一、RNN
1.展开图
(1)假设$x^{(t)}$为$t$时刻系统的外部驱动信号,则动态系统的状态为$h^{(t)}=f(h^{(t-1)},x^{(t)}; heta)$
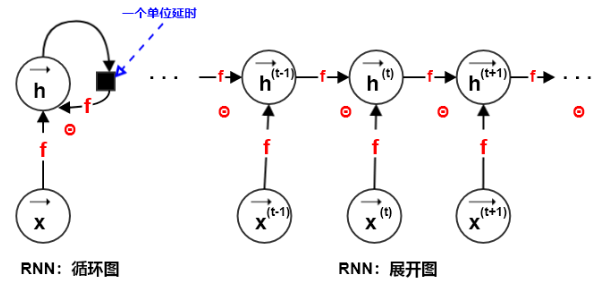
(2)当训练RNN根据过去预测未来时,网络通常要讲$h^{(t)}$作为过去序列信息的一个有损的representation,因为它使用一个固定长度的向量$h^{(t)}$来表达任意长的序列${x^{(1)},...,x^{(t-1)}}$
根据不同的训练准则,representation可能会有选择地保留过去序列的某些部分,如attention机制。
(3)网络的初始状态$h^{(0)}$的设置有两种方式:
- 固定为全0,模型的反向传播不需要考虑$h^{(0)}$,因为全0导致对应参数的梯度贡献也为0。
- 使用上一个样本的最后一个状态:$h_{(i+1)}^{(0)}=h_i^{( au_i)}$,这种场景通常是样本之间存在连续的关系(如:样本分别代表一篇小说中的每个句子),并且样本之间没有发生混洗的情况。此时,后一个样本的初始状态和前一个样本的最后状态可以认为保持连续性。
(4)展开图的两个主要优点:
- 无论输入序列的长度如何,学得的模型始终具有相同的输入大小。因为模型在每个时间步上,其模型的输入$x^{(t)}$都是相同大小的。
- 每个时间步上都使用相同的转移函数$f$,因此需要学得的参数$ heta$也就在每个时间步上共享。
这些优点直接导致了:
- 学习在所有时间步、所有序列长度上操作的单个函数f成为可能;
- 允许单个函数f泛化到没有见过的序列长度;
- 学习模型所需的训练样本远少于非参数共享的模型(如前馈神经网络)
2.网络模式
根据输入序列的长度,RNN网络模式可以划分为:输入序列长度为0、输入序列长度为1、输入序列为$ au$。