- 0范数:向量中非零元素的个数。
- 1范数:为绝对值之和。1范数和0范数可以实现稀疏,1因具有比L0更好的优化求解特性而被广泛应用。
- 2范数:就是通常意义上的模,L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的正则项||W||2最小,可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别;所以比起1范数,更钟爱2范数。
一、为什么正则化可以防止过拟合
莫烦的解释:
1. 过拟合:
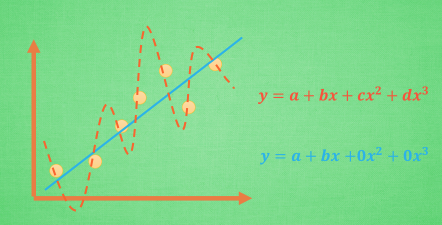
过拟合就是所谓的模型对可见的数据过度自信, 非常完美的拟合上了这些数据, 如果具备过拟合的能力, 那么这个方程就可能是一个比较复杂的非线性方程 , 正是因为这里的 x^3 和 x^2 使得这条虚线能够被弯来弯去, 所以整个模型就会特别努力地去学习作用在 x^3 和 x^2 上的 c d 参数. 但是我们期望模型要学到的却是这条蓝色的曲线. 因为它能更有效地概括数据.而且只需要一个 y=a+bx 就能表达出数据的规律. 或者是说, 蓝色的线最开始时, 和红色线同样也有 c d 两个参数, 可是最终学出来时, c 和 d 都学成了0, 虽然蓝色方程的误差要比红色大, 但是概括起数据来还是蓝色好. 那我们如何保证能学出来这样的参数呢? 这就是 l1 l2 正则化出现的原因啦.
2. L1、L2 Regularization
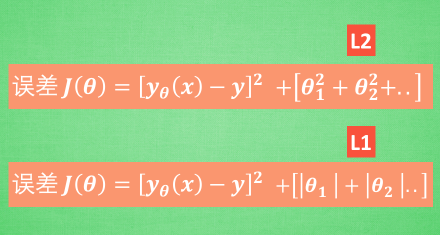
对于刚刚的线条, 我们一般用这个方程来求得模型 y(x) 和 真实数据 y 的误差, 而 L1 L2 就只是在这个误差公式后面多加了一个东西, 让误差不仅仅取决于拟合数据拟合的好坏, 而且取决于像刚刚 c d 那些参数的值的大小. 如果是每个参数的平方, 那么我们称它为 L2正则化, 如果是每个参数的绝对值, 我们称为 L1 正则化. 那么它们是怎么样工作的呢?
3. 核心思想

我们拿 L2正则化来探讨一下, 机器学习的过程是一个 通过修改参数 theta 来减小误差的过程, 可是在减小误差的时候非线性越强的参数, 比如在 x^3 旁边的 theta 4 就会被修改得越多, 因为如果使用非线性强的参数就能使方程更加曲折, 也就能更好的拟合上那些分布的数据点. Theta 4 说, 瞧我本事多大, 就让我来改变模型, 来拟合所有的数据吧, 可是它这种态度招到了误差方程的强烈反击, 误差方程就说: no no no no, 我们是一个团队, 虽然你厉害, 但也不能仅仅靠你一个人, 万一你错了, 我们整个团队的效率就突然降低了, 我得 hold 住那些在 team 里独出风头的人. 这就是整套正规化算法的核心思想. 那 L1, L2 正则化又有什么不同呢?
图像化
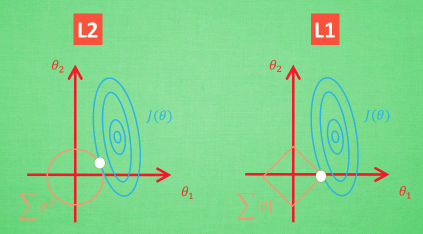
想象现在只有两个参数 theta1 theta2 要学, 蓝色的圆心是误差最小的地方, 而每条蓝线上的误差都是一样的. 正则化的方程是在黄线上产生的额外误差(也能理解为惩罚度), 在黄圈上的额外误差也是一样. 所以在蓝线和黄线 交点上的点能让两个误差的合最小. 这就是 theta1 和 theta2 正则化后的解. 要提到另外一点是, 使用 L1 的方法, 我们很可能得到的结果是只有 theta1 的特征被保留, 所以很多人也用 l1 正则化来挑选对结果贡献最大的重要特征. 但是 l1 的结果并不是稳定的. 比如用批数据训练, 每次批数据都会有稍稍不同的误差曲线,

L2 针对于这种摆动, 白点的移动不会太大, 而 L1的白点则可能跳到许多不同的地方 , 因为这些地方的总误差都是差不多的. 侧面说明了 L1 解的不稳定性。
统一表达形式:
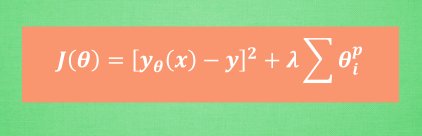
最后,为了控制这种正规化的强度, 我们会加上一个参数 lambda, 并且通过 交叉验证 cross validation 来选择比较好的 lambda. 这时, 为了统一化这类型的正则化方法, 我们还会使用 p 来代表对参数的正则化程度. 这就是这一系列正则化方法的最终的表达形式啦.
知乎大牛的解释:
一般正则项:
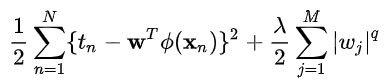
M是模型的阶次(表现形式是数据的维度),比如M=2,就是一个平面(二维)内的点
若q=2就是二次正则项,高纬度没有图像表征非常难以理解,那就使用二维作为特例来理解。这里M=2,即X={x1,x2},w={w1,w2},令q=0.5,;q=1;q=2;q=4有

横坐标是
纵坐标是
绿线是等高线的其中一条,换言之是一个俯视图,而z轴代表的是
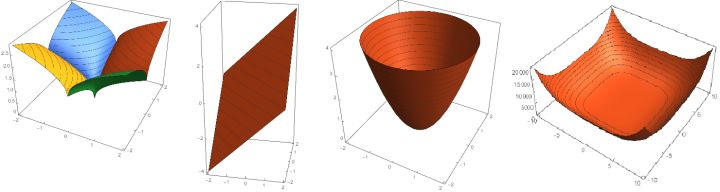
q=2是一个圆,考虑z=w12+w22就是抛物面,俯视图是一个圆。 其他几项同理(z轴表示的是正则项的值)

蓝色的圆圈表示没有经过限制的损失函数在寻找最小值过程中,w的不断迭代(随最小二乘法,最终目的还是使损失函数最小)变化情况,表示的方法是等高线,z轴的值就是E(),蓝线和红线交点w*是最小值取到的点。
可以直观的理解为, 我们的目标函数(误差函数)就是求蓝圈+红圈的和的最小值,而这个 值通常在很多情况下是两个曲面相交的地方。
可以看到二次正则项的优势,处处可导,方便计算,限制模型的复杂度,即w中M的大小,M是模型的阶次,M越大意味着需要决定的权重越多,所以模型越复杂。在多项式模型中,直观理解是每一个不同幂次的x前的系数,0(或很小的值)越多,模型越简单。这从数学角度解释了,为什么正则化可以限制模型的复杂度,进而避免过拟合。
一次项w*的位置恰好是w1=0的位置,意味着从另一种角度来说,使用一次正则项可以降低维度(降低模型复杂度,防止过拟合)二次正则项也做到了这一点,但是一次正则项做的更加彻底,更稀疏。不幸的是,一次正则项有拐点,不是处处可微,给计算带来了难度。
二、LR中的正则化解释
【1】为什么在LR中,要h(x)-y越小越好,h(x)越大越好,||w||又要越小越好?
h(x)是要求越大越好,但是也不能一昧的增大,太大容易过拟合;而我们又需要||w||2越小越好,但是也不能太小,太小容易欠拟合;所以要在大与小之间权衡,找到最好的解。
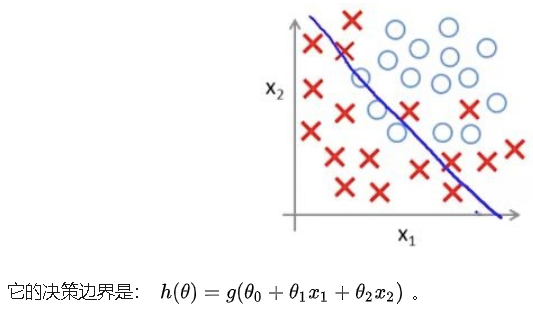


这里面哪个拟合得最好呢?当然是第三个了,几乎把所有的都完美区分开了,我们看看它的函数十分复杂,特征比另外两个都多。但是,第三个真的是最佳的吗?不是的。
LR加正则化的代价函数如下:
![]()
其中 称为惩罚项系数。小尾巴前面那项是我们原本的代价函数,现在加上了惩罚项后,我们要使得代价函数最小,则后面的小尾巴也必须要小,小尾巴小的话,那么
就不能太大,如果
很小的话,那么那个
所在的项就接近于0了,也就可以近似地看成没有了那个特征。
接下来进行梯度下降,不断地迭代如下过程:
![]()
参考文献:
【1】莫烦大大的什么是 L1/L2 正则化 (Regularization)
【3】逻辑回归与正则化