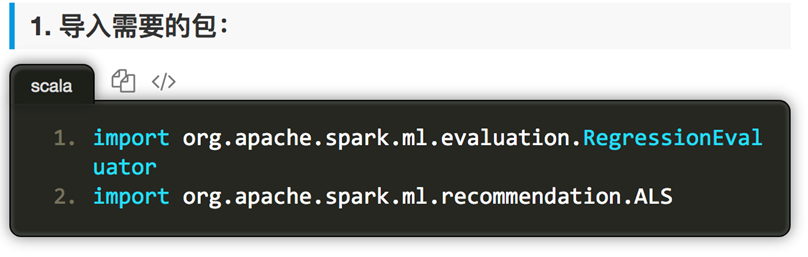
推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西。
- 基于内容的信息推荐方法的理论依据主要来自于信息检索和信息过滤。根据用户过去的浏览记录来向用户推荐用户没有接触过的推荐项。
- 基于协同过滤的推荐算法理论上可以推荐世界上的任何一种东西。图片、音乐、样样可以。 协同过滤算法主要是通过对未评分项进行评分 预测来实现的。
- 基于关联规则的推荐(Association Rule-based Recommendation)是以关联规则为基础,把已购商品作为规则头,规则体为推荐对象。
一、协同过滤
关于协同过滤的一个经典的例子就是看电影。如果你不知道哪一部电影是自己喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。
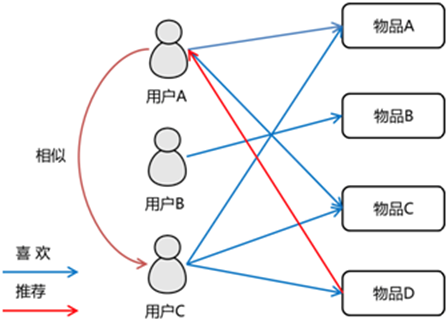
协同过滤算法主要分为基于用户的协同过滤算法和基于项目的协同过滤算法。MLlib当前支持基于模型的协同过滤,其中用户和商品通过一小组隐语义因子进行表达,并且这些因子也用于预测缺失的元素。
Spark MLlib实现了 交替最小二乘法 (ALS) 来学习这些隐性语义因子。
1.显现和隐性反馈
显性反馈行为包括用户明确表示对物品喜好的行为,隐性反馈行为指的是那些不能明确反应用户喜好的行为。
在许多的现实生活中的很多场景中,我们常常只能接触到隐性的反馈,例如页面游览,点击,购买,喜欢,分享等等。
基于矩阵分解的协同过滤的标准方法,一般将用户商品矩阵中的元素作为用户对商品的显性偏好。
在 MLlib 中所用到的处理这种数据的方法来源于文献: Collaborative Filtering for Implicit Feedback Datasets 。 评价就不是与用户对商品的显性评分,而是与所观察到的用户偏好强度关联起来。然后,这个模型将尝试找到隐语义因子来预估一个用户对一个商品的偏好。
二、ALS算法
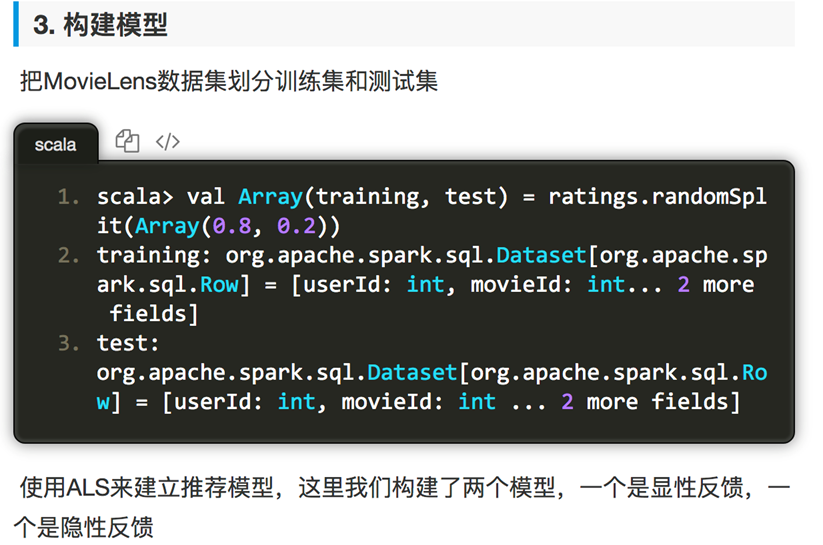
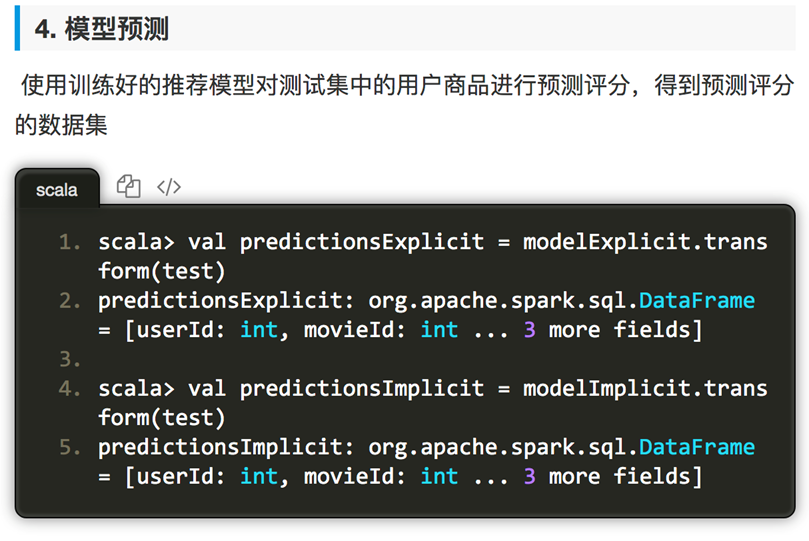
获取MovieLens数据集,其中每行包含一个用户、一个电影、一个该用户对该电影的评分以及时间戳。
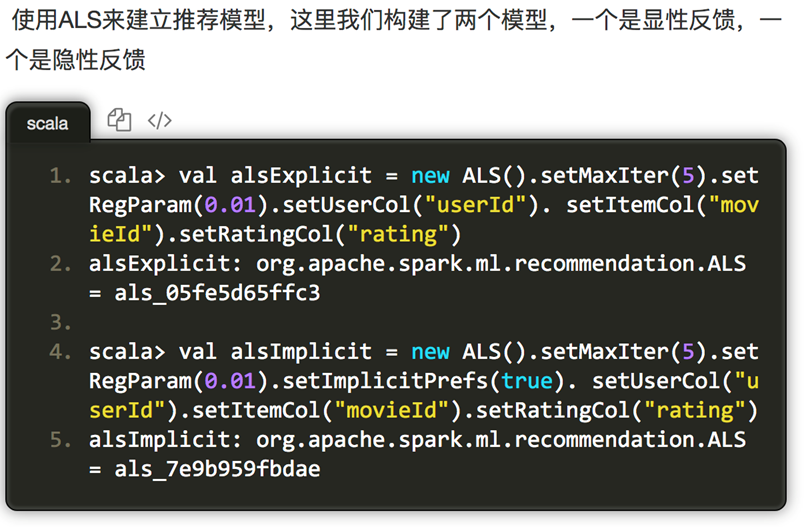
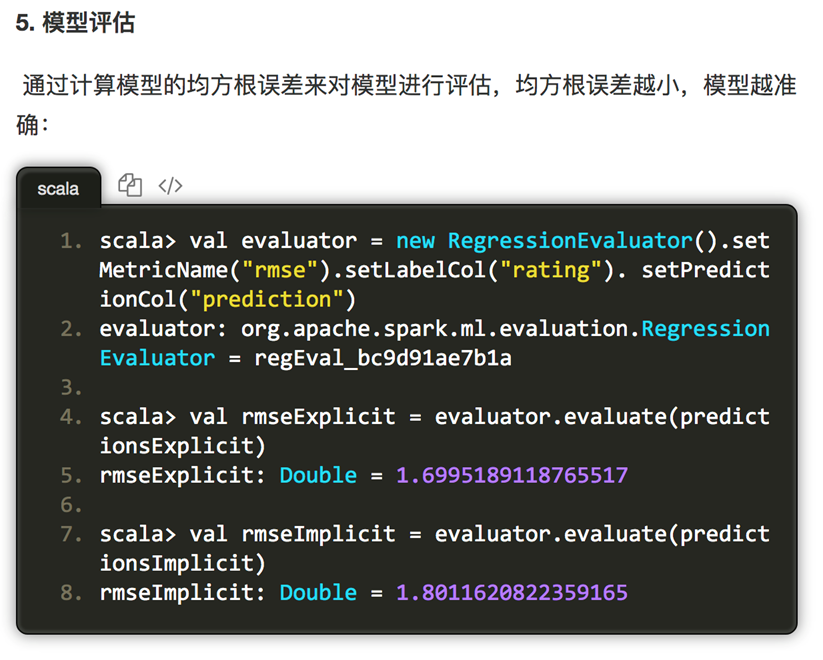
我们使用默认的ALS.train() 方法,即显性反馈(默认implicitPrefs 为false)来构建推荐模型并根据模型对评分预测的均方根误差来对模型进行评估。