Keras方法详解
- Keras是一个高层神经网络库,基于Tensorflow或Theano,由纯Python编写而成并。
1. keras.models.Sequential模型
- Keras的核心数据结构是“模型”,模型是一种组织网络层的方式。
- Keras的主要模型是Sequential模型,Sequential是一系列网络层按顺序构成的栈。
from keras.models import Sequential model = Sequential()
将一些网络层通过.add()堆叠起来,就构成了一个模型:
from keras.layers import Dense, Activation model.add(Dense(output_dim=64, input_dim=100)) model.add(Activation("relu")) model.add(Dense(output_dim=10)) model.add(Activation("softmax"))
模型搭建完成后,需要使用.compile()方法来编译模型。编译模型时必须指明损失函数和优化器,如果需要的话,也可以定制自己的损失函数。
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
from keras.optimizers import SGD model.compile(loss='categorical_crossentropy', optimizer=SGD(lr=0.01, momentum=0.9, nesterov=True))
完成模型编译后,在训练数据上按batch进行一定次数的迭代训练,以拟合网络。
model.fit(X_train, Y_train, nb_epoch=5, batch_size=32)
随后使用一行代码对模型进行评估,看看模型的指标是否满足任务的要求。
loss_and_metrics = model.evaluate(X_test, Y_test, batch_size=32)
或者使用训练好的模型,对新的数据进行预测:
classes = model.predict_classes(X_test, batch_size=32)
proba = model.predict_proba(X_test, batch_size=32)
2. keras.layers.Dense方法
Dense方法是Keras定义网络层的基本方法,其代码如下:
keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
参数说明如下:
-
units:该层有几个神经元
-
activation:该层使用的激活函数
-
use_bias:是否添加偏置项
-
kernel_initializer:权重初始化方法
-
bias_initializer:偏置值初始化方法
-
kernel_regularizer:权重规范化函数
-
bias_regularizer:偏置值规范化方法
-
activity_regularizer:输出的规范化方法
-
kernel_constraint:权重变化限制函数
- bias_constraint:偏置值变化限制函数
Dense方法的使用示例:
keras.layers.Dense(512, activation= 'sigmoid', input_dim= 2, use_bias= True)
- 这里定义了一个有512个节点,使用sigmoid激活函数的神经层,注意定义第一层的时候需要制定数据输入的形状,即input_dim,这样才能让数据正常喂进网络!
3. keras.layers.embeddings的Embedding 方法
- 单词嵌入是使用密集的矢量表示来表示单词和文档的一类方法。
- 词嵌入是对传统的词袋模型编码方案的改进,传统方法使用大而稀疏的矢量来表示每个单词或者在矢量内对每个单词进行评分以表示整个词汇表,这些表示是稀疏的,因为每个词汇的表示是巨大的,给定的词或文档主要由零值组成的大向量表示。
- 在词嵌入中,单词由密集向量表示,其中向量表示将单词投影到连续向量空间中,向量空间中的单词的位置是从文本中学习的,并且基于在使用单词时围绕单词的单词。
- 学习到的向量空间中的单词的位置被称为它的嵌入:Embedding。
- 从文本学习单词嵌入方法的两个流行例子包括:
- Word2Vec.
- GloVe.
- 可以将词嵌入学习作为深度学习模型的一部分。
- Embedding层只能作为深度模型的第一层。
- Keras提供了一个Embedding层,适用于文本数据的神经网络。
它要求输入数据是整数编码的,所以每个字都用一个唯一的整数表示。这个数据准备步骤可以使用Keras提供的Tokenizer API来执行。
嵌入层用随机权重进行初始化,并将学习训练数据集中所有单词的嵌入。
它是一个灵活的图层,可以以多种方式使用,例如:
- 它可以单独使用来学习一个单词嵌入,以后可以保存并在另一个模型中使用。
- 它可以用作深度学习模型的一部分,其中嵌入与模型本身一起学习。
- 它可以用来加载预先训练的词嵌入模型,这是一种迁移学习。
嵌入层被定义为网络的第一个隐藏层。它必须指定3个参数:
- input_dim:这是文本数据中词汇的取值可能数。例如,如果您的数据是整数编码为0-9之间的值,那么词汇的大小就是10个单词;
- output_dim:这是嵌入单词的向量空间的大小。它为每个单词定义了这个层的输出向量的大小。例如,它可能是32或100甚至更大,可以视为具体问题的超参数;
- input_length:这是输入序列的长度,就像您为Keras模型的任何输入层所定义的一样,也就是一次输入带有的词汇个数。例如,如果您的所有输入文档都由1000个字组成,那么input_length就是1000。
例如,下面定义一个词汇表为200的嵌入层(例如从0到199的整数编码的字,包括0到199),一个32维的向量空间,其中将嵌入单词,以及输入文档,每个文本有50个单词。
e = Embedding(input_dim=200, output_dim=32, input_length=50)
嵌入层自带学习的权重,如果将模型保存到文件中,则将包含嵌入图层的权重。
嵌入层的输出是一个二维向量,每个单词在输入文本(输入文档)序列中嵌入一个。
如果希望直接将Dense层接到Embedding层后面,则必须先使用Flatten层将Embedding层的2D输出矩阵平铺为一维矢量。
学习 Embedding的例子
4. keras.layers.core 的Flatten层
- Flatten层的实现在Keras.layers.core.Flatten()类中。
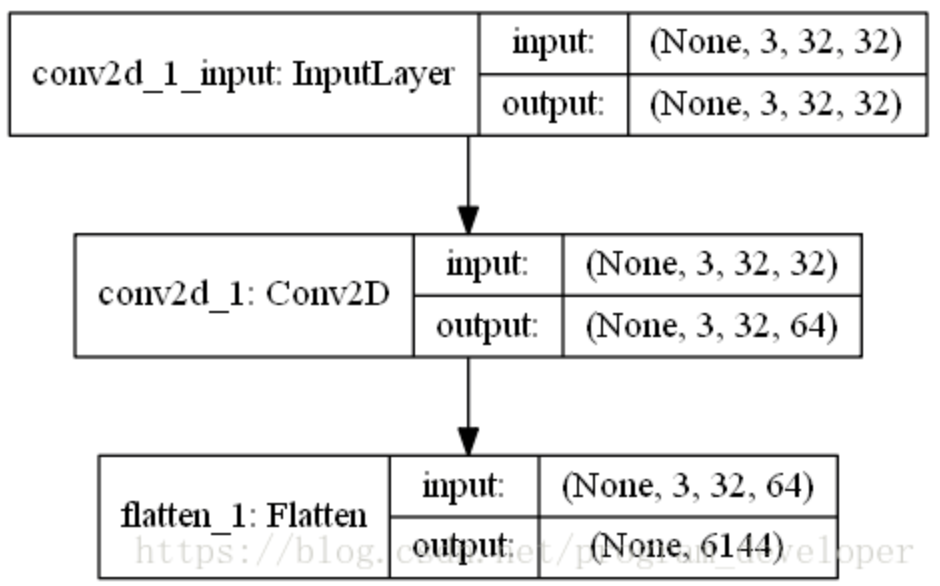
- Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
from keras.models import Sequential from keras.layers.core import Flatten from keras.layers.convolutional import Convolution2D from keras.utils.vis_utils import plot_model model = Sequential() model.add(Convolution2D(64,3,3,border_mode="same",input_shape=(3,32,32))) # now:model.output_shape==(None,64,32,32) model.add(Flatten()) # now: model.output_shape==(None,65536) plot_model(model, to_file='Flatten.png', show_shapes=True)
为了理解以上网络模型的Flatten层的作用,以上神经网络模型可视化如下: