一、爬取分析
必应壁纸:https://bing.ioliu.cn/
这里共有1~84页,每页12张图片

对于图片的地址分析:
首先是首页能获取到图片名称:/photo/PoniesWales_EN-AU12228719072?force=home_2
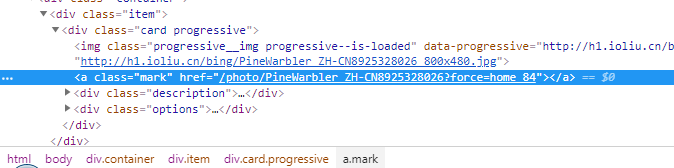
在通过对图片详情页分析:通过对地址拼接就能得到图片下载地址
http://h1.ioliu.cn/bing/PoniesWales_EN-AU12228719072_1920x1080.jpg

二、源码分享
import re import sys import os import requests import urllib.request from bs4 import BeautifulSoup # get all image pae 1~84 def allpage(): for i in range(2,84): url = 'https://bing.ioliu.cn/?p=' + str(i) imageitem(url) # print (url) # get each image item def imageitem(url): # url = "https://bing.ioliu.cn/?p=2" html_doc = urllib.request.urlopen(url).read() # html_doc = html_doc.decode('utf-8') soup = BeautifulSoup(html_doc,"html.parser",from_encoding="UTF-8") links = soup.select('.container .item .mark') for link in links: s = link['href'] down(strhandler(s)) def strhandler(s): # s = '/photo/PoniesWales_EN-AU12228719072?force=home_2' l = s.find('?') s = s[7:l] # print (s) return s # download image def down(name): url = 'http://h1.ioliu.cn//bing/'+str(name)+'_1920x1080.jpg' headers = { 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Connection': 'keep-alive', 'Referer': url, 'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW 64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE' } r = requests.get(url,headers=headers) path = 'photos/'+name+'.jpg' print (r) print (' downing.. '+path) with open(path, "wb") as code: code.write(r.content) def main(): allpage() # Test allpage() # down('PoniesWales_EN-AU12228719072')
三、结果
成功下载,在photots下生成文件

四、注意
1、bing网站的反爬虫

需要设置headers进行模拟,在requests中进行设置:
headers = { 'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate, br', 'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2', 'Connection': 'keep-alive', 'Referer': url, 'User-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW 64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE' } r = requests.get(url,headers=headers)
成功后:
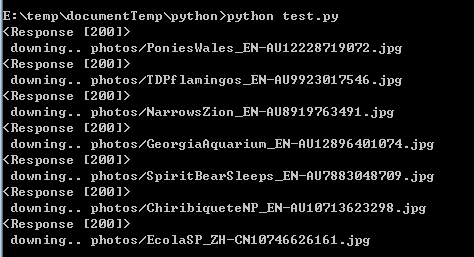
2、效率问题
由于未使用爬虫优化,所以速度比较慢
单线程爬取
可以采用多线程进行同时爬取,以加快速度。