tail -F 命令,监控单个文件里的内容的变化。
编写配置文件file-flume-hdfs.conf
# 给三大组件取名 a2.sources = r2 a2.sinks = k2 a2.channels = c2 # 配置 Exec Source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log # 配置 HDFS Sink a2.sinks.k2.type = hdfs #路径配合文件夹滚动使用,这里配的一小时一个文件夹。生产环境一般一天一个文件夹。 a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳,各种按时间滚动的时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k2.hdfs.batchSize = 1000 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件,单位秒 a2.sinks.k2.hdfs.rollInterval = 30 #设置每个文件的滚动大小,比块略小一点,单位byte a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k2.hdfs.rollCount = 0 # 配置 Memory Channel a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # 配置三大组件的绑定关系 a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2
启动flume
bin/flume-ng agent -c conf/ -f job/file-flume-hdfs.conf -n a2
随便执行几条hive查询产生日志,查看hdfs上的文件
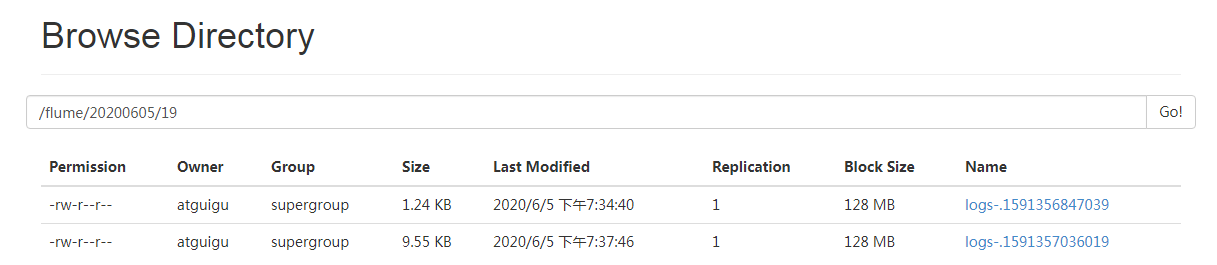
三 Spooling Directory Source
Spooling Directory Source:监控文件夹里的文件的变动,不能监控到文件内容的修改变化。文件夹到hdfs。
编写配置文件dir-flume-hdfs.conf
# 给三大组件取名 a3.sources = r3 a3.sinks = k3 a3.channels = c3 # 配置 Spooling Directory Source a3.sources.r3.type = spooldir a3.sources.r3.spoolDir = /opt/module/flume/upload #忽略所有以.tmp 结尾的文件,不上传 a3.sources.r3.ignorePattern = ([^ ]*.tmp) # 配置 HDFS Sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 # 配置 Memory Channel a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # 配置三大组件的绑定关系 a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3
启动flume
bin/flume-ng agent -c conf/ -f job/dir-flume-hdfs.conf -n a3
将事先准备的几个文件复制到upload文件夹,flume采集完成后,默认添加.COMPLETED后缀
[atguigu@hadoop102 flume]$ cp 1.txt upload/ [atguigu@hadoop102 flume]$ cp 2.txt upload/ [atguigu@hadoop102 flume]$ ls -l upload/ 总用量 8 -rw-rw-r-- 1 atguigu atguigu 26 6月 5 20:36 1.txt.COMPLETED -rw-rw-r-- 1 atguigu atguigu 26 6月 5 20:36 2.txt.COMPLETED
查看上传到hdfs的文坚,略。
四 Taildir Source
实时监控目录下的多个追加文件
创建配置文件files-flume-logger.conf
# 给三大组件取名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置 Taildir Source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 f2 a1.sources.r1.filegroups.f1 = /opt/module/flume/files/file1.txt a1.sources.r1.filegroups.f2 = /opt/module/flume/files/file2.txt a1.sources.r1.positionFile = /opt/module/flume/position/position.json # 配置 Logger Sink a1.sinks.k1.type = logger # 配置 Memory Channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 配置三大组件的绑定关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动flume
bin/flume-ng agent -c conf/ -f job/files-flume-logger.conf -n a1 -Dflume.root.logger=INFO,console
分别往file1和file2里追加数据
[atguigu@hadoop102 flume]$ echo atguigu >> files/file1.txt [atguigu@hadoop102 flume]$ echo hello >> files/file2.txt
可以看到flume都可以采集到
2020-06-07 18:57:31,082 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 61 74 67 75 69 67 75 atguigu }
2020-06-07 18:57:46,320 (PollableSourceRunner-TaildirSource-r1) [INFO - org.apache.flume.source.taildir.ReliableTaildirEventReader.openFile(ReliableTaildirEventReader.java:283)] Opening file: /opt/module/flume/files/file2.txt, inode: 298173, pos: 10
2020-06-07 18:57:46,322 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F hello }
Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File 的格式如下:
[{"inode":298172,"pos":60,"file":"/opt/module/flume/files/file1.txt"},{"inode":298173,"pos":16,"file":"/opt/module/flume/files/file2.txt"}]
注:Linux 中储存文件元数据的区域就叫做 inode,每个 inode 都有一个号码,操作系统用 inode 号码来识别不同的文件,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。