一、索引和轴的变换
1.重新索引:reindex
1 Series/DataFrame.reindex(index=None, **kwargs):
参数:
-
index:一个array-like对象,给出了新的index的label -
method:当新的label的值缺失时,如何处理。参数值可以为:None:不做任何处理,缺失地方填充NaN'backfill'/'bfill':用下一个可用的值填充该空缺(后向填充)'pad'/'ffill':用上一个可用的值填充该空缺(前向填充)'nearest':用最近的可用值填充该空缺
-
copy:一个布尔值,如果为True,则返回一个新的Series对象(即使传入的index与原来的index相同) -
level:一个整数或者name,在MultiIndex的指定级别上匹配简单索引 -
fill_value:一个标量。指定缺失值的填充数据,默认为NaN(如果该参数与method同时出现,则以method为主) -
limit:一个整数,指定前向/后向填充时:如果有连续的k个NaN,则只填充其中limit个。它与method配合 -
tolerance:一个整数,用于给出在不匹配时,连续采用前向/后向/最近邻匹配的跨度的最大值。它与method配合
对于DataFrame,多了关键字参数:
columns:一个array-like对象,给出了新的columns的label
对于DataFrame,如果.reindex()只传入一个序列,则默认会重索引行label。如果同时重索引行label和列label,则method插值只能按照行来进行(即 0 轴)
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','c','d','f','p'],name='idx1')
s = pd.Series([1,5,3,2,6],index=idx,name='s1')
df = pd.DataFrame({'col1':[1,5,3,2,6],'col3':[2,2,5,6,3]},index=idx)
print(s,df,sep='
---------------------
')
# idx1
a 1
c 5
d 3
f 2
p 6
Name: s1, dtype: int64
---------------------
col1 col3
idx1
a 1 2
c 5 2
d 3 5
f 2 6
p 6 3
print(s.reindex(['a','b','i'],method=None),
s.reindex(['a','b','i'],method='bfill'),
s.reindex(['a','b','i'],method='ffill'),
s.reindex(['a','b','i'],fill_value=-1),
sep='
------------------
')
# idx1
a 1.0
b NaN
i NaN
Name: s1, dtype: float64
------------------
idx1
a 1
b 5
i 6
Name: s1, dtype: int64
------------------
idx1
a 1
b 1
i 2
Name: s1, dtype: int64
------------------
idx1
a 1
b -1
i -1
Name: s1, dtype: int64
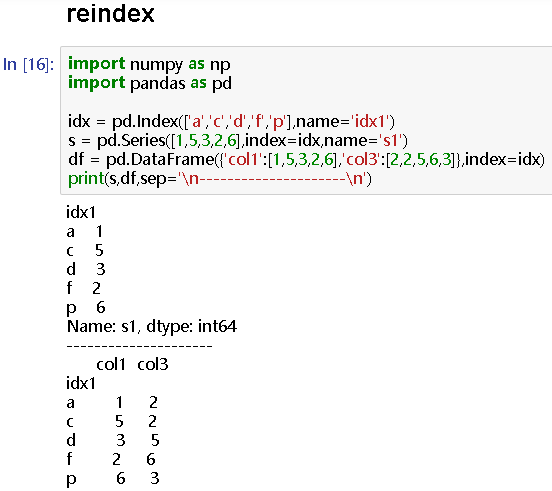
df.reindex(index=['a','b','c'],columns=['col1','col2','col3'],fill_value=-1)
# col1 col2 col3
idx1
a 1 -1 2
b -1 -1 -1
c 5 -1 2
df.reindex(['a','b','c'],fill_value=-1)#默认索引index
# col1col3idx1a12b-1-1c52
df.reindex(index=['a','b','c'],columns=['col1','col2','col3'],method='ffill')#同时有行和列,则method作用于0轴
# col1 col2 col3
idx1
a 1 1 2
b 1 1 2
c 5 5 2


2.列数据变成行索引:set_index
将列数据变成行索引(只对DataFrame有效,因为Series没有列索引),其中:col label变成index name,列数据变成行label:
1 DataFrame.set_index(keys, drop=True, append=False, inplace=False,
2 verify_integrity=False)
参数:
keys: 指定了一个或者一列的column label。这些列将会转换为行indexdrop:一个布尔值。如果为True,则keys对应的列会被删除;否则这些列仍然被保留append:一个布尔值。如果为True,则原有的行索引将保留(此时一定是个多级索引);否则抛弃原来的行索引。inplace:一个布尔值。如果为True,则原地修改并且返回Noneverify_integrity:一个布尔值。如果为True,则检查新的index是否有重复值。否则会推迟到检测过程到必须检测的时候。
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','c','d','f'],name='idx1')
df = pd.DataFrame({'col1':[1,5,3,2],'col2':[2,1,5,7],'col3':[3,2,5,8]},index=idx)
df
#
col1 col2 col3
idx1
a 1 2 3
c 5 1 2
d 3 5 5
f 2 7 8
df2 = df.set_index(keys=['col1','col2'])
df2 # 行索引变成了一个多级索引,第一级为col1,第二级为col2
# col3
col1 col2
1 2 3
5 1 2
3 5 5
2 7 8
print(df.set_index(keys='col1',drop=False),
df.set_index(keys='col1',append=True),sep='
----------
')
# col1 col2 col3
col1
1 1 2 3
5 5 1 2
3 3 5 5
2 2 7 8
----------
col2 col3
idx1 col1
a 1 2 3
c 5 1 2
d 3 5 5
f 2 7 8
type(df2.index)
# pandas.core.indexes.multi.MultiIndex


3.将层次化的行index转移到列中,成为新的一列:reset_index
reset_index会将层次化的行index转移到列中,成为新的一列。同时index 变成一个整数型的,从0开始编号:
1 DataFrame.reset_index(level=None, drop=False, inplace=False,
2 col_level=0, col_fill='')
3 Series.reset_index(level=None, drop=False, name=None, inplace=False)
参数:
level:一个整数、str、元组或者列表。它指定了将从层次化的index中移除的level。如果为None,则移除所有的leveldrop:一个布尔值。如果为True,则并不会插入新的列。如果为False,则插入新的列(由index,组成,其列名为'index')。inplace:一个布尔值。如果为True,则原地修改并且返回Nonecol_level:如果列索引也是多层次的,则决定插入到列索引的哪个level。col_fill:如果列索引也是多层次的,则决定插入之后其他level的索引如何命名的。默认情况下就是重复该index name
对于Series,name就是插入后,对应的列label。
4.丢弃某条轴上的一个或者多个label:drop
1 Series/DataFrame.drop(labels[, axis, level, inplace, errors])
参数:
labels:单个label或者一个label序列,代表要被丢弃的labelaxis:一个整数,或者轴的名字。默认为 0 轴level:一个整数或者level名字,用于MultiIndex。因为可能在多个level上都有同名的label。inplace:一个布尔值。如果为True,则原地修改并且返回Noneerrors:可以为'ignore'/'raise'
举例:
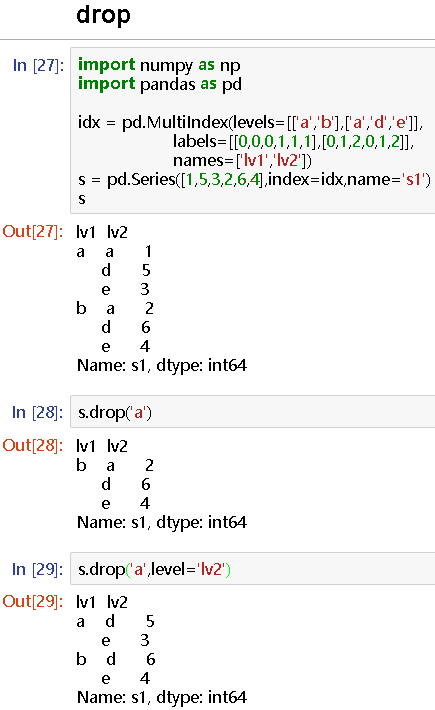
import numpy as np
import pandas as pd
idx = pd.MultiIndex(levels=[['a','b'],['a','d','e']],
labels=[[0,0,0,1,1,1],[0,1,2,0,1,2]],
names=['lv1','lv2'])
s = pd.Series([1,5,3,2,6,4],index=idx,name='s1')
s
# lv1 lv2
a a 1
d 5
e 3
b a 2
d 6
e 4
Name: s1, dtype: int64
s.drop('a')
# lv1 lv2
b a 2
d 6
e 4
Name: s1, dtype: int64
s.drop('a',level='lv2')
# lv1 lv2
a d 5
e 3
b d 6
e 4
Name: s1, dtype: int64
5.转置DataFrame:.T
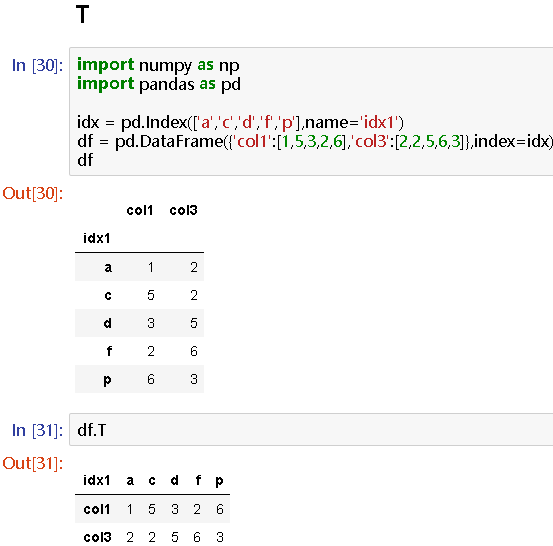
DataFrame的.T方法会对DataFrame进行转置,使得行与列互换(行索引与列索引也互换)
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','c','d','f','p'],name='idx1')
df = pd.DataFrame({'col1':[1,5,3,2,6],'col3':[2,2,5,6,3]},index=idx)
df
# col1 col3
idx1
a 1 2
c 5 2
d 3 5
f 2 6
p 6 3
df.T
# idx1 a c d f p
col1 1 5 3 2 6
col3 2 2 5 6 3
6.交换两个轴:swapaxes
1 DataFrame/Series.swapaxes(axis1, axis2, copy=True)
举例:
df # col1 col3 idx1 a 1 2 c 5 2 d 3 5 f 2 6 p 6 3 df.swapaxes(0,1) #idx1 a c d f p col1 1 5 3 2 6 col3 2 2 5 6 3

7.交换多级索引的两个level:swaplevel
1 DataFrame/Series.swaplevel(i=-2, j=-1, axis=0, copy=True)
i/j:为两个level的整数position,也可以是name字符串。
import numpy as np
import pandas as pd
idx = pd.MultiIndex(levels=[['a','b'],['a','d','e']],
labels=[[0,0,0,1,1,1],[0,1,2,0,1,2]],
names=['lv1','lv2'])
s = pd.Series([1,5,3,2,6,4],index=idx,name='s1')
s
# lv1 lv2
a a 1
d 5
e 3
b a 2
d 6
e 4
Name: s1, dtype: int64
s.swaplevel(i='lv1',j='lv2')
# lv2 lv1
a a 1
d a 5
e a 3
a b 2
d b 6
e b 4
Name: s1, dtype: int64
s.swaplevel(i=0,j=1)
# lv2 lv1
a a 1
d a 5
e a 3
a b 2
d b 6
e b 4
Name: s1, dtype: int64

8.修改轴label:Index.map/rename
-
可以采用
Index.map(mapper)方法。其中mapper是个可调用对象,它对每个label进行调用然后返回新的label。该函数返回一个新的Index对象。然后将其赋值给pandas对象的.index/.columns属性。 -
调用
.rename方法:Series.rename(index=None, **kwargs) DataFrame.rename(index=None, columns=None, **kwargs)
-
index/columns:一个标量、dict-like、或者一个函数。- 标量:修改了
Series.name属性。但是对于DataFrame会抛出异常 dict-like或者函数:应用于对应轴的label上
- 标量:修改了
-
copy:如果为True,则拷贝底层数据(此时inplace=False) -
inplace:一个布尔值。如果为True,则原地修改,此时忽略copy参数。否则新创建对象。
-
举例:
import numpy as np
import pandas as pd
idx = pd.Index(['a','c','d','f'],name='idx1')
s = pd.Series([1,3,np.nan,7],index=idx,name='s1')
df = pd.DataFrame({"col1":[np.nan,'china1','china2','china3'],
"col2":[np.nan,3,4,5],
"col3":[np.nan,4,5,6]},
index=idx)
print(s,df,sep='
------------
')
#idx1
a 1.0
c 3.0
d NaN
f 7.0
Name: s1, dtype: float64
------------
col1 col2 col3
idx1
a NaN NaN NaN
c china1 3.0 4.0
d china2 4.0 5.0
f china3 5.0 6.0
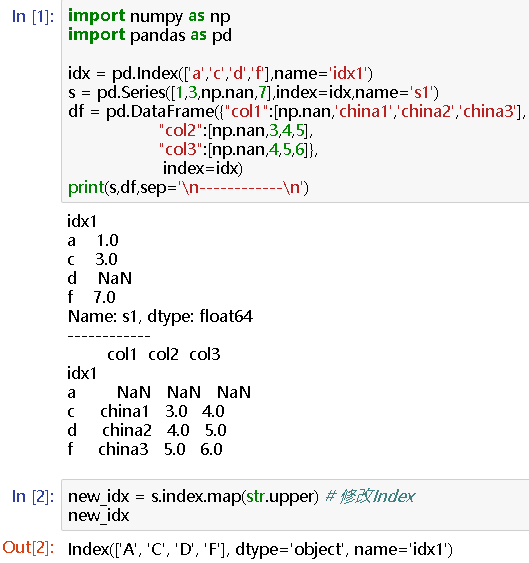
new_idx = s.index.map(str.upper) # 修改Index
#new_idx
Index(['A', 'C', 'D', 'F'], dtype='object', name='idx1')
s.index = new_idx # 赋值给index属性
#s
idx1
A 1.0
C 3.0
D NaN
F 7.0
Name: s1, dtype: float64
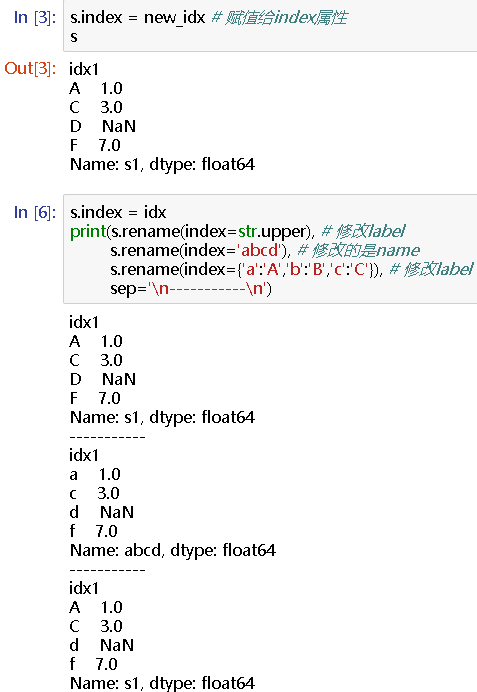
s.index = idx
print(s.rename(index=str.upper), # 修改label
s.rename(index='abcd'), # 修改的是name
s.rename(index={'a':'A','b':'B','c':'C'}), # 修改label
sep='
-----------
')
#idx1
A 1.0
C 3.0
D NaN
F 7.0
Name: s1, dtype: float64
-----------
idx1
a 1.0
c 3.0
d NaN
f 7.0
Name: abcd, dtype: float64
-----------
idx1
A 1.0
C 3.0
d NaN
f 7.0
Name: s1, dtype: float64
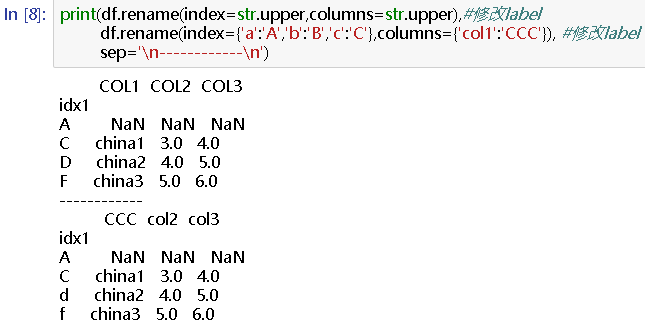
print(df.rename(index=str.upper,columns=str.upper),#修改label
df.rename(index={'a':'A','b':'B','c':'C'},columns={'col1':'CCC'}), #修改label
sep='
------------
')
COL1 COL2 COL3
idx1
A NaN NaN NaN
C china1 3.0 4.0
D china2 4.0 5.0
F china3 5.0 6.0
------------
CCC col2 col3
idx1
A NaN NaN NaN
C china1 3.0 4.0
d china2 4.0 5.0
f china3 5.0 6.0
二、合并数据
1.DataFrame.merge
对于DataFrame,merge()方法可以根据一个或者多个键将不同DataFrame的行连接接起来。它实现的就是数据库的连接操作。
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'),
copy=True, indicator=False)
参数:
-
right:另一个DataFrame对象 -
how:指定连接类型。可以为:'left':左连接。只使用左边DataFrame的连接键'right':右连接。只使用右边DataFrame的连接键'outer':外连接。使用两个DataFrame的连接键的并集'inner':内连接。使用两个DataFrame的连接键的交集
-
on:一个label或者label list。它指定用作连接键的列的label。并且必须在两个DataFrame中这些label都存在。如果它为None,则默认使用两个DataFrame的列label的交集。你可以通过left_on/right_on分别指定两侧DataFrame对齐的连接键。 -
left_on:一个label或者label list。指定左边DataFrame用作连接键的列,参考on -
right_on:一个label或者label list。指定右边DataFrame用作连接键的列,参考on -
left_index:一个布尔值。如果为True,则使用左边的DataFrame的行的index value来作为连接键来合并 -
right_index:一个布尔值。如果为True,则使用右边的DataFrame的行的index value来作为连接键来合并 -
sort:一个布尔值。如果为True,则在结果中,对合并采用的连接键进行排序 -
suffixes:一个二元序列。对于结果中同名的列,它会添加前缀来指示它们来自哪个DataFrame -
copy:一个布尔值。如果为True,则拷贝基础数据。否则不拷贝数据 -
indicator:一个字符串或者布尔值。- 如果为
True,则结果中多了一列称作_merge,该列给出了每一行来自于那个DataFrame - 如果为字符串,则结果中多了一列(该列名字由
indicator字符串给出),该列给出了每一行来自于那个DataFrame
- 如果为
说明:
- 如果合并的序列来自于行的
index value,则使用left_index或者right_index参数。如果是使用了left_index=True,则必须使用right_index=True,或者指定right_on。此时right_on为第二个DataFrame的行label。此时所有对键的操作都针对index label,而不再是column label。 - 如果不显示指定连接的键,则默认使用两个
DataFrame的column label的交集中的第一个label。 - 如果根据列来连接,则结果的
index label是RangeIndex(连续整数)。如果根据行label value连接,则结果的index label/column label来自两个DataFrame - 对于层次化索引的数据,你必须以列表的形式指明用作合并键的多个列。
举例:
合并数据
import pandas as pd
import numpy as np
idx = pd.Index(['a','c','d','f'],name='idx1')
df = pd.DataFrame({'col1':[1,2,3,4],
'col2':[2,3,4,5],
'col3':[3,4,5,6]},index=idx)
df2 = pd.DataFrame({'col1':[4,3,2,1],
'col3':[4,5,6,3],
'col4':[1,3,3,2]},index=['a','f','g','i'])
print(df,df2,sep='
--------
')
col1 col2 col3
idx1
a 1 2 3
c 2 3 4
d 3 4 5
f 4 5 6
--------
col1 col3 col4
a 4 4 1
f 3 5 3
g 2 6 3
i 1 3 2
print(df.merge(df2,how='left',on='col1'),
df.merge(df2,how='right',on='col1'),
df.merge(df2,how='outer',on='col1'),
df.merge(df2,how='inner',on='col1'),
sep='
-------
')
# col3_x 和col3_y是来自不同DataFrame
col1 col2 col3_x col3_y col4
0 1 2 3 3 2
1 2 3 4 6 3
2 3 4 5 5 3
3 4 5 6 4 1
-------
col1 col2 col3_x col3_y col4
0 1 2 3 3 2
1 2 3 4 6 3
2 3 4 5 5 3
3 4 5 6 4 1
-------
col1 col2 col3_x col3_y col4
0 1 2 3 3 2
1 2 3 4 6 3
2 3 4 5 5 3
3 4 5 6 4 1
-------
col1 col2 col3_x col3_y col4
0 1 2 3 3 2
1 2 3 4 6 3
2 3 4 5 5 3
3 4 5 6 4 1
df.merge(df2,how='inner',left_on='col1',right_on='col3')
# col1_x和col3_y对齐
col1_x col2 col3_x col1_y col3_y col4
0 3 4 5 1 3 2
1 4 5 6 4 4 1
df.merge(df2,how='inner',left_index=True,right_index=True)
# 以行label为基准
col1_x col2 col3_x col1_y col3_y col4
a 1 2 3 4 4 1
f 4 5 6 3 5 3
df.merge(df2,how='left',left_index=True,right_index=True,indicator=True)
# 指定indicator
col1_x col2 col3_x col1_y col3_y col4 _merge
idx1
a 1 2 3 4.0 4.0 1.0 both
c 2 3 4 NaN NaN NaN left_only
d 3 4 5 NaN NaN NaN left_only
f 4 5 6 3.0 5.0 3.0 both



2.Pandas.merge
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)
作用与left.merge(right)相同
3.DataFrame.join
如果所有的连接键来自于某列值,则可以使用DataFrame.join()函数。它是.merge()的简化版。
DataFrame.join(other, on=None, how='left', lsuffix='', rsuffix='', sort=False)
参数:
other:一个DataFrame,或者一个Series(要求它的name非空),或者一个DataFrame序列。Series的name作用等同DataFrame的column labelon:指定以调用者的那个column对应的列为键。how:参考merge的howlsuffic/rsuffix:参考merge的suffixes。如果结果中有重名的列,则必须指定它们之一。sort:一个布尔值。如果为True,则在结果中,对合并采用的连接键进行排序
如果是Series,则连接键为Series的index value。此外,DataFrame默认使用 index value(这与merge()不同)。
举例:
4.Pandas.concat
功能:它将多个DataFrame/Series对象拼接起来。
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
参数:
-
objs:一个序列,序列元素为Series/DataFrame/Panel等。你也可以传入一个字典,此时字典的键将作为keys参数。 -
axis:指定拼接沿着哪个轴。可以为0/'index'/,表示沿着 0 轴拼接。可以为1/'columns',表示沿着 1轴拼接。 -
join:可以为'inner'/'outer',指定如何处理其他轴上的索引。即:其他轴上的 col 如何拼接
-
join_axes:一个Index对象的列表。你可以指定拼接结果中,其他轴上的索引而不是交集或者并集(join参数使用时,其他轴的索引是计算得出的)。 -
verify_integrity:一个布尔值。如果为True,则检查新连接的轴上是否有重复索引,如果有则抛出异常。 -
keys:一个序列。它用于区分拼接结果中,这些行/列来分别来自哪里。在必要的时候将建立多级索引,keys作为最外层的索引。如果objs是个字典,则使用字典的键作为keys。它用于建立拼接结果的 index
-
levels:一个序列。与keys配合使用,指定多级索引各级别上的索引。如果为空,则从keys参数中推断。(推荐为空) -
names:一个序列。与keys配合使用,用于建立多级索引的names。 -
ignore_index:一个布尔值。如果为True,则不使用拼接轴上的index value,代替以RangeIndex,取值为0,1,... -
copy:一个布尔值。如果为True,则拷贝数据。
5.Series/DataFrame.combine_first
Series/DataFrame.combine_first()也是一种合并方式。它用参数对象中的数据给调用者打补丁。
Series.combine_first(other) DataFrame.combine_first(other)
参数:
other:Series中必须为另一个Series,DataFrame中必须为另一个DataFrame
结果的index/columns是两个的并集。结果中每个元素值这样产生:
- 如果调用者不是
NaN,则选择调用者的值 - 如果调用者是
NaN,则选择参数的值(此时无论参数的值是否NaN)
6.Series/DataFrame.combine
Series/DataFrame.combine()也是一种合并。
Series.combine(other, func, fill_value=nan) DataFrame.combine(other, func, fill_value=None, overwrite=True)
参数:
-
other:Series中必须为另一个Series,DataFrame中必须为另一个DataFrame -
func:一个函数,该函数拥有两个位置参数。第一个参数来自于调用者,第二个参数来自于other。- 对于
Series,两个参数都是标量值,对应它们对齐后的元素值。返回值就是结果对应位置处的值。 - 对于
DataFrame,这两个参数都是Series,即对应的列。
- 对于
-
fill_value:一个标量 。在合并之前先用它来填充NaN。 -
overwrite:如果为True,则原地修改调用者。如果为False,则返回一个新建的对象。
对于Series,结果的index是两个的并集。结果中每个元素值这样产生:
- 将两个
Series在同一个index的两个标量值分别传给func func的返回值就是结果Series在该index处的值
对于DataFrame,结果的index/columns是两个的并集。结果中每列这样产生:
- 将两个
DataFrame在同一个column label的两列值分别传给func func的返回值就是结果DataFrame在该column label列的值
三、索引旋转
1.DataFrame.stack/unstack
DataFrame.stack()方法将数据的列索引旋转为行索引。注意:它跟转置不同,转置会同时旋转数据。
DataFrame.stack(level=-1, dropna=True)
参数:
level:一个整数、字符串或者整数字符串的列表。如果列索引为多级索引,它指定了将哪个级别的索引旋转为行索引dropna:一个布尔值。如果为True,则如果结果中某行全为NaN,则抛弃该行。
与DataFrame.stack()对应的就是DataFrame.unstack()方法。它将数据的行索引转换为列索引。注意:它跟转置不同,转置会同时旋转数据。
DataFrame.unstack(level=-1, fill_value=None)
参数:
level:一个整数、字符串或者整数字符串的列表。如果行索引为多级索引,它指定了将哪个级别的索引旋转为列索引fill_value:一个标量。如果结果中有NaN,则使用fill_value替换。
旋转时,比如列索引旋转为行索引,则新的行索引是个多级索引,最内层的一级就是原来的列索引。
2.DataFrame.pivot
DataFrame.pivot()方法重排数据。它是一个快捷方式,它使用set_index将列数据变成行索引,然后使用unstack将行索引转为列索引。
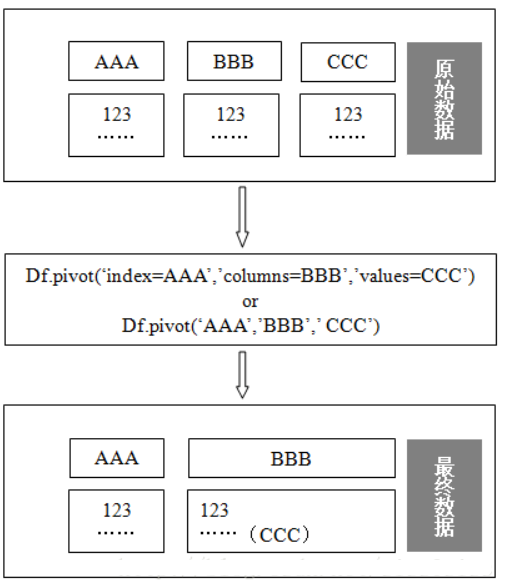
pivot(‘索引列’,‘列名’,‘值’)
DataFrame.pivot(index=None, columns=None, values=None)
参数:
-
index:一个字符串。指定了一个column name,用该列数据来set_index(将该列数据变成行索引,删除了原来的旧的行索引)。如果为None,则不执行set_index -
columns:一个字符串,指定了哪个列数据作为结果的columns labels。实际上对 index,clumns 指定的列数据均 set_index,然后仅对 columns 对应的列数据 unstack
-
values:一个字符串,指定了哪个列数据作为结果的数据。如果未提供,则剩余的所有列都将作为结果的数据。
参考文献: