一、摘要种类
-
抽取式摘要
直接从原文中抽取一些句子组成摘要。本质上就是个排序问题,给每个句子打分,将高分句子摘出来,再做一些去冗余(方法是MMR)等。这种方式应用最广泛,因为比较简单。经典方法有LexRank和整数线性规划(ILP)。
LexRank是将文档中的每个句子都看作节点,句子之间的相似度看作节点之间的边的权重,构建一个graph;然后再计算每个节点的分数,这个打分的计算方式可以是度中心度(Degree centrality)、PageRank中心度等(论文里说这两种计算方式其实效果没有太大差别,文中用的ROUGE-1作为指标);这个方法的要点在于:不能每两个句子之间都有边,要设定一个阈值,只有相似度大于这个阈值才能有边,阈值太大则丢失太多信息,阈值太小则又引入了太多噪声。
-
压缩式摘要
有两种方式:一种是pipeline,先抽取出句子,再做句子压缩,或者先做句子压缩,再抽句子。另一种是jointly的方式,抽句子和压缩句子这两个过程是同时进行的。
句子压缩(Sentence compression)的经典方法是ILP:句子中的每个词都对应一个二值变量表示该词是否保留,并且每个词都有一个打分(比如tf-idf),目标函数就是最大化句子中的词的打分;既然是规划那当然要给出限制,最简单的限制比如说至少保留一个词,再比如说当形容词被保留时其修饰的词也要保留(根据parse tree)。
-
理解式摘要
也叫产生式摘要,试图理解原文的意思,然后生成摘要,也就是像我们人做摘要那样来完成任务。
从是否有用户查询的角度来说,可以分为通用型摘要(generic)和基于用户查询的摘要(query-oriented),其中后者不仅要求生成的摘要应概括原文关键信息,还要尽可能与用户查询具有很高的相关性。
二、评价指标
首先可以是人工评价。目前来说,自动评价指标采用的是ROUGE,R是recall的意思,换句话说,这个指标基于摘要系统生成的摘要与参考摘要的n元短语重叠度:
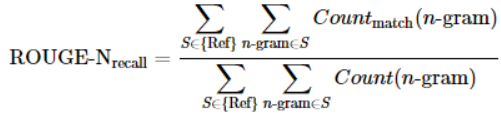
摘要这个任务要求用短序列概括长序列,用召回率这样的计算思路可以反映出人工给出的参考摘要所列出的要点中有多少被包含在了机器生成的摘要中。这个指标用来应付抽取式摘要可能问题不大,但是由于其无法评价所生成摘要的语法和语义,而且倾向于长摘要,所以其实还应该继续探索更合理的指标来评价理解式摘要。此外,当然也可以计算基于precision的ROUGE,而且ROUGE还有ROUGE-L等多种版本;最常使用的是ROUGE-N的N取2的方式(也就是ROUGE-2)。评测工具的链接是这里(https://github.com/RxNLP/ROUGE-2.0)。
三、Seq2seq与encoder-decoder
如果只说“序列到序列”的话,那么词性标注(POS)其实也是这样的过程。但是它跟翻译、摘要显著不同的地方在于:在POS问题中,输入和输出是一一对应的,而翻译、摘要的输出序列与输入序列则没有显著的对应关系。所以如下图所示,POS问题可以用最右边的那个RNN结构来建模,每个时刻的输入与输出就是词与词性。相比之下,翻译、摘要这种则可以通过倒数第二张图那样的结构来解决,这个结构可以看作是encoder和decoder都是RNN的encoder-decoder框架。

1. encoder-decoder
encoder-decoder框架的工作机制是:先使用encoder,将输入编码到语义空间,得到一个固定维数的向量,这个向量就表示输入的语义;然后再使用decoder,将这个语义向量解码,获得所需要的输出,如果输出是文本的话,那么decoder通常就是语言模型。
这种机制的优缺点都很明显,优点:非常灵活,并不限制encoder、decoder使用何种神经网络,也不限制输入和输出的模态(例如image caption任务,输入是图像,输出是文本);而且这是一个端到端(end-to-end)的过程,将语义理解和语言生成合在了一起,而不是分开处理。缺点的话就是由于无论输入如何变化,encoder给出的都是一个固定维数的向量,存在信息损失;在生成文本时,生成每个词所用到的语义向量都是一样的,这显然有些过于简单。
2. attention mechanism 注意力机制
为了解决上面提到的问题,一种可行的方案是引入attention mechanism。所谓注意力机制,就是说在生成每个词的时候,对不同的输入词给予不同的关注权重。谷歌博客里介绍神经机器翻译系统时所给出的动图形象地展示了attention:
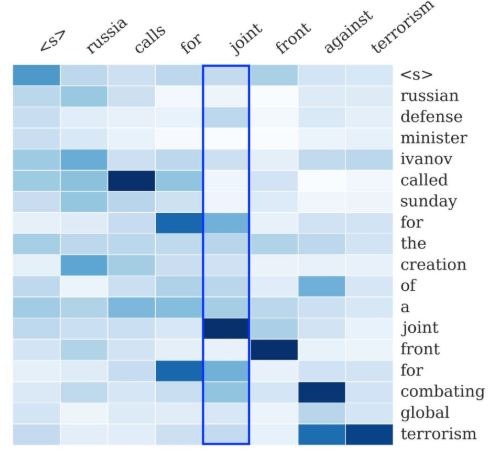
下图也展示了这一点:右侧序列是输入序列,上方序列是输出序列。输出序列的每个词都对应一个概率分布,这个概率分布决定了在生成这个词的时候,对于输入序列的各个词的关注程度。如图所示,看蓝色框起来的那一列,就是模型在生成joint这个词时的概率分布,颜色最深的地方对应的是输入的joint,说明模型在生成joint这个词时最为关注的输入词是joint。所谓attention,就是说生成每个词时都为这个词得到这个概率分布,进而可以使生成的词“更好”。
参考文献: