最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候,
还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的时候一些我自己很容易搞错的点。
一、与序列文本有关
1.仅对序列文本进行one-hot编码
比如:使用路透社数据集(包含许多短新闻及其对应的主题,包括46个不同的主题,每个主题有至少10个样本)
from keras.datasets import reuters
(train_data,train_labels),(test_data,test_labels) = reuters.load_data(new_words=10000)
|
加载数据集时,参数new_words=10000表示将数据限定为前10000个最常出现的单词 有8982个训练样本和2246个测试样本 每个样本都是一个整数列表(表示单词的索引) |
word_index=reuters.get_word_index() reverse_word_index=dict([(value,key) for (key,value) in word_index.items()]) decoded_newswire = ' '.join([reverse_word_index.get(i-3,'?') for i in train_data[0]]) |
将索引解码为新闻文本 这里举个例子将训练集的第一条样本取出来,将它解码为文本 |
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
|
编码数据 把每个样本sequence编码为长度为10000的向量 |
#方法一:自定义one-hot
def to_one_hot(labels,dimension=46):
results = np.zeros((len(labels),dimension))
for i,label in enumerte(labels):
results[i,label] = i.
return results
one_hot_train_labels = to_one_hot(train_labels)
#方法二:keras内置方法
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
|
标签向量化有两种方法: 第一种是自定义的one-hot编码,将标签列表转换为整数张量 第二种是keras内置的方法 |
2.keras的Embedding层【Embedding层只能作为模型的第一层】
keras.layers.embeddings.Embedding(
input_dim,
output_dim,
embeddings_initializer='uniform',
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None
)
|
input_dim:字典长度,即输入数据最大下标+1
output_dim:代表全连接嵌入的维度
embeddings_initializer='uniform': embeddings_regularizer=None: embeddings_constraint=None: input_length=None: mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’ 输入 (samples,sequence_length)的2D张量 |
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
[[4],[20]]表示一句话由两个单词组成,第一个单词在词向量的位置为4,第二个单词位置为20
而位置为4的单词,对应的二维词向量就是[0.25,0.1];类似,位置为20的单词的词向量为[0.6,-0.2]
下面简单描述一下:
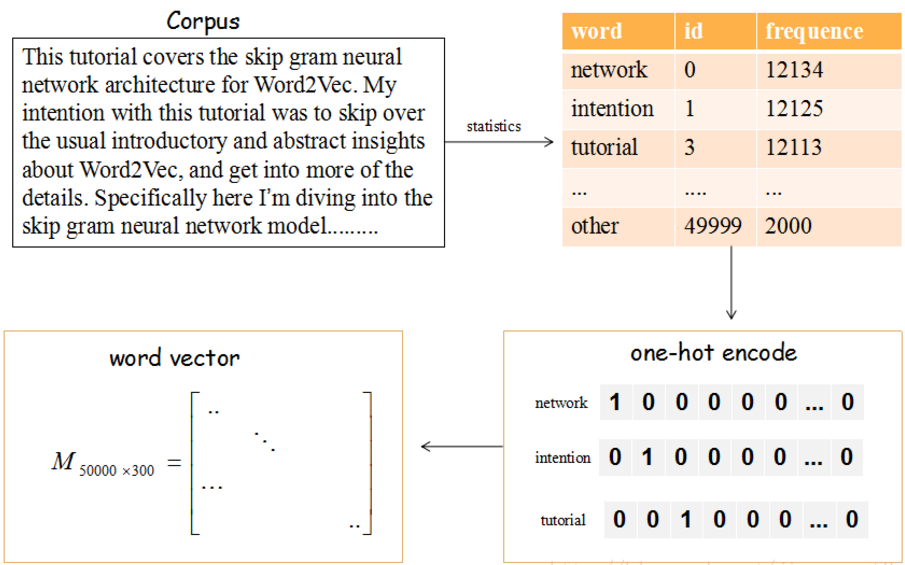
上图的流程是把文章的单词使用词向量来表示。
(1)提取文章所有的单词,把其按其出现的次数降序(这里只取前50000个),比如单词‘network’出现的次数最多,编号ID为0,依次类推…
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)最后,我们会生产一个矩阵M,行大小为词的个数50000,列大小为词向量的维度(通常取128或300),比如矩阵的第一行就是编号ID=0,即network对应的词向量。
那这个矩阵M怎么获得呢?在Skip-Gram 模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵
3.在Keras模型中使用预训练的词向量
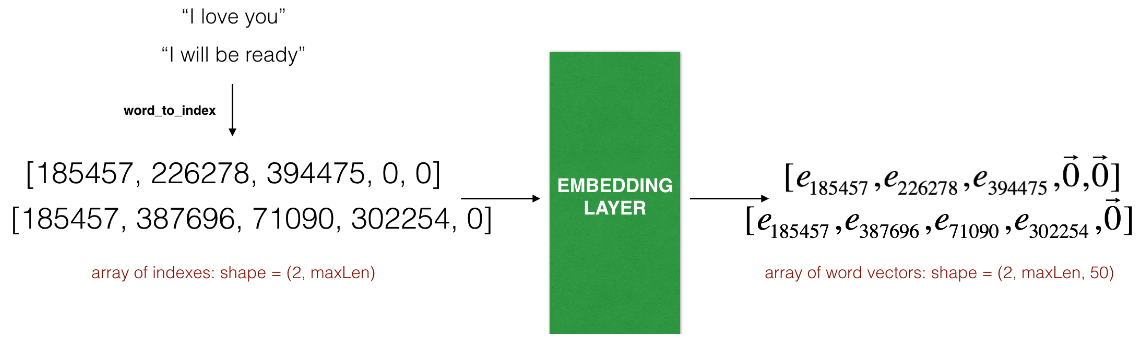
这个例子展示了两个样本通过embedding层,两个样本都经过了`max_len=5`的填充处理,
最终的维度就变成了`(2, max_len, 5)`,这是因为使用了50维的词嵌入。
首先拿到一段文本,要想通过该文本完成分类或其他的任务,就必须要把这个文本转成词向量的形式。
先对训练集进行按行切分(或者,已经有一个所有句子的列表了),然后找到单词数最大的那行作为max_len,这个待会要输入模型中的
对于没达到max_len的句子,可以通过把句子给扩充为max_len长度
import keras.preprocessing.sequence import pad_sequences pad_sequences(sequences,maxlen=max_len)
然后得到每行单词对应的词向量,现在所有行的维度应该是(行数,单词数最多的那行对应的单词个数,每个单词词向量的维度)
模型的输入是(一批多少序列batch,输入长度input_length)
word index单词索引不超过999,词向量的个数上限值1000
输出是(None,10,64) None表示batch的维度(个数),64是每个单词的词向量的维度
model = Sequential() model.add(Embedding(1000, 64, input_length=10))
input_array = np.random.randint(1000, size=(32, 10))#32句话,每句话10个单词
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64) #32句话,每句话10个单词,每个单词有64维的词向量
4. 当多个循环层堆叠时,前面所有循环层中间层都需要返回完整的输出序列,最后一层仅返回最终输出
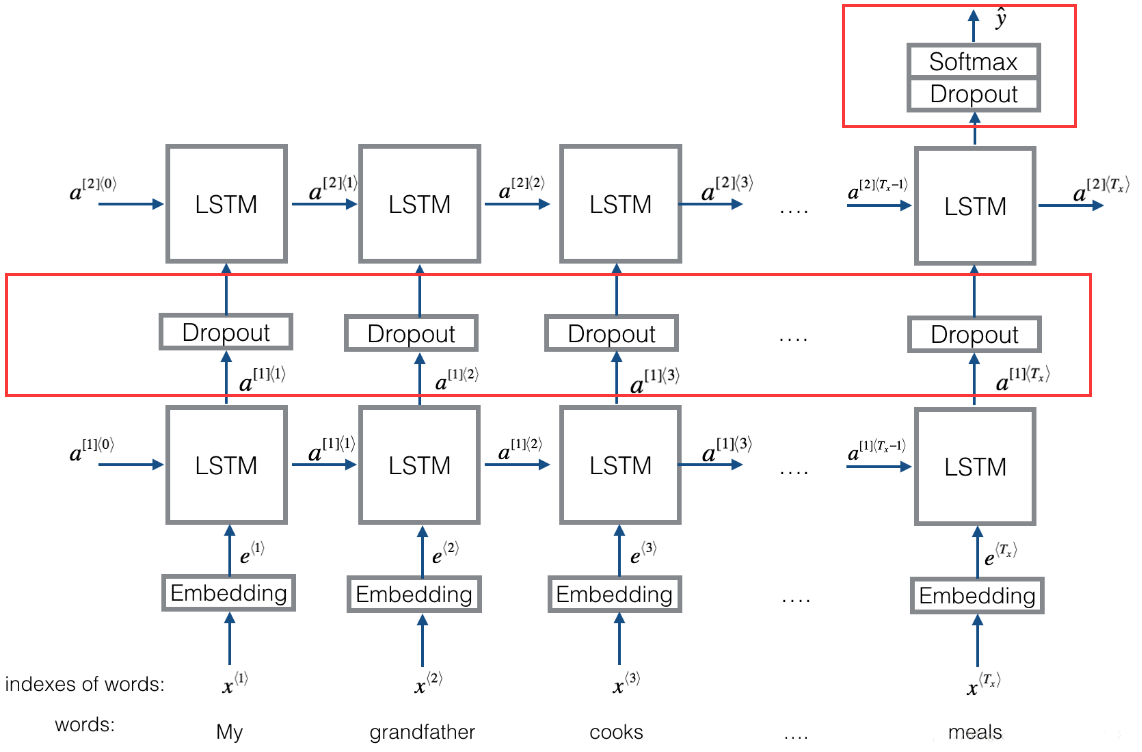
二、与图片数据有关
1.处理一张输入图像,改成模型规定输入格式才能输入模型中
from keras.preprocessing import image from keras.applications.vgg16 import preprocess_input,decode_predictions import numpy as np img_path = '图片的路径' img = image.load_img(img_path,target_size=(224,224)) #224 224是模型要求输入大小 x = image.img_to_array(image)#将图片转换为(224,224,3)的float32格式的numpy数组 x = np.expand_dims(x,axis=0)#添加一个维度,将数组转换为(1,224,224,3)形状的批量, #因为keras模型是以batch作为输入的,所以一张图片就相当于batch=1 x = preprocess_input(x)#对批量进行预处理(按通道进行颜色标准化) preds = model.predict(x)
2.输入图像的张量,显示图片
注意:这里图像的张量,取值可能不是[0,255]区间内的整数,需要对这个张量进行后处理,将其转换为可显示的图像
def deprocess_image(x):
x -= x.mean() #对张量做标准化,使其均值为0,标准差为0.1
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
x = np.clip(x,0,1) #将x裁切(clip)到[0,1]区间
x *= 255
x = np.clip(x,0,255).astype('uint8') #将x转换为RGB数组
return x
#执行下面这句话就能看到图片了
#例:image的大小为(150,150,3)
plt.imshow(deprocess_image(image))
3.我们拿到的训练数据一般不是同一个大小的,需要将图像全部调整成指定大小的
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255) #将所有图像乘以1/255缩放
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),#将所有图像的大小调整为(255,255)
batch_size = 20,
class_mode = 'binary, #这里目标是二分类,所以用二进制标签
)
三、常见的误差与精确性指标
误差
- mean_squared_error / mse 均方误差,常用的目标函数,公式为((y_pred-y_true)**2).mean()
- mean_absolute_error / mae 绝对值均差,公式为(|y_pred-y_true|).mean()
- mean_absolute_percentage_error / mape公式为:(|(y_true - y_pred) / clip((|y_true|),epsilon, infinite)|).mean(axis=-1) * 100,和mae的区别就是,累加的是(预测值与实际值的差)除以(剔除不介于epsilon和infinite之间的实际值),然后求均值。
- mean_squared_logarithmic_error / msle公式为: (log(clip(y_pred, epsilon, infinite)+1)- log(clip(y_true, epsilon,infinite)+1.))^2.mean(axis=-1),这个就是加入了log对数,剔除不介于epsilon和infinite之间的预测值与实际值之后,然后取对数,作差,平方,累加求均值。
- squared_hinge 公式为:(max(1-y_true*y_pred,0))^2.mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的平方的累加均值。
- hinge 公式为:(max(1-y_true*y_pred,0)).mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的的累加均值。
- binary_crossentropy: 常说的逻辑回归, 就是常用的交叉熵函数
- categorical_crossentropy: 多分类的逻辑, 交叉熵函数的一种变形吧,没看太明白
精确性
- binary_accuracy: 对二分类问题,计算在所有预测值上的平均正确率
- categorical_accuracy:对多分类问题,计算再所有预测值上的平均正确率
- sparse_categorical_accuracy:与
categorical_accuracy相同,在对稀疏的目标值预测时有用 - top_k_categorical_accracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
- sparse_top_k_categorical_accuracy:与top_k_categorical_accracy作用相同,但适用于稀疏情况
参考文献