一.安装maven
linux eclipse3.6.1 maven安装
二:官网依赖库
我们可以直接去官网查找我们需要的依赖包的配置pom,然后加到项目中。
官网地址:http://mvnrepository.com/
三:Hadoop依赖
我们需要哪些Hadoop的jar包?
做一个简单的工程,可能需要以下几个

hadoop-common hadoop-hdfs hadoop-mapreduce-client-core hadoop-mapreduce-client-jobclient hadoop-mapreduce-client-common
四:配置
打开工程的pom.xml文件。根据上面我们需要的包去官网上找,找对应版本的,这么我使用的2.5.2版本。
修改pom.xml如下:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.5.2</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
五:构建完毕
点击保存,就会发现maven在帮我们吧所需要的环境开始构建了。
等待构建完毕。
六:新建WordCountEx类
在src/main/java下新建WordCountEx类
package firstExample;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountEx {
static class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
protected void map(
Object key,
Text value,
org.apache.hadoop.mapreduce.Mapper<Object, Text, Text, IntWritable>.Context context)
throws java.io.IOException, InterruptedException {
// 分隔字符串
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
// 排除字母少于5个字
String tmp = itr.nextToken();
if (tmp.length() < 5) {
continue;
}
word.set(tmp);
context.write(word, one);
}
}
}
static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private Text keyEx = new Text();
protected void reduce(
Text key,
java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws java.io.IOException, InterruptedException {
int sum=0;
for (IntWritable val:values) {
//
sum+= val.get()*2;
}
result.set(sum);
//自定义输出key
keyEx.set("输出:"+key.toString());
context.write(keyEx, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//配置信息
Configuration conf=new Configuration();
//job的名称
Job job=Job.getInstance(conf,"mywordcount");
job.setJarByClass(WordCountEx.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//输入, 输出path
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//结束
System.out.println(job.waitForCompletion(true)?0:1);
}
}
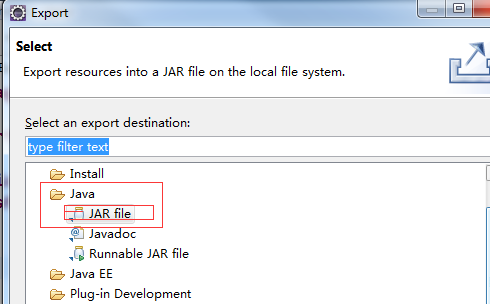
七:导出Jar包
点击工程,右键->Export,如下:

八:执行
将导出的jar包放到C:UsershadoopDesktop下,而后上传的Linux中/home/hadoop/workspace/下
上传world_ 01.txt , hadoop fs -put /home/hadoop/workspace/words_01.txt /user/hadoop
执行命令,发现很顺利的就成功了
hadoop jar /home/hadoop/workspace/first.jar firstExample.WordCountEx /user/hadoop/world_ 01.txt /user/hadoop/out

结果为:

示例下载
Github:https://github.com/sinodzh/HadoopExample/tree/master/2015/first