Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。
1、Tensorboard的数据形式
Tensorboard可以记录与展示以下数据形式:
(1)标量Scalars
展示的是标量的信息,我程序中用tf.summary.scalars()定义的信息都会在这个窗口。 回顾程序中定义的标量有:准确率accuracy,dropout的保留率,隐藏层中的参数信息,已经交叉熵损失。这些都在SCLARS窗口下显示出来了。
点开accuracy,红线表示test集的结果,蓝线表示train集的结果,可以看到随着循环次数的增加,两者的准确度也在增加,直达1000次时会到达0.967左右。
蓝线有大幅度震动是因为batch的设置问题,在每个batch里,训练效果好,但是换了一个新batch准确率就会下降,但是整体趋势还是增加的。

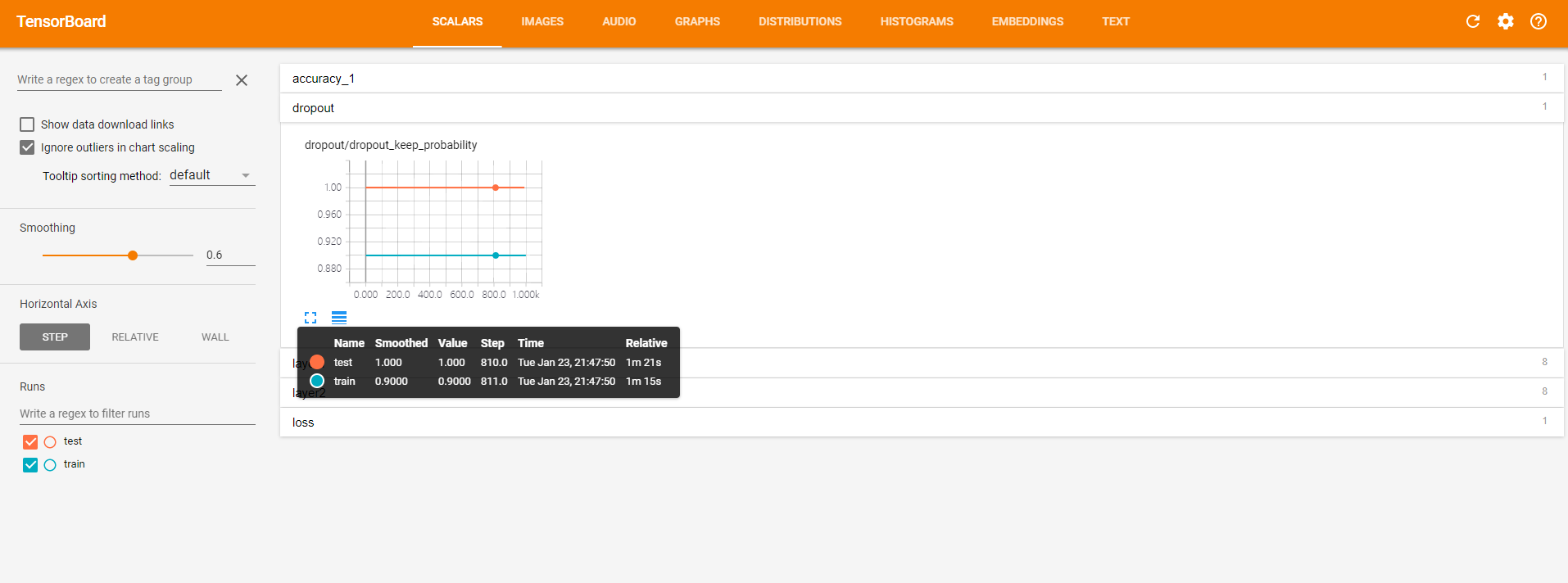
点开dropout,红线表示的测试集上的保留率始终是1,蓝线始终是0.9。
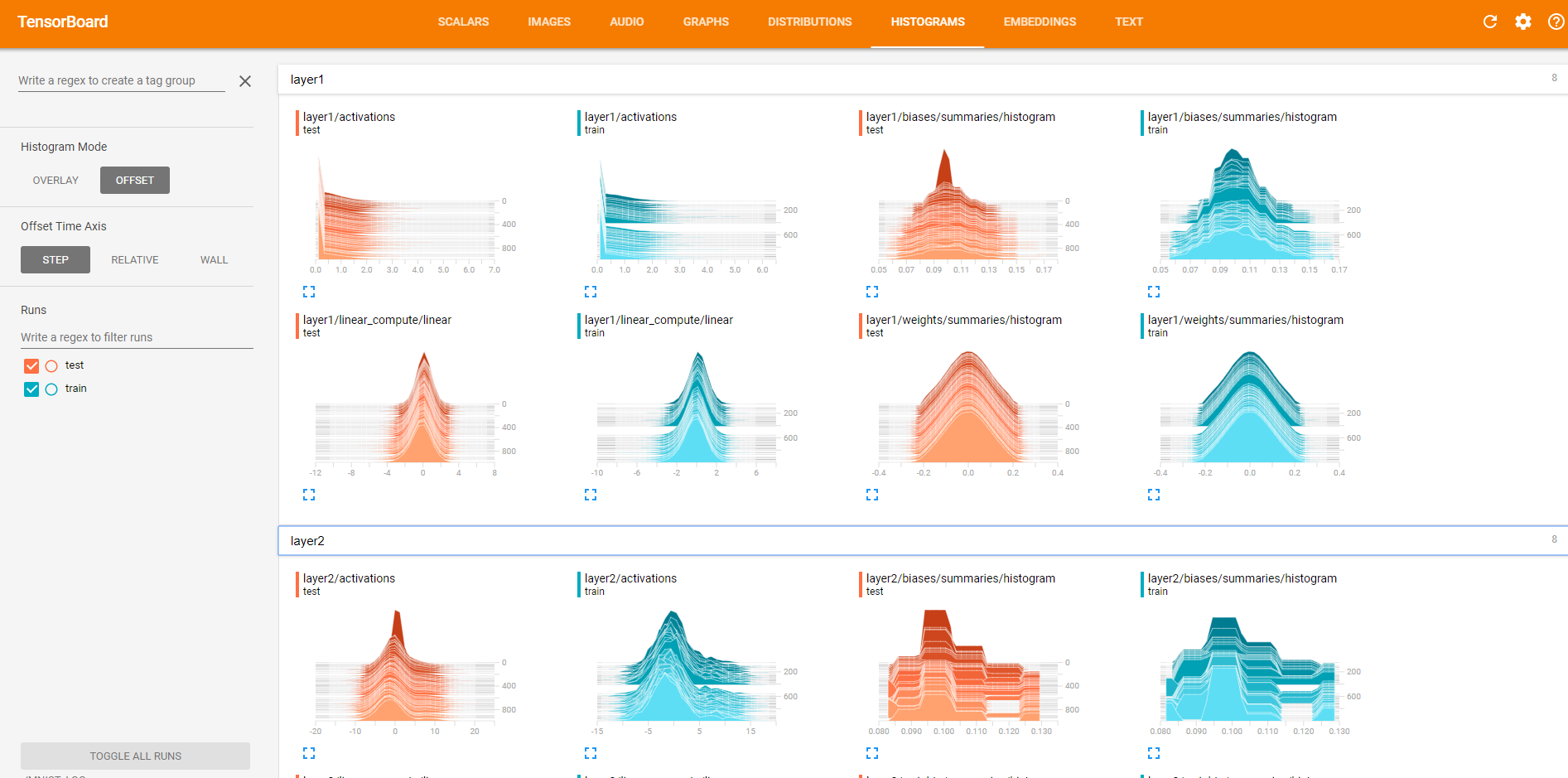
点开layer1,查看第一个隐藏层的参数信息。
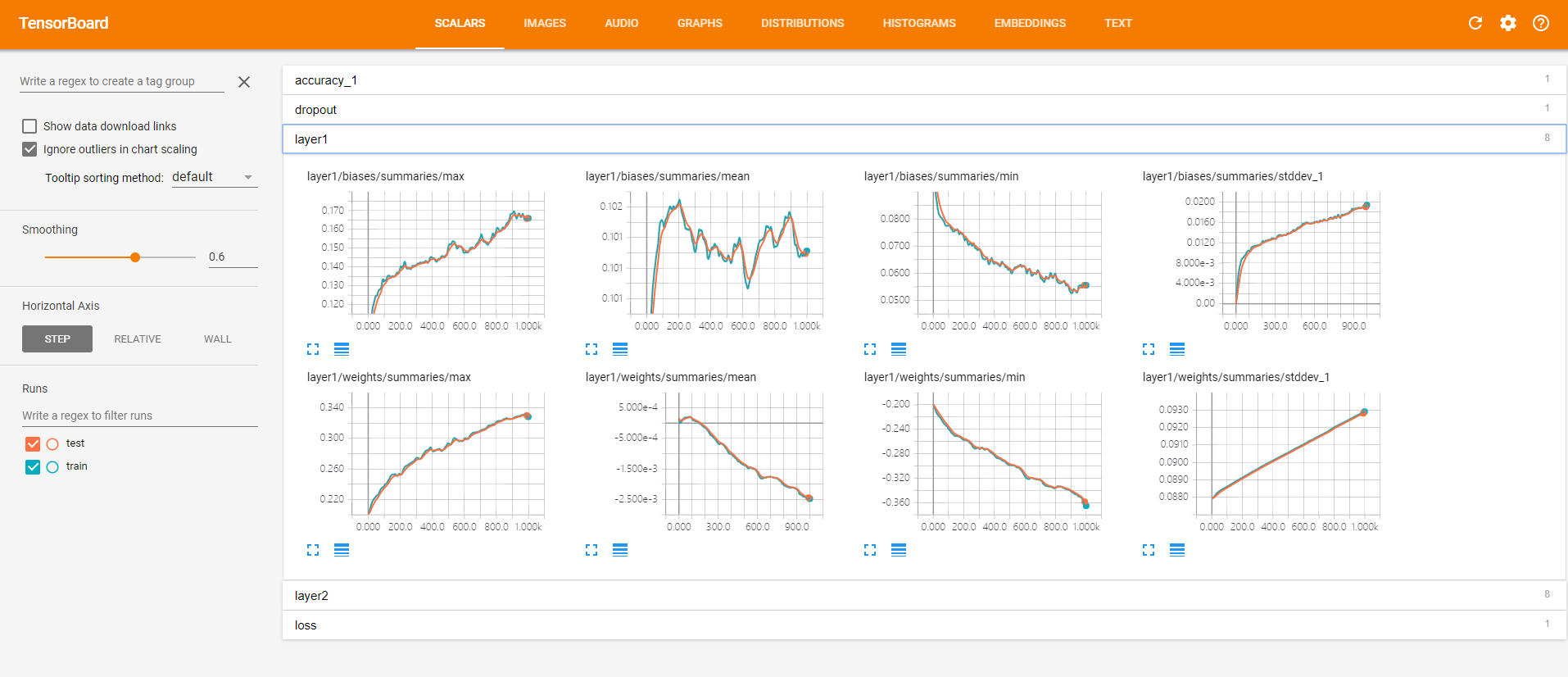
以上,第一排是偏执项b的信息,随着迭代的加深,最大值越来越大,最小值越来越小,与此同时,也伴随着方差越来越大,这样的情况是我们愿意看到的,神经元之间的参数差异越来越大。因为理想的情况下每个神经元都应该去关注不同的特征,所以他们的参数也应有所不同。
第二排是权值w的信息,同理,最大值,最小值,标准差也都有与b相同的趋势,神经元之间的差异越来越明显。w的均值初始化的时候是0,随着迭代其绝对值也越来越大。
点开layer2,查看第二层的参数信息。

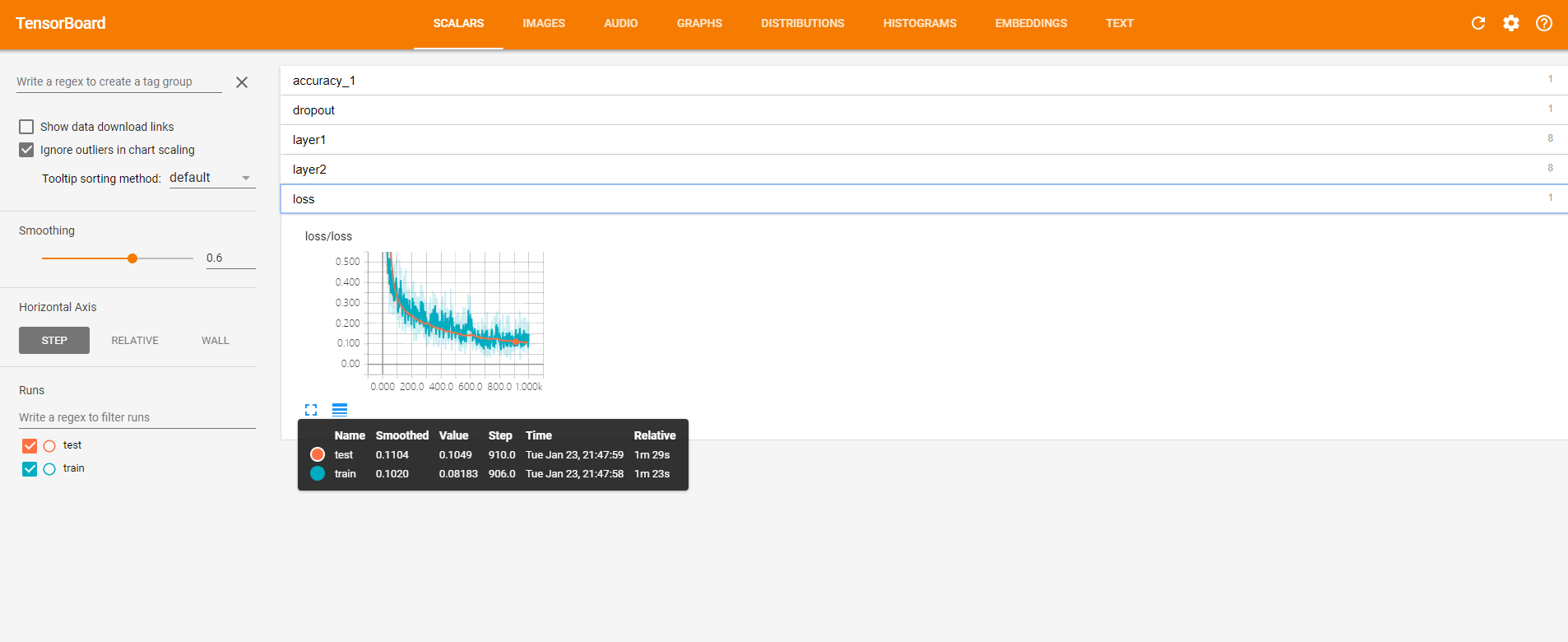
点开loss,可见损失的降低趋势。
(2)图片Images
在程序中我们设置了一处保存了图像信息,就是在转变了输入特征的shape,然后记录到了image中,于是在tensorflow中就会还原出原始的图片了:
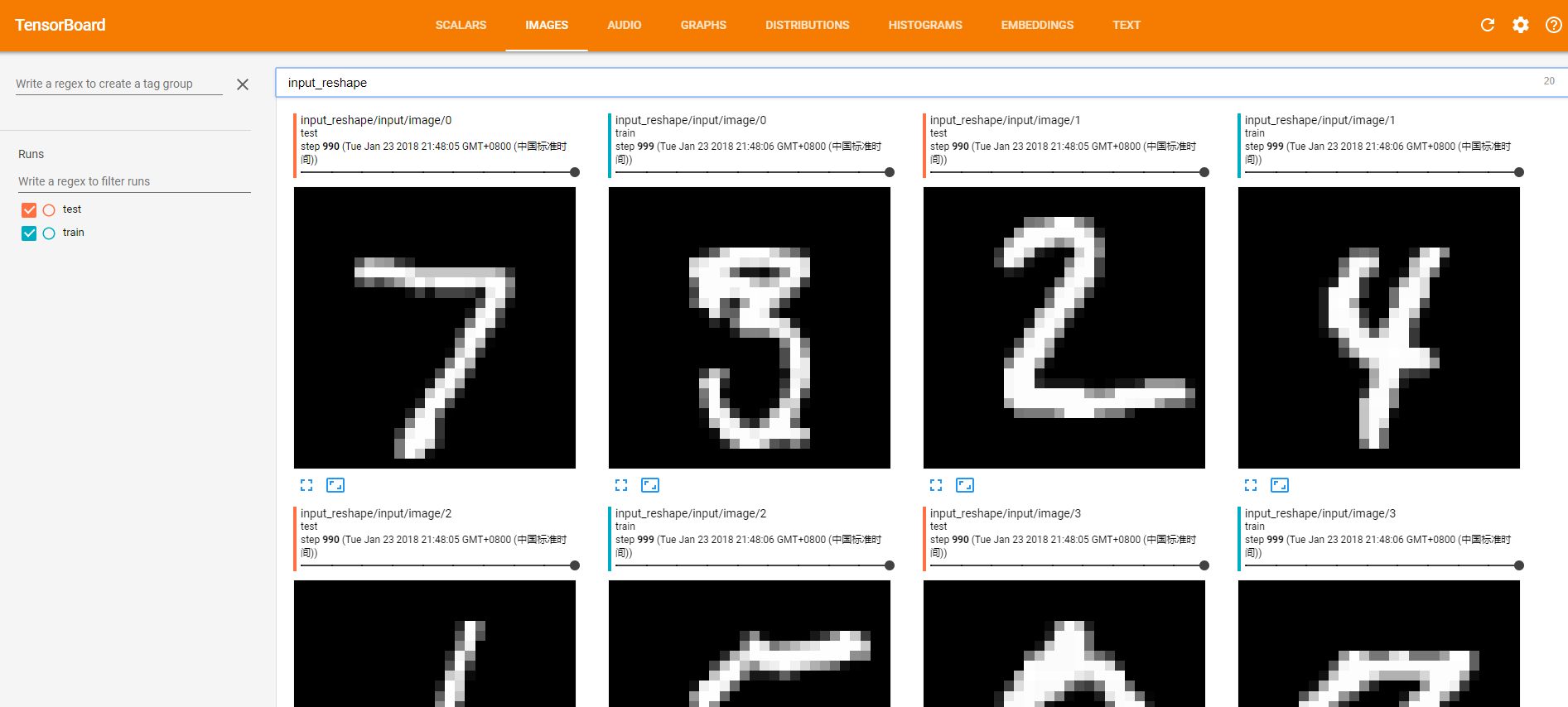
整个窗口总共展现了10张图片(根据代码中的参数10)
(3)音频Audio
这里展示的是声音的信息,但本案例中没有涉及到声音的。
(4)计算图Graph
这里展示的是整个训练过程的计算图graph,从中我们可以清洗地看到整个程序的逻辑与过程。
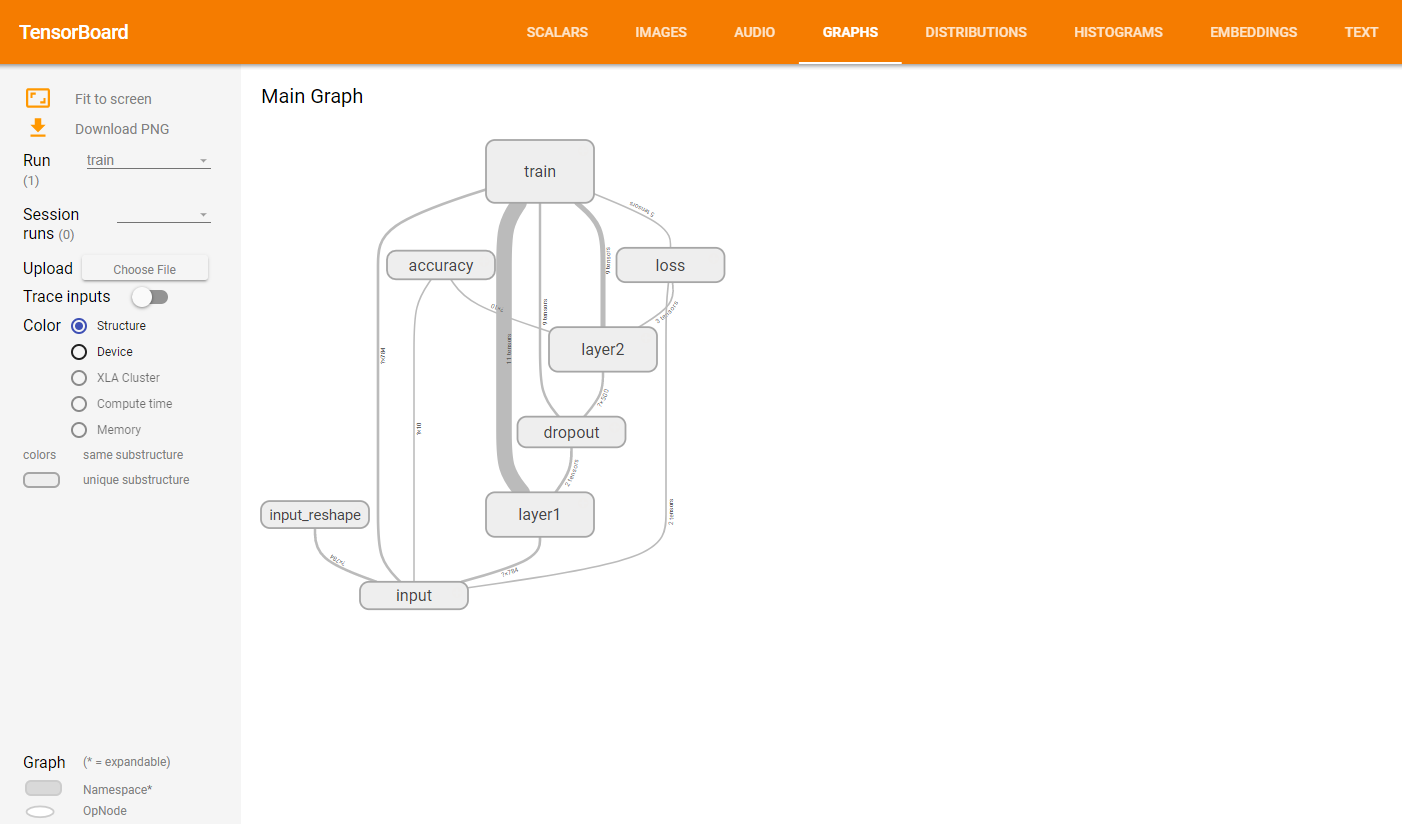
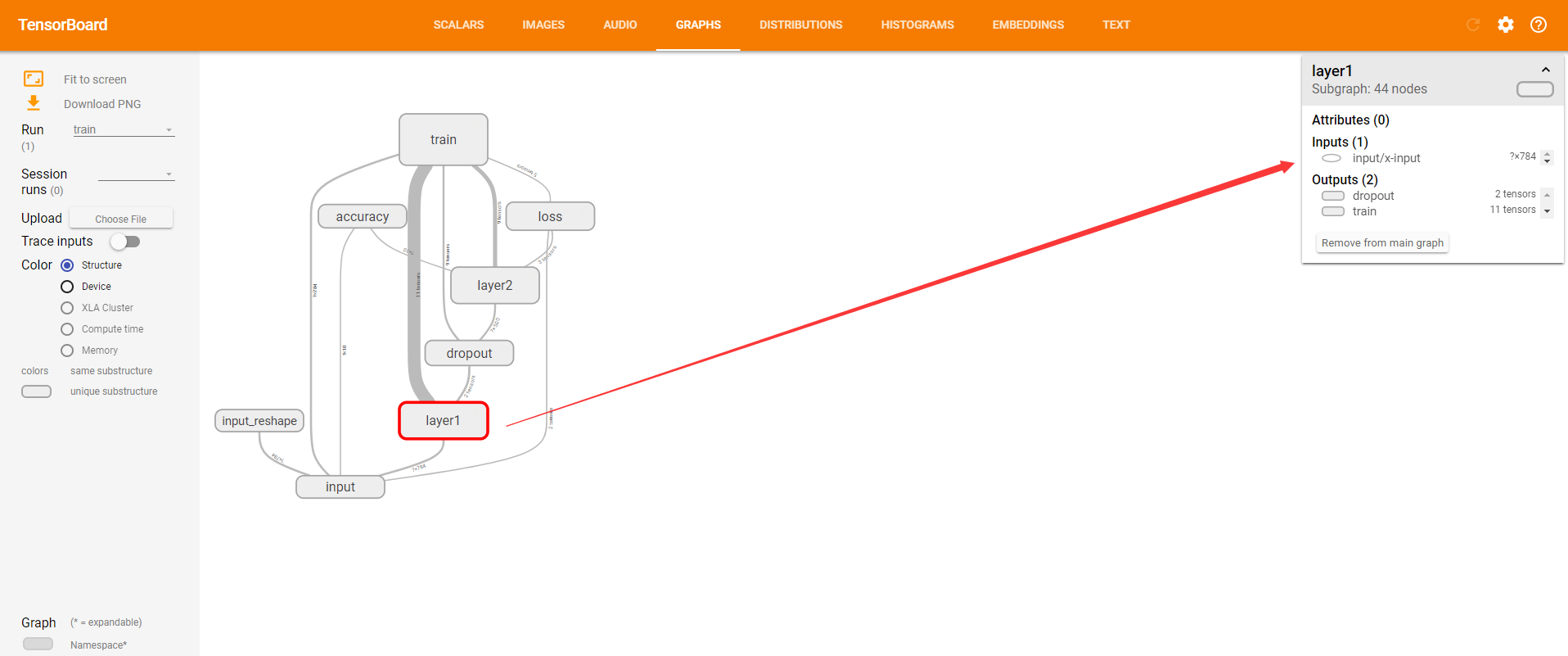
单击某个节点,可以查看属性,输入,输出等信息。
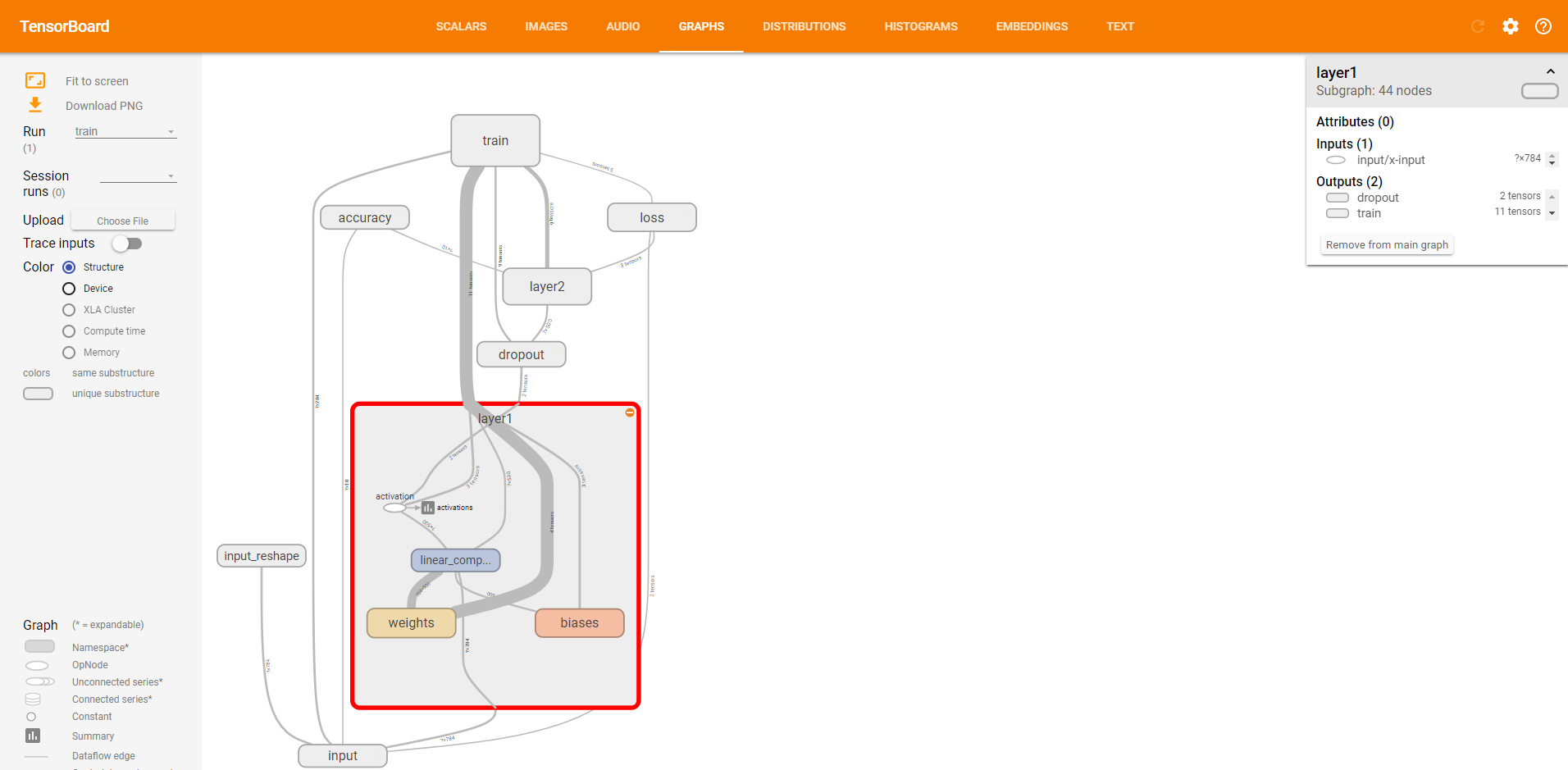
单击节点上的“+”字样,可以看到该节点的内部信息。
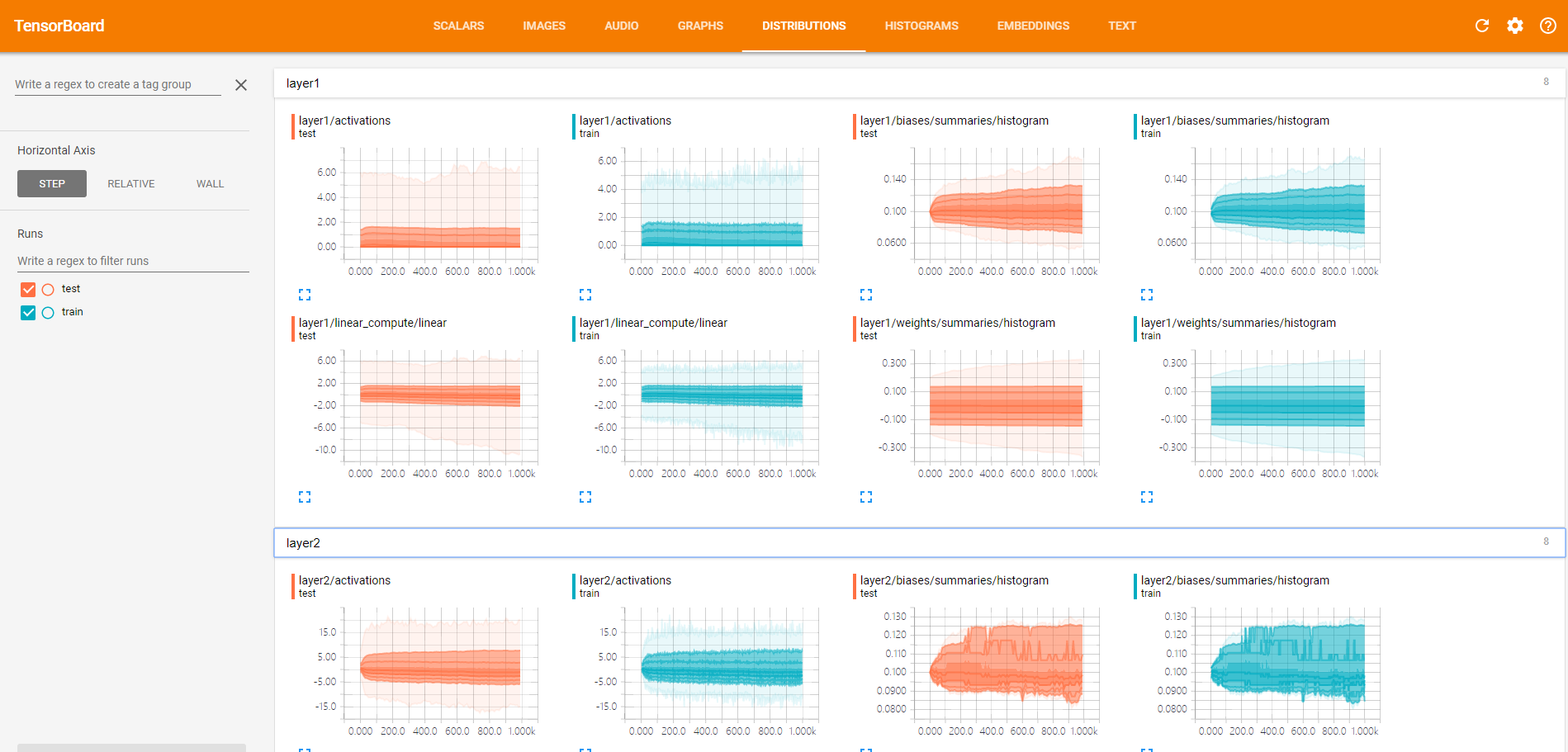
(5)数据分布Distribution
这里查看的是神经元输出的分布,有激活函数之前的分布,激活函数之后的分布等。
(6)直方图Histograms
也可以看以上数据的直方图
(7)嵌入向量Embeddings
展示的是嵌入向量的可视化效果,本案例中没有使用这个功能。
2、Tensorboard的可视化过程:
(1)首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息
(2)确定要在graph中的哪些节点放置summary operations以记录信息
- 使用tf.summary.scalar记录标量
- 使用tf.summary.histogram记录数据的直方图
- 使用tf.summary.distribution记录数据的分布图
- 使用tf.summary.image记录图像数据
(3)operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summary节点。但是呢,一份程序下来可能有超多这样的summary 节点,要手动一个一个去启动自然是及其繁琐的,因此我们可以使用tf.summary.merge_all去将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data。
(4)使用tf.summary.FileWriter将运行后输出的数据都保存到本地磁盘中
(5)运行整个程序,并在命令行输入运行tensorboard的指令,之后打开web端可查看可视化的结果
考虑多类情况。非onehot,标签是类似0 1 2 3...n这样。而onehot标签则是顾名思义,一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。例如在n为4的情况下,标签2对应的onehot标签就是 0.0 0.0 1.0 0.0使用onehot的直接原因是现在多分类cnn网络的输出通常是softmax层,而它的输出是一个概率分布,从而要求输入的标签也以概率分布的形式出现,进而算交叉熵之类。
参考文献: