一、数据库索引的建立规则
-
1、表的主键、外键必须有索引;
-
2、数据量超过300的表应该有索引;
-
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
-
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
-
5、索引应该建在选择性高的字段上;
-
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
-
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引; -
8、频繁进行数据操作的表,不要建立太多的索引;
-
9、删除无用的索引,避免对执行计划造成负面影响;'
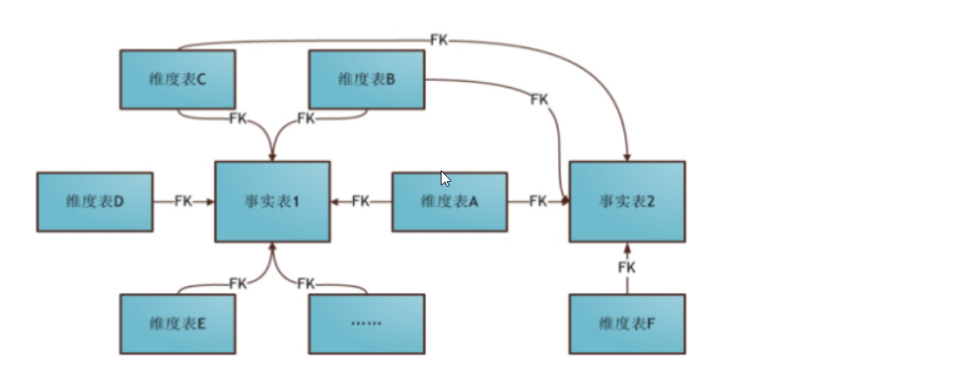
二、星型模型和雪花模型
(一)星型模型
星型模型:是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。事实表的非主键属性称为事实(Fact),它们一般都是数值或其他可以进行计算的数据;如下图:

星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,所以数据有一定的冗余
(二)雪花型模型
雪花型模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。
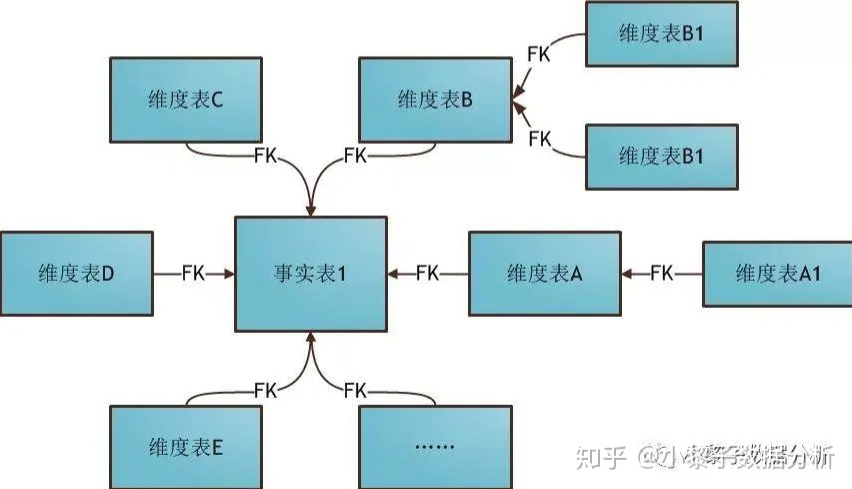
雪花型模型通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
(三)星型模型对比雪花型模型
-
1、查询性能角度来看
在OLTP-DW环节,由于雪花型要做多个表联接,性能会低于星型架构;但从DW-OLAP环节,由于雪花型架构更有利于度量值的聚合,因此性能要高于星型架构。 -
2、模型复杂度角度
星型架构更简单方便处理 -
3、层次结构角度
雪花型架构更加贴近OLTP系统的结构,比较符合业务逻辑,层次比较清晰。 -
4、存储角度
雪花型架构具有关系数据模型的所有优点,不会产生冗余数据,而相比之下星型架构会产生数据冗余。
(四)星座模型
星座模型是星型模型延生而来,星型模型是给予一张事实表,而星座模型是基于多张事实表的,而且共享纬度信息。
前面介绍的两种纬度建模方法都是多维表对应单事实表,单在很多时候纬度空间内的事实表不止一个。而一个纬度表也可能被多个事实表用到。在业务发展后期,绝大部分建模都采用的是星座模型。