一、数值运算
1.当进行数值运算时,pandas会按照标签对齐元素:运算符会对标签相同的两个元素进行计算。对于DataFrame,对齐会同时发生在行和列上。
- 当某一方的标签不存在时,默认以
NaN填充。缺失值会在运算过程中传播。(由于NaN是浮点数中的一个特殊值,因此结果的元素类型被转换为float64) - 结果的索引是双方索引的并集。
2.除了支持加减乘除等运算符之外,pandas还提供了对应的函数: add/sub/mul/div/mod(other, axis='columns', level=None, fill_value=None):
other:一个DataFrame/Series或者一个array-like,或者一个标量值axis:指定操作的轴。可以为0/1/'index'/'columns'。其意义是:操作发生在哪个轴上。fill_value:指定替换掉NaN的值。可以为None(不替换),或者一个浮点值。注意:如果发现两个NaN相加,则结果仍然还是NaN,而并不会是两个fill_value相加。level:一个整数或者label,用于多级索引的运算。
全部运算操作函数为:
1 add,sub,mul,div,truediv,floordiv,mod,pow,radd,rsub,rmul,rdiv,rtruediv, 2 rfloordiv,rmod,rpow # 这些的参数为 other,axis,level,fill_value 3 lt,gt,le,ge,ne,eq# 这些的参数为 ohter,axis,level
对于DataFrame和Series的运算,默认会用DataFrame的每一行与Series运算。如果你希望使用DataFrame的每一列与Series运算,则必须使用二元操作函数,并且指定axis=0(表示操作匹配的轴)。
举例:
idx1 = pd.Index(['a','b','c','d'],name='idx1')
idx2 = pd.Index(['a','b','c','e'],name='idx2')
s1 = pd.Series([1,2,3,4],index=idx1,name='sr1')
s2 = pd.Series([2,4,6,np.NaN],index=idx2,name='sr2')
print(s1,s2,sep='
-----------------------
')
idx1
a 1
b 2
c 3
d 4
Name: sr1, dtype: int64
-----------------------
idx2
a 2.0
b 4.0
c 6.0
e NaN
Name: sr2, dtype: float64
s1+s2 #直接相加,自动对齐相加
s1+s2 #直接相加,自动对齐相加
a 3.0
b 6.0
c 9.0
d NaN
e NaN
dtype: float64
# fill_value
s1.add(s2,fill_value=-100) # fill_value
a 3.0
b 6.0
c 9.0
d -96.0
e NaN
dtype: float64
2
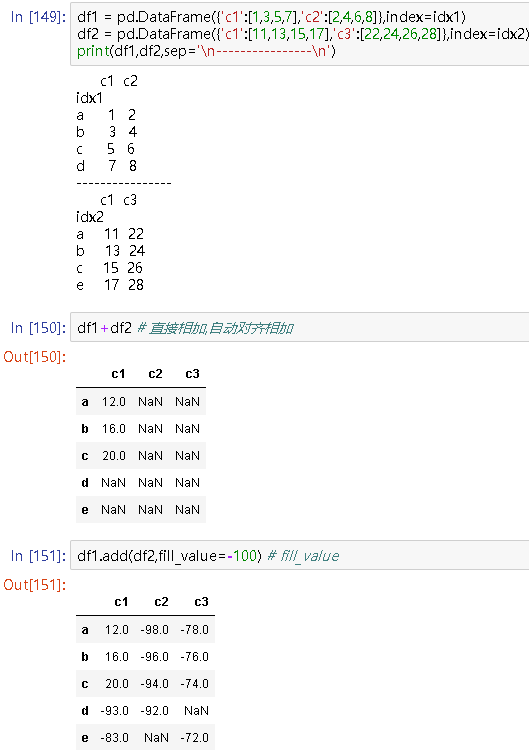
df1 = pd.DataFrame({'c1':[1,3,5,7],'c2':[2,4,6,8]},index=idx1)
df2 = pd.DataFrame({'c1':[11,13,15,17],'c3':[22,24,26,28]},index=idx2)
print(df1,df2,sep='
----------------
')
c1 c2
idx1
a 1 2
b 3 4
c 5 6
d 7 8
----------------
c1 c3
idx2
a 11 22
b 13 24
c 15 26
e 17 28
# 直接相加,自动对齐相加
df1+df2 # 直接相加,自动对齐相加
c1 c2 c3
a 12.0 NaN NaN
b 16.0 NaN NaN
c 20.0 NaN NaN
d NaN NaN NaN
e NaN NaN NaN
fill_value
df1.add(df2,fill_value=-100) # fill_value
c1 c2 c3
a 12.0 -98.0 -78.0
b 16.0 -96.0 -76.0
c 20.0 -94.0 -74.0
d -93.0 -92.0 NaN
e -83.0 NaN -72.0
df1 + df1.c1 # 广播
df1 + df1.c1 # 广播
a b c c1 c2 d
idx1
a NaN NaN NaN NaN NaN NaN
b NaN NaN NaN NaN NaN NaN
c NaN NaN NaN NaN NaN NaN
d NaN NaN NaN NaN NaN NaN
df1 + [-10,-11] # 广播,默认在列上进行
c1 c2
idx1
a -9 -9
b -7 -7
c -5 -5
d -3 -3
+ df1.c1 # 广播
df1 + df1.c1 # 广播
a b c c1 c2 d
idx1
a NaN NaN NaN NaN NaN NaN
b NaN NaN NaN NaN NaN NaN
c NaN NaN NaN NaN NaN NaN
d NaN NaN NaN NaN NaN NaN
# 在行上进行
df1.add([-10,-11,-12,-13],axis=0) # 在行上进行
c1 c2
idx1
a -9 -8
b -8 -7
c -7 -6
d -6 -5


二、排序
1.sort_index()
.sort_index()方法的作用是根据label排序(而不是对存放的数据排序)。
1 DataFrame/Series.sort_index(axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True)
参数:
axis:指定沿着那个轴排序。如果为0/'index',则对沿着0轴,对行label排序;如果为1/'columns',则沿着 1轴对列label排序。level:一个整数、label、整数列表、label list或者None。对于多级索引,它指定在哪一级上排序。ascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象kind:一个字符串,指定排序算法。可以为'quicksort'/'mergesort'/'heapsort'。注意只有归并排序是稳定排序的na_position:一个字符串,值为'first'/'last',指示:将NaN排在最开始还是最末尾。sort_remaining:一个布尔值。如果为True,则当多级索引排序中,指定level的索引排序完毕后,对剩下level的索引也排序。
举例:
import numpy as np
import pandas as pd
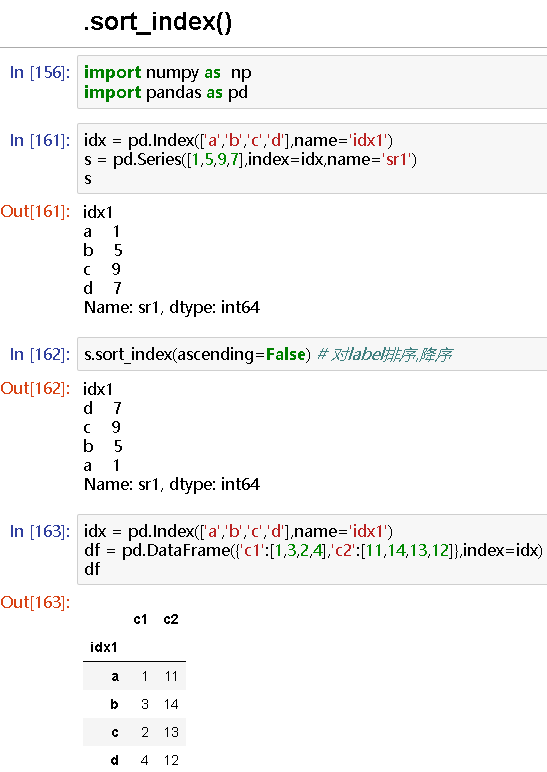
idx = pd.Index(['a','b','c','d'],name='idx1')
s = pd.Series([1,5,9,7],index=idx,name='sr1')
s
idx1
a 1
b 5
c 9
d 7
Name: sr1, dtype: int64
s.sort_index(ascending=False) # 对label排序,降序
idx1
d 7
c 9
b 5
a 1
Name: sr1, dtype: int64
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,3,2,4],'c2':[11,14,13,12]},index=idx)
df
c1 c2
idx1
a 1 11
b 3 14
c 2 13
d 4 12
df.sort_index(axis=0,ascending=False) # 对行label排序
c1 c2
idx1
d 4 12
c 2 13
b 3 14
a 1 11
df.sort_index(axis=1,ascending=False) # 对行label排序
c2 c1
idx1
a 11 1
b 14 3
c 13 2
d 12 4

2.sort_values()
.sort_values()方法的作用是根据元素值进行排序。
1 DataFrame/Series.sort_values(by, axis=0, ascending=True, inplace=False, 2 kind='quicksort', na_position='last') 3 Series.sort_values(axis=0, ascending=True, inplace=False, 4 kind='quicksort', na_position='last')
参数:
-
by:一个字符串或者字符串的列表,指定希望对那些label对应的列或者行的元素进行排序。对于DataFrame,必须指定该参数。而Series不能指定该参数。-
如果是一个字符串列表,则排在前面的
label的优先级较高。它指定了用于比较的字段
-
-
axis:指定沿着那个轴排序。如果为0/'index',则沿着0轴排序(此时by指定列label,根据该列的各元素大小,重排列各行);如果为1/'columns',则沿着 1轴排序(此时by指定行label,根据该行的各元素大小,重排列各列)。 -
ascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。 -
inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象 -
kind:一个字符串,指定排序算法。可以为'quicksort'/'mergesort'/'heapsort'。注意只有归并排序是稳定排序的 -
na_position:一个字符串,值为'first'/'last',指示:将NaN排在最开始还是最末尾。
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','b','c','d'],name='idx1')
s = pd.Series([1,5,9,7],index=idx,name='sr1')
s
idx1
a 1
b 5
c 9
d 7
Name: sr1, dtype: int64
s.sort_values(ascending=False) # 对value排序,降序
idx1
c 9
d 7
b 5
a 1
Name: sr1, dtype: int64
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,3,2,4],'c2':[11,14,13,12]},index=idx)
df
c1 c2
idx1
a 1 11
b 3 14
c 2 13
d 4 12
df.sort_values(by=['c1'],axis=0,ascending=False)
# 根据value对行排序,by指定了列label
c1 c2
idx1
d 4 12
b 3 14
c 2 13
a 1 11
df.sort_values(by=['c2','c1'],axis=0,ascending=False)
# 根据value对行排序,by指定了列label,c2的优先级较高
c1 c2
idx1
b 3 14
c 2 13
d 4 12
a 1 11


3.sortlevel()
1 DataFrame/Series.sortlevel(level=0, axis=0, ascending=True, inplace=False, sort_remaining=True)
根据单个level中的label对数据进行排列(稳定的)
axis:指定沿着那个轴排序。如果为0/'index',则沿着0轴排序 ;如果为1/'columns',则沿着 1轴排序level:一个整数,指定多级索引的levelascending:一个布尔值,如果为True,则升序排序;如果是False,则降序排序。inplace:一个布尔值,如果为True,则原地修改。如果为False,则返回排好序的新对象sort_remaining:一个布尔值。如果为True,则当多级索引排序中,指定level的索引排序完毕后,对剩下level的索引也排序。
举例:
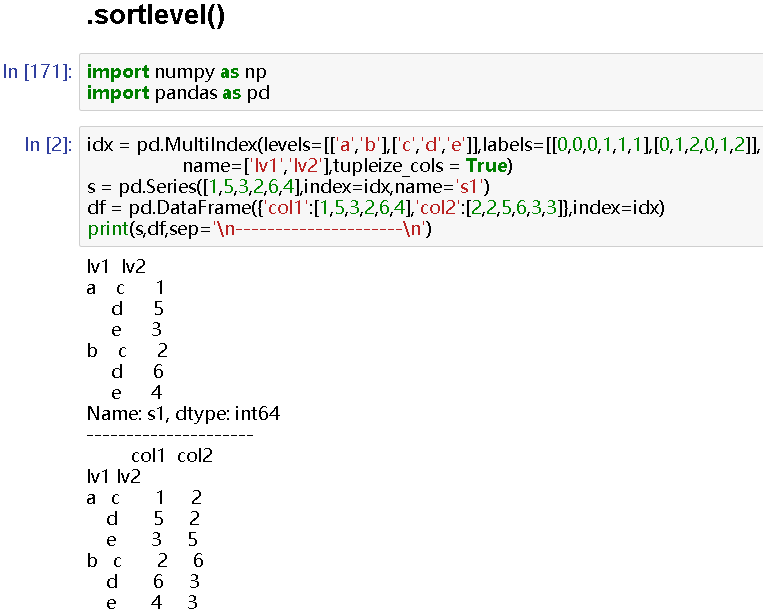
import numpy as np
import pandas as pd
idx = pd.MultiIndex(levels=[['a','b'],['c','d','e']],labels=[[0,0,0,1,1,1],[0,1,2,0,1,2]],
name=['lv1','lv2'],tupleize_cols = True)
s = pd.Series([1,5,3,2,6,4],index=idx,name='s1')
df = pd.DataFrame({'col1':[1,5,3,2,6,4],'col2':[2,2,5,6,3,3]},index=idx)
print(s,df,sep='
---------------------
')
# lv1 lv2
a c 1
d 5
e 3
b c 2
d 6
e 4
Name: s1, dtype: int64
---------------------
col1 col2
lv1 lv2
a c 1 2
d 5 2
e 3 5
b c 2 6
d 6 3
e 4 3
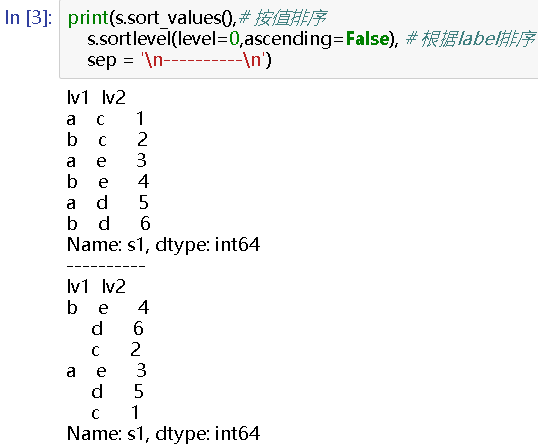
print(s.sort_values(),# 按值排序
s.sortlevel(level=0,ascending=False), # 根据label排序
sep = '
----------
')
# lv1 lv2
a c 1
b c 2
a e 3
b e 4
a d 5
b d 6
Name: s1, dtype: int64
----------
lv1 lv2
b e 4
d 6
c 2
a e 3
d 5
c 1
Name: s1, dtype: int64
df.sortlevel(level=0,ascending=False)
# col1 col2
lv1 lv2
b e 4 3
d 6 3
c 2 6
a e 3 5
d 5 2
c 1 2

4.rank()
.rank()方法的作用是在指定轴上计算各数值的排,其中相同数值的排名是相同的。
1 DataFrame/Series.rank(axis=0, method='average', numeric_only=None, 2 na_option='keep', ascending=True, pct=False)
参数:
-
axis:指定沿着那个轴排名。如果为0/'index',则沿着行排名(对列排名);如果为1/'columns',则沿着列排名(对行排名)。 -
method:一个字符串,指定相同的一组数值的排名。假设数值v一共有N个。现在轮到对v排序,设当前可用的排名为k。-
'average':为各个等值平均分配排名,这N个数的排名都是$frac{sum_{i=0}^{N-1}(K+i)}{N}=K+frac{N-1}{2}$ -
'min':使用可用的最小的排名,这N个数的排名都是k -
'max':使用可用的最大的排名,这N各数的排名都是k+N-1 -
'first:根据元素数据中出现的顺序依次分配排名,即按照它们出现的顺序,其排名分别为k,k+1,...k+N-1 -
'dense:类似于'min',但是排名并不会跳跃。即比v大的下一个数值排名为k+1,而不是k+N
-
-
numeric_only:一个布尔值。如果为True,则只对float/int/bool数据排名。仅对DataFrame有效 -
na_option:一个字符串,指定对NaN的处理。可以为:'keep':保留NaN在原位置'top':如果升序,则NaN安排最大的排名'bottom':如果升序,则NaN安排最小的排名
-
ascending:一个布尔值,如果为True,则升序排名;如果是False,则降序排名。 -
pct:一个布尔值。如果为True,则计算数据的百分位数,而不是排名。
举例:
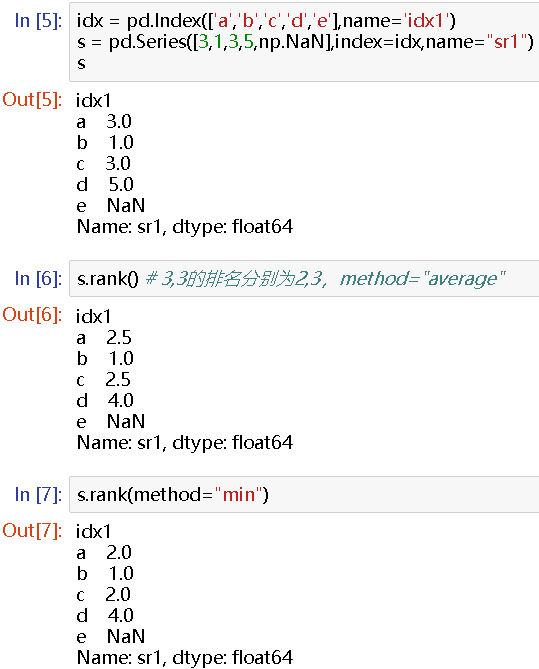
idx = pd.Index(['a','b','c','d','e'],name='idx1')
s = pd.Series([3,1,3,5,np.NaN],index=idx,name="sr1")
s
#idx1
a 3.0
b 1.0
c 3.0
d 5.0
e NaN
Name: sr1, dtype: float64
s.rank() # 3,3的排名分别为2,3,method="average"
#idx1
a 2.5
b 1.0
c 2.5
d 4.0
e NaN
Name: sr1, dtype: float64
s.rank(method="min")
#idx1
a 2.0
b 1.0
c 2.0
d 4.0
e NaN
Name: sr1, dtype: float64
s.rank(method="max")
#idx1
a 3.0
b 1.0
c 3.0
d 4.0
e NaN
Name: sr1, dtype: float64
s.rank(method="dense")
# idx1
a 2.0
b 1.0
c 2.0
d 3.0
e NaN
Name: sr1, dtype: float64
s.rank(pct=True) # 计算百分位
# idx1
a 0.625
b 0.250
c 0.625
d 1.000
e NaN
Name: sr1, dtype: float64
idx = pd.Index(['a','b','c','d'],name='idx1')
df = pd.DataFrame({'c1':[1,3,3,4],'c2':[11,14,14,12]},index=idx)
df
# c1 c2
idx1
a 1 11
b 3 14
c 3 14
d 4 12
df.rank(axis=0,method='min') # 沿着0轴排名(对列排名)
# c1 c2
idx1
a 1.0 1.0
b 2.0 3.0
c 2.0 3.0
d 4.0 2.0
1
df.rank(axis=1,method='min') # 沿着1轴排名(对行排名)
#c1 c2
idx1
a 1.0 2.0
b 1.0 2.0
c 1.0 2.0
d 1.0 2.0



三、统计
1.支持numpy的数组接口,直接使用ufunc函数
Series和DataFrame对象都支持Numpy的数组接口,因此可以直接使用Numpy提供的ufunc函数对它们进行运算。这些函数通常都有三个常用参数:
axis:指定运算沿着哪个轴进行level:如果轴是多级索引MultiIndex,则根据level分组计算skipna:运算是否自动跳过NaN
下面的方法使用如下的两个Series和DataFrame:
举例:
import numpy as np
import pandas as pd
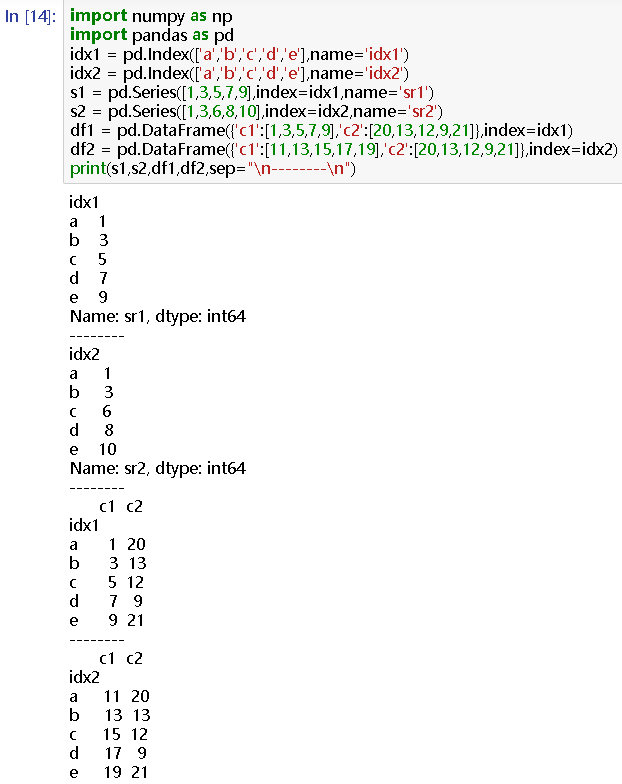
idx1 = pd.Index(['a','b','c','d','e'],name='idx1')
idx2 = pd.Index(['a','b','c','d','e'],name='idx2')
s1 = pd.Series([1,3,5,7,9],index=idx1,name='sr1')
s2 = pd.Series([1,3,6,8,10],index=idx2,name='sr2')
df1 = pd.DataFrame({'c1':[1,3,5,7,9],'c2':[20,13,12,9,21]},index=idx1)
df2 = pd.DataFrame({'c1':[11,13,15,17,19],'c2':[20,13,12,9,21]},index=idx2)
print(s1,s2,df1,df2,sep="
--------
")
idx1
a 1
b 3
c 5
d 7
e 9
Name: sr1, dtype: int64
--------
idx2
a 1
b 3
c 6
d 8
e 10
Name: sr2, dtype: int64
--------
c1 c2
idx1
a 1 20
b 3 13
c 5 12
d 7 9
e 9 21
--------
c1 c2
idx2
a 11 20
b 13 13
c 15 12
d 17 9
e 19 21
2.数值运算类方法
数值运算类方法:(下面的DataFrame方法对于Series也适用)
-
DataFrame.abs():计算绝对值(只对数值元素进行计算) -
DataFrame.all([axis, bool_only, skipna, level]):返回指定轴上:是否所有元素都为True或者非零。bool_only为True则仅考虑布尔型的数据。 -
DataFrame.any([axis, bool_only, skipna, level]):返回指定轴上:是否存在某个元素都为True或者非零。bool_only为True则仅考虑布尔型的数据。 -
DataFrame.clip([lower, upper, axis]):将指定轴上的数据裁剪到[lower,upper]这个闭区间之内。超过upper的值裁剪成upper;小于lower的值裁剪成lower。 -
DataFrame.clip_lower(threshold[, axis]):返回一份拷贝,该拷贝是在指定轴上:向下裁剪到threshold -
DataFrame.clip_upper(threshold[, axis]):返回一份拷贝,该拷贝是在指定轴上:向上裁剪到threshold -
DataFrame.prod([axis, skipna, level, ...]):计算指定轴上的乘积 -
DataFrame.sum([axis, skipna, level, ...]):沿着指定轴,计算样本的和 -
DataFrame.cumsum([axis, skipna]):计算沿着axis轴的累积和。 -
DataFrame.cumprod([axis, skipna]):计算沿着axis轴的累积乘积。 -
DataFrame.count([axis, level, numeric_only]):计算沿着axis轴,level级索引的非NaN值的数量。如果numeric_only为True,则只考虑数值和布尔类型。(对于Series,只有level一个参数。) -
DataFrame.round([decimals]):对元素指定小数点位数。decimals可以为一个整数(所有的元素都按照该小数点位数)、一个字典(根据列label指定)
举例:
import numpy as np
import pandas as pd
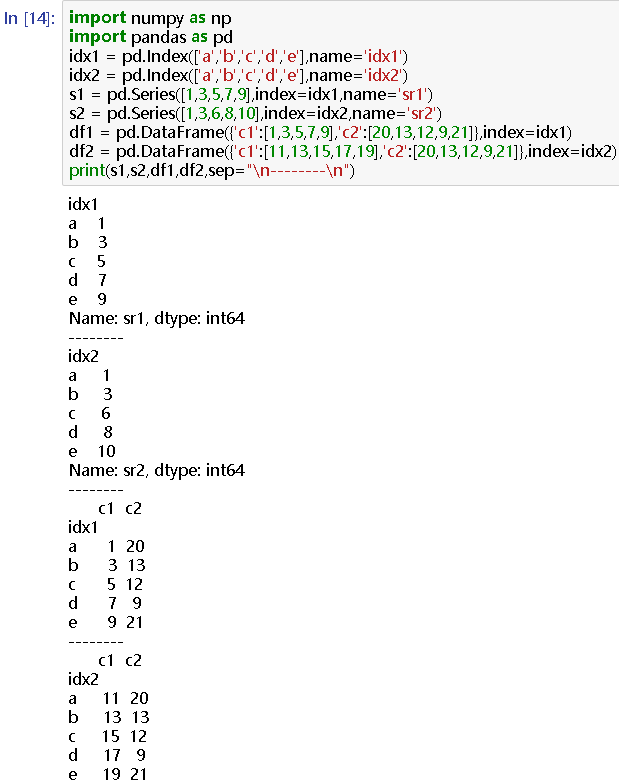
idx1 = pd.Index(['a','b','c','d','e'],name='idx1')
idx2 = pd.Index(['a','b','c','d','e'],name='idx2')
s1 = pd.Series([1,3,5,7,9],index=idx1,name='sr1')
s2 = pd.Series([1,3,6,8,10],index=idx2,name='sr2')
df1 = pd.DataFrame({'c1':[1,3,5,7,9],'c2':[20,13,12,9,21]},index=idx1)
df2 = pd.DataFrame({'c1':[11,13,15,17,19],'c2':[20,13,12,9,21]},index=idx2)
print(s1,s2,df1,df2,sep="
--------
")
# idx1
a 1
b 3
c 5
d 7
e 9
Name: sr1, dtype: int64
--------
idx2
a 1
b 3
c 6
d 8
e 10
Name: sr2, dtype: int64
--------
c1 c2
idx1
a 1 20
b 3 13
c 5 12
d 7 9
e 9 21
--------
c1 c2
idx2
a 11 20
b 13 13
c 15 12
d 17 9
e 19 21
print(df1.all(axis=0),df1.all(axis=1),sep='
-----
')
# c1 True
c2 True
dtype: bool
-----
idx1
a True
b True
c True
d True
e True
dtype: bool
print(df1.clip(2,8,axis=0),df1.clip(2,8,axis=1),sep='
-----
')
# c1 c2
idx1
a 2 8
b 3 8
c 5 8
d 7 8
e 8 8
-----
c1 c2
idx1
a 2 8
b 3 8
c 5 8
d 7 8
e 8 8
print(df1.prod(axis=0),df1.prod(axis=1),sep='
-----
')
# c1 945
c2 589680
dtype: int64
-----
idx1
a 20
b 39
c 60
d 63
e 189
dtype: int64
print(df1.sum(axis=0),df1.sum(axis=1),sep='
-----
')
# c1 25
c2 75
dtype: int64
-----
idx1
a 21
b 16
c 17
d 16
e 30
dtype: int64
print(df1.cumsum(axis=0),df1.cumsum(axis=1),sep='
-----
')
# c1 c2
idx1
a 1 20
b 4 33
c 9 45
d 16 54
e 25 75
-----
c1 c2
idx1
a 1 21
b 3 16
c 5 17
d 7 16
e 9 30
print(df1.count(axis=0),df1.count(axis=1),sep='
-----
')
# c1 5
c2 5
dtype: int64
-----
idx1
a 2
b 2
c 2
d 2
e 2
dtype: int64



3.最大最小
最大最小:(下面的DataFrame方法对于Series也适用)
-
DataFrame.max([axis, skipna, level, ...]): 沿着指定轴,计算最大值 -
DataFrame.min([axis, skipna, level, ...]): 沿着指定轴,计算最小值 -
Series.argmax([axis, skipna, ...]): 计算最大值的索引位置(一个整数值)pandas 0.20 以后,它返回的不再是索引位置,而是索引 label,等价于 idxmax
-
Series.argmin([axis, skipna, ...]): 计算最小值的索引位置(一个整数值)pandas 0.20 以后,它返回的不再是索引位置,而是索引 label,等价于 idxmin
-
Series.idxmax([axis, skipna, ...]): 计算最大值的索引label -
Series.idxmin([axis, skipna, ...]): 计算最小值的索引label -
DataFrame.cummax([axis, skipna]):计算沿着axis轴的累积最大值。 -
DataFrame.cummin([axis, skipna]):计算沿着axis轴的累积最最小值。 -
DataFrame.quantile([q, axis, numeric_only, ...]):计算指定轴上样本的百分位数。q为一个浮点数或者一个array-like。每个元素都是0~1之间。如 0.5代表 50%分位 -
DataFrame.rank([axis, method, numeric_only, ...]):计算指定轴上的排名。 -
DataFrame.pct_change([periods, fill_method, ...]):计算百分比变化。periods为相隔多少个周期。它计算的是:(s[i+periods]-s[i])/s[i],注意结果并没有乘以 100。 -
Series.nlargest( *args,**kwargs):计算最大的N个数。参数为:n:最大的多少个数keep:遇到重复值时怎么处理。可以为:'first'/'last'。
-
Series.nsmallest( *args,**kwargs):计算最小的N个数。参数同上。
举例:
print(df1,df2,sep='
---------
')
c1 c2
idx1
a 1 2
b 3 5
c 5 7
d 7 9
e 9 11
---------
c1 c2
idx2
a 11 20
b 13 13
c 15 12
d 17 9
e 19 21
print(df1.max(axis=0),df1.max(axis=1),sep="
----------
")
c1 9
c2 11
dtype: int64
----------
idx1
a 2
b 5
c 7
d 9
e 11
dtype: int64
print(s1.max(),s1.argmax(),s1.idxmax(),sep=",")
9,e,e
print(df1.cummin(axis=0),df1.cummin(axis=1),sep="
----------
")
c1 c2
idx1
a 1 2
b 1 2
c 1 2
d 1 2
e 1 2
----------
c1 c2
idx1
a 1 1
b 3 3
c 5 5
d 7 7
e 9 9
print(df1.quantile(0.5,axis=0),df1.quantile(0.5,axis=1),sep="
----------
")
c1 5.0
c2 7.0
Name: 0.5, dtype: float64
----------
idx1
a 1.5
b 4.0
c 6.0
d 8.0
e 10.0
Name: 0.5, dtype: float64
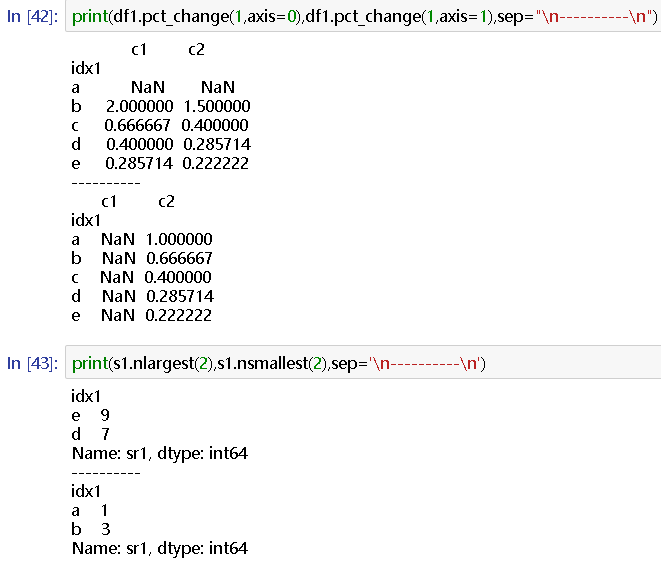
print(df1.pct_change(1,axis=0),df1.pct_change(1,axis=1),sep="
----------
")
c1 c2
idx1
a NaN NaN
b 2.000000 1.500000
c 0.666667 0.400000
d 0.400000 0.285714
e 0.285714 0.222222
----------
c1 c2
idx1
a NaN 1.000000
b NaN 0.666667
c NaN 0.400000
d NaN 0.285714
e NaN 0.222222
print(s1.nlargest(2),s1.nsmallest(2),sep='
----------
')
idx1
e 9
d 7
Name: sr1, dtype: int64
----------
idx1
a 1
b 3
Name: sr1, dtype: int64


4.统计类方法
统计类方法:(下面的DataFrame方法对于Series也适用)
-
DataFrame.mean([axis, skipna, level, ...]):沿着指定轴,计算平均值 -
DataFrame.median([axis, skipna, level, ...]):沿着指定轴,计算位于中间大小的数 -
DataFrame.var([axis, skipna, level, ddof, ...]):沿着指定轴,计算样本的方差 -
DataFrame.std([axis, skipna, level, ddof, ...]):沿着指定轴,计算样本的标准差 -
DataFrame.mad([axis, skipna, level]):沿着指定轴,根据平均值计算平均绝对离差 -
DataFrame.diff([periods, axis]):沿着指定轴的一阶差分。periods为间隔。 -
DataFrame.skew([axis, skipna, level, ...]):沿着指定轴计算样本的偏度(二阶矩) -
DataFrame.kurt([axis, skipna, level, ...]):沿着指定轴,计算样本的峰度(四阶矩)- 对随机变量X,$E(X^K),K=1,2,...$若存在,则称它为$X$的$k$阶原点矩,简称$k$阶矩。若$Eleft[(X-E(X))^{k} ight], k=1,2, cdots$存在,则称它为X的k阶中心矩。
-
DataFrame.describe([percentiles, include, ...]):获取顺序统计量以及其他的统计结果。percentiles:一个array-like。每个元素都是0~1之间。如 0.5代表 50%分位include,exclude:指定包含/不包含哪些列(通过dtype来指定)。可以为None/'all',或者一个dtype列表
-
DataFrame.corr([method, min_periods]):计算任意两个列之间的非NAN的、按照索引对齐的值的相关系数。method为相关系数的类型,可以为:'pearson':标准的相关系数'kendall':Kendall Tau相关系数'spearman':Spearman rank相关系数
而
min_periods:一个整数。它指定为了生成一个有效的相关系数,每一对列数据的最短长度。 -
DataFrame.corrwith(other[, axis, drop]):计算两个DataFrame的行-行、列-列的相关系数。axis:如果为0/'index'则沿着0轴,则计算列-列之间的相关系数。如果为1/'columns',则沿着1轴,计算行-行之间的相关系数drop:一个布尔值。如果为True,则如果某行/列都是NaN,则抛弃该行/列。如果为False,则返回全部。
-
DataFrame.cov([min_periods]):计算任意两列之间的协方差。min_periods指定为了生成一个有效的协方差,每一对列数据的最短长度。- 对于
Series,其调用为:Series.cov(other,[min_periods])
- 对于
举例:
print(df1.mean(axis=0),df1.mean(axis=1),sep=" -------------- ") #c1 5.0 c2 6.8 dtype: float64 -------------- idx1 a 1.5 b 4.0 c 6.0 d 8.0 e 10.0 dtype: float64 print(df1.var(axis=0),df1.var(axis=1),sep=" -------------- ") #c1 10.0 c2 12.2 dtype: float64 -------------- idx1 a 0.5 b 2.0 c 2.0 d 2.0 e 2.0 dtype: float64 print(df1.mad(axis=0),df1.mad(axis=1),sep=" -------------- ") #c1 2.40 c2 2.64 dtype: float64 -------------- idx1 a 0.5 b 1.0 c 1.0 d 1.0 e 1.0 dtype: float64 print(df1.skew(axis=0),df1.skew(axis=1),sep=" -------------- ") #c1 0.000000 c2 -0.309766 dtype: float64 -------------- idx1 a NaN b NaN c NaN d NaN e NaN dtype: float64 df1.kurt(axis=0) c1 -1.200000 c2 -0.643644 dtype: float64 df1.describe([0.2,0.5]) c1 c2 count 5.000000 5.00000 mean 5.000000 6.80000 std 3.162278 3.49285 min 1.000000 2.00000 20% 2.600000 4.40000 50% 5.000000 7.00000 max 9.000000 11.00000 df1.corr() #c1 c2 c1 1.000000 0.995893 c2 0.995893 1.000000 print(df1.corrwith(df2,axis=0),df1.corrwith(df2,axis=1),sep=' ----------- ') #c1 1.000000 c2 -0.122839 dtype: float64 ----------- a 1.0 b NaN c -1.0 d -1.0 e 1.0 dtype: float64 df1.cov() #c1 c2 c1 10.0 11.0 c2 11.0 12.2




5.唯一值、值计数、成员资格
-
Series.unique():返回Series中唯一值组成的一维ndarray -
Series.value_counts(normalize=False, sort=True, ascending=False,bins=None, dropna=True):对Series中的数进行计数。如果normalize为True,则返回频率而不是频数。sort为True则结果根据出现的值排序,排序方式由ascending指定。bins是一个整数或者None。如果它为整数,则使用半开半闭区间来统计,它给出了该区间的数量。
-
Series.isin(values):返回一个布尔数组,给出Series中各值是否位于values中。DataFrame也有此方法。
举例:
s2 #idx2 a 1 b 3 c 6 d 8 e 10 Name: sr2, dtype: int64 s2.unique() #array([ 1, 3, 6, 8, 10], dtype=int64) s2.value_counts() #6 1 3 1 10 1 1 1 8 1 Name: sr2, dtype: int64 s2.isin([1,2,3,4,5,6]) #idx2 a True b True c True d False e False Name: sr2, dtype: bool

6.多级索引
对于多级索引,可以通过level参数来指定在某个轴上的操作索引级别。如果level=None,则不考虑索引的多级。
idx3 = pd.MultiIndex.from_tuples([('a','c'),('a','d'),('a','e'),
('b','c'),('b','d'),('b','e')],names=['lv0','lv1'])
s3 = pd.Series([1,3,5,7,9,11],index=idx3)
s3
# lv0 lv1
a c 1
d 3
e 5
b c 7
d 9
e 11
dtype: int64
print(s3.sum(level=0),s3.sum(level=1),s3.sum(level=None),sep='
----------
')
# lv0
a 9
b 27
dtype: int64
----------
lv1
c 8
d 12
e 16
dtype: int64
----------
36
