1.1 目标
-
明确要抓取的信息
1.2 目标分解
1.2.1 抓取首页的分类信息
-
抓取数据:各级分类的
名称和URL
-
大分类名称和url
-
中分类名称和url
-
小分类名称和url
-
1.2.2 抓取商品信息
-
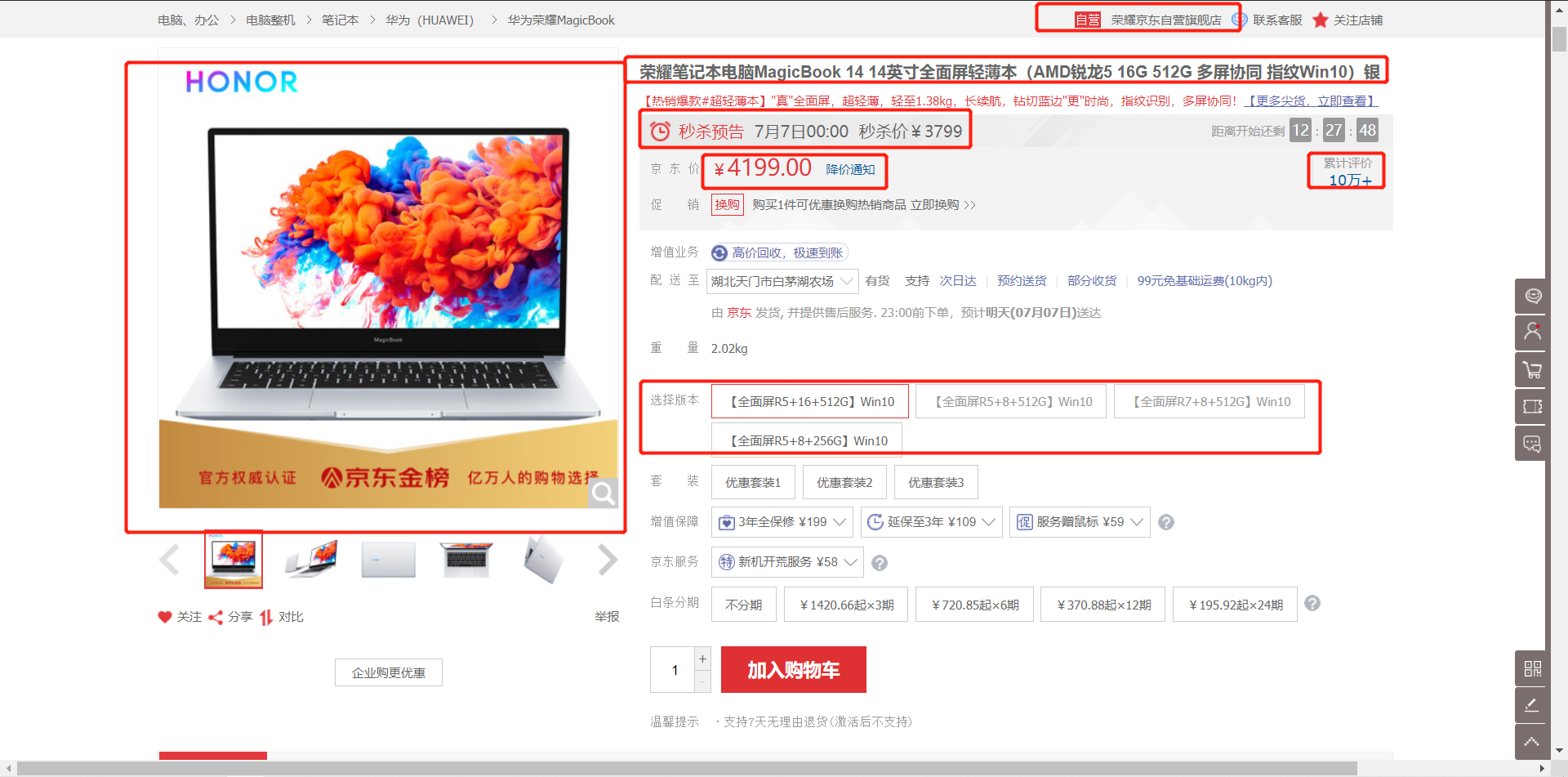
抓取数据
-
商品名称
-
商品价格
-
商品评论数量
-
商品店铺
-
商品促销
-
商品版本
-
商品图片的ULR
-
2、开发环境与技术选择
-
平台:window+Linux
-
开发语言:python3
-
开发工具:pycharm
-
技术选择:
-
属于全网爬虫,抓取的页面非常多,考虑到效率,使用scrapy+scrapy_redis
-
数据量很多,选择MongoDB
-
3、京东全网爬虫实现步骤
-
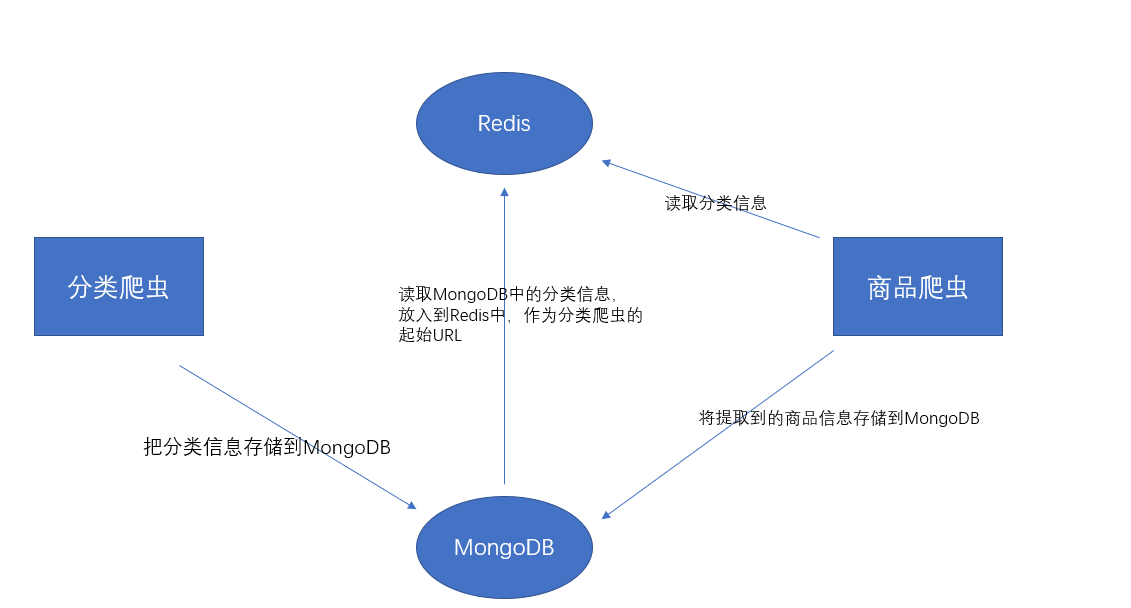
广度优先策略,将类别和商品信息的抓取分开
-
优点:逐步实现,高稳定性
-
3.1 总体设计
3.2 实现步骤
-
1.创建爬虫项目
-
2.根据需求,定义数据模型
-
3.实现分类爬虫
-
4.保存分类信息
-
5.实现商品爬虫
-
6.保存商品信息
-
7.实现随机User-Agent和代理IP下载器中间,解决IP反爬
4、数据模型
4.1 类别数据模型
-
类别数据模型类(Category(scrapy.Item)):用于存储类别信息字段
-
b_cate
-
b_cate_name:大类别名称
-
b_cate_url:大类别url
-
-
m_cate
-
m_cate_name:中类别名称
-
m_cate_url:中类别url
-
-
s_cate
-
s_cate_name:小类别名称
-
s_cate_url:小类别url
-
-
-
代码
class Category(scrapy.Item):
b_cate = scrapy.Field()
m_cate = scrapy.Field()
s_cate = scrapy.Field()
4.2 商品数据模型
-
商品数据模型类(Product(scrapy.Item)):用于存储商品信息字段
-
product_category:商品类别
-
product_sku_id:商品ID
-
product_name:商品名称
-
product_img_url:商品图片url
-
product_options:商品版本
-
product_shop:商品店铺
-
product_comments:商品评论数量
-
product_ad:商品促销信息
-
product_price:商品价格
-
product_book_info:图书信息,作者,出版社
-
-
代码:
class Product(scrapy.Item):
product_category = scrapy.Field()
product_sku_id = scrapy.Field()
product_name = scrapy.Field()
product_img_url = scrapy.Field()
product_price = scrapy.Field()
product_options = scrapy.Field()
product_shop = scrapy.Field()
product_comments = scrapy.Field()
product_ad = scrapy.Field()
product_book_info = scrapy.Field()
5、分类爬虫
5.1 确定目标url
-
目标:确定分类信息的url
-
步骤:
-
进入到京东主页
-
右击检查,全局搜索分类信息,如“超薄电视”
-
确定分类的url:“https://dc.3.cn/category/get”
-
-
url分析
-
get请求
-
查询参数:
-
callback: getCategoryCallback
-
-
5.2 创建爬虫
-
创建爬虫
-
scrapy genspider cate jd.com
-
-
指定起始url
-
https://dc.3.cn/category/get
-
-
解析数据,交给引擎
-
编码分析
-
返回数据编码为‘GBK’
-
-
url分析
有三类数据格式
-
1316-1381|面部护肤||0
-
带有一个
-的字符,需要拼接“https://channel.jd.com/{}.html”
-
list.jd.com/list.html?tid=1008668|游戏手机||0
-
完整的url,都带有
jd.com字符,不需要替换或拼接
-
-
1316-1381-1392|面膜||0
-
拼接url:“https://list.jd.com/list.html?cat=737,794,13701”,并且将
-替换为, -
有两个
-的字符,需要将-替换为,,且添加字符https://list.jd.com/list.html?cat=
-
-
-
-
代码
import scrapy
import json
from jingdong.items import Category
class CateSpider(scrapy.Spider):
name = 'cate'
allowed_domains = ['dc.3.cn']
start_urls = ['https://dc.3.cn/category/get']
def get_name_and_url(self, cate_info, cate_name, cate_url):
cate = list()
if isinstance(cate_info, list):
for _ in cate_info:
item = dict()
item[cate_name] = _.split(r'|')[1]
url = _.split(r'|')[0]
if 'jd.com' in url:
item[cate_url] = "https://" + url
elif url.count("-") == 1:
item[cate_url] = 'https://channel.jd.com/{}.html'.format(url)
elif url.count("-") == 2:
item[cate_url] = 'https://list.jd.com/list.html?cat={}'.format(url.replace('-', ','))
cate.append(item)
return cate
if isinstance(cate_info, str):
item = dict()
item[cate_name] = cate_info.split(r'|')[1]
url = cate_info.split(r'|')[0]
if 'jd.com' in url:
item[cate_url] = "https://" + url
elif url.count("-") == 1:
item[cate_url] = 'https://channel.jd.com/{}.html'.format(url)
elif url.count("-") == 2:
item[cate_url] = 'https://list.jd.com/list.html?cat={}'.format(url.replace('-', ','))
cate.append(item)
return cate
def get_info_from_s(self, data):
n_cate_list = list()
s_cate_list = list()
if isinstance(data, list):
for _ in data:
# 获取单个条目下的数据
name = _['n']
info = _["s"]
if name:
n_cate_list.append(name)
if info:
s_cate_list.append(info)
return n_cate_list, s_cate_list
if isinstance(data, dict):
name = data['n']
info = data[