一、xgboost简介:
- 全称:eXtreme Gradient Boosting
- 作者:陈天奇(华盛顿大学博士)
- 基础:GBDT
- 所属:boosting迭代型、树类算法。
- 适用范围:分类、回归
- 优点:速度快、效果好、能处理大规模数据、支持多种语言、支持自定义损失函数等等。
- 缺点:算法参数过多,调参负责,对原理不清楚的很难使用好XGBoost。不适合处理超高维特征数据。
- 项目地址:https://github.com/dmlc/xgboost
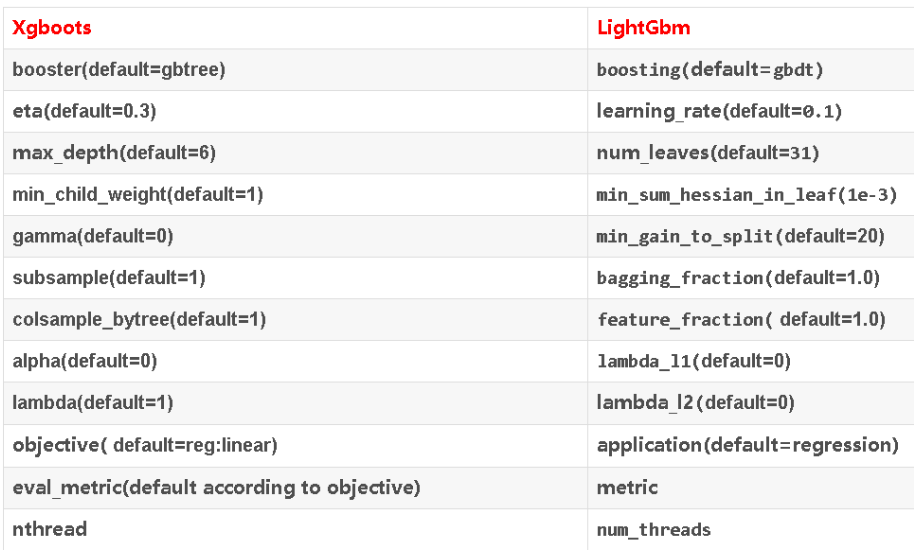
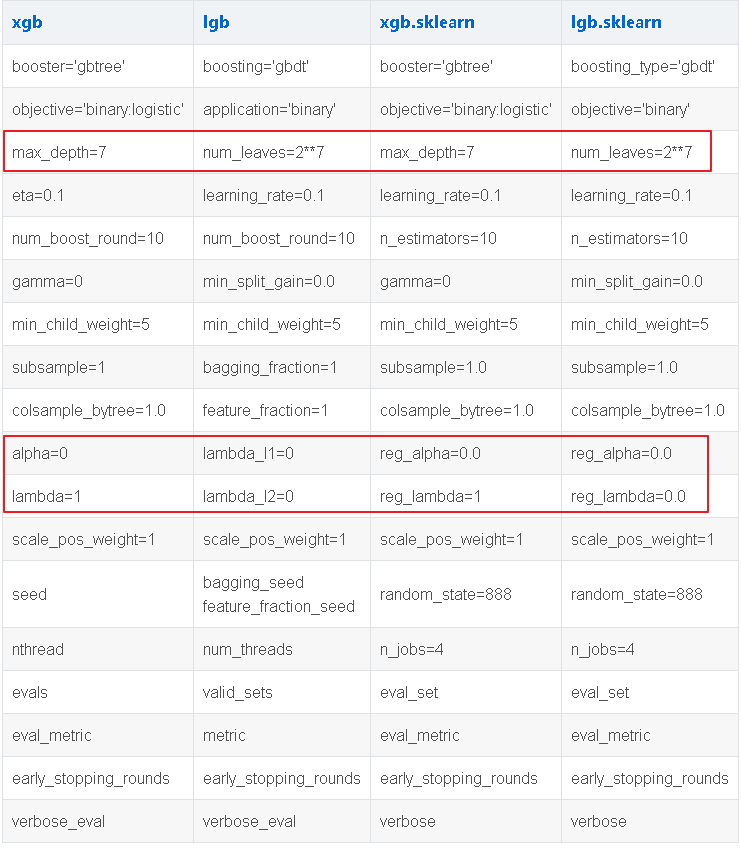
二、参数速查
参数分为三类:
- 通用参数:宏观函数控制。
- Booster参数:控制每一步的booster(tree/regression)。
- 学习目标参数:控制训练目标的表现。
二、回归
from xgboost.sklearn import XGBRegressor
from sklearn.model_selection import ShuffleSplit
import xgboost as xgb
xgb_model_ = XGBRegressor(n_thread=8)
cv_split = ShuffleSplit(n_splits = 6,train_size=0.7,test_size=0.2)
xgb_params={'max_depth':[4,5,6,7],
'learning_rate':np.linspace(0.03,0.3,10),
'n_estimators':[100,200]}
xgb_search = GridSearchCV(xgb_model_,
param_grid=xgb_params,
scoring='r2',
iid=False,
cv=5)
xgb_search.fit(gbdt_train_data,gbdt_train_label)
print(xgb_search.grid_scores_)
print(xgb_search.best_params_)
print(xgb_search.best_score_)

1.xgboost不支持MAE的解决方法
xgboost支持自定义目标函数,但是要求目标函数必须二阶可到,我们必须显示给出梯度(一阶导)和海瑟矩阵(二阶导),但是MAE不可导,
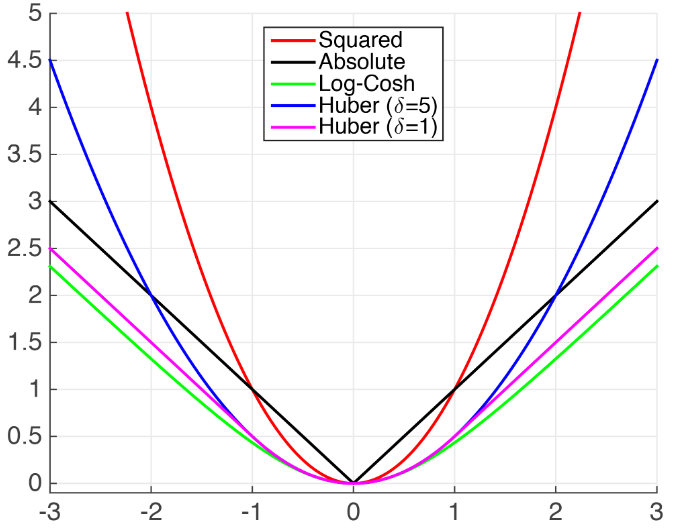
(1)xgboost自带的MSE,与MAE相距较远。比较接近的损失有Huber Loss 以及 Fair Loss。
- MSE
- Huber Loss
- Fair Loss:$c^2(frac{|x|}{c}-ln(frac{|x|}{c}+1))$
- Psuedo-Huber loss
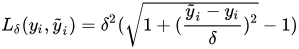
Fair Loss代码:代码来自solution in the Kaggle Allstate Challenge.
def fair_obj(preds, dtrain):
"""y = c * abs(x) - c**2 * np.log(abs(x)/c + 1)"""
x = preds - dtrain.get_labels()
c = 1
den = abs(x) + c
grad = c*x / den
hess = c*c / den ** 2
return grad, hess
Psuedo-Huber loss代码:
import xgboost as xgb
dtrain = xgb.DMatrix(x_train, label=y_train)
dtest = xgb.DMatrix(x_test, label=y_test)
param = {'max_depth': 5}
num_round = 10
def huber_approx_obj(preds, dtrain):
d = preds - dtrain.get_labels() #remove .get_labels() for sklearn
h = 1 #h is delta in the graphic
scale = 1 + (d / h) ** 2
scale_sqrt = np.sqrt(scale)
grad = d / scale_sqrt
hess = 1 / scale / scale_sqrt
return grad, hess
bst = xgb.train(param, dtrain, num_round, obj=huber_approx_obj)
具体可参考:kaggle 讨论 | Xgboost-How to use “mae” as objective function?
(2)自定义近似MAE导数:直接构造MAE的导数
- Log-Cosh Loss function:$left.log(cosh(h(mathbf{x}_{i})-y_{i})) ight.$,$left.cosh(x)=frac{e^{x}+e^{-x}}{2} ight.$
Log-cosh代码如下:
def log_cosh_obj(preds, dtrain):
x = preds - dtrain.get_labels()
grad = np.tanh(x)
hess = 1 / np.cosh(x)**2
return grad, hess
具体参考:kaggle 讨论
三、分类
前提:已经处理完所有数据,现在开始训练.
#Import libraries:
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import cross_validation, metrics #Additional scklearn functions
from sklearn.grid_search import GridSearchCV #Perforing grid search
import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
train = pd.read_csv('train_modified.csv')
target = 'Disbursed'
IDcol = 'ID'
两种XGBoost:
- xgb - 直接引用xgboost。接下来会用到其中的“cv”函数。
- XGBClassifier - 是xgboost的sklearn包。这个包允许我们像GBM一样使用Grid Search 和并行处理。
test_results = pd.read_csv('test_results.csv')
def modelfit(alg, dtrain, dtest, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
'''
功能:训练,测试,输出AUC,画出重要特征的功能
参数:alg是分类器,dtrain是训练集(包括label),dtest是测试集(不包括label),predictors是要参与训练的特征(不包括label),
useTrainCV是是否要交叉验证,cv_folds是交叉验证的折数,early_stopping_rounds是到指定次数就停止继续迭代
'''
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
xgtest = xgb.DMatrix(dtest[predictors].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#训练
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#预测
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#输出accuracy、AUC分数
print "
Model Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
#预测测试集,输出测试集的AUC分数
dtest['predprob'] = alg.predict_proba(dtest[predictors])[:,1]
results = test_results.merge(dtest[['ID','predprob']], on='ID')
print 'AUC Score (Test): %f' % metrics.roc_auc_score(results['Disbursed'], results['predprob'])
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
注意xgboost的sklearn包没有“feature_importance”这个量度,但是get_fscore()函数有相同的功能。
调参步骤:
-
选择较高的学习速率(learning rate)。一般情况下,学习速率的值为0.1。但是,对于不同的问题,理想的学习速率有时候会在0.05到0.3之间波动。选择对应于此学习速率的理想决策树数量。XGBoost有一个很有用的函数“cv”,这个函数可以在每一次迭代中使用交叉验证,并返回理想的决策树数量。
-
对于给定的学习速率和决策树数量,进行决策树特定参数调优(max_depth, min_child_weight, gamma, subsample, colsample_bytree)。在确定一棵树的过程中,我们可以选择不同的参数,待会儿我会举例说明。
-
xgboost的正则化参数的调优。(lambda, alpha)。这些参数可以降低模型的复杂度,从而提高模型的表现。
-
降低学习速率,确定理想参数。
- max_depth = 5 :这个参数的取值最好在3-10之间。我选的起始值为5,但是你也可以选择其它的值。起始值在4-6之间都是不错的选择。
- min_child_weight = 1:在这里选了一个比较小的值,因为这是一个极不平衡的分类问题。因此,某些叶子节点下的值会比较小。
- gamma = 0: 起始值也可以选其它比较小的值,在0.1到0.2之间就可以。这个参数后继也是要调整的。
- subsample, colsample_bytree = 0.8: 这个是最常见的初始值了。典型值的范围在0.5-0.9之间。
- scale_pos_weight = 1: 这个值是因为类别十分不平衡。
- 注意,上面这些参数的值只是一个初始的估计值,后继需要调优。这里把学习速率就设成默认的0.1。然后用xgboost中的cv函数来确定最佳的决策树数量。前文中的函数可以完成这个工作。
参考文献:
【2】Complete Guide to Parameter Tuning in XGBoost (with codes in Python)
【3】xgboost调参(很全)
【5】机器学习算法之XGBoost(非常详细)