秉着个人意愿打算把python+rf接口自动进行彻底结束再做些其它方面的输出~但事与愿违,但领导目前注重先把专项测试方面完成,借此,先暂停python+rf(主要是与Jenkins集成+导入DB+微信告警)接口自动化,且目前个人觉得前面讲解的python+rf可以说基本完成了接口自动化测试前期和后续的核心工作了,转而介绍下app专项测试方面的指标检查~
介绍app专项自动化具体实现前,先谈一下我的思路(如下图),若有不妥,欢迎斧正~
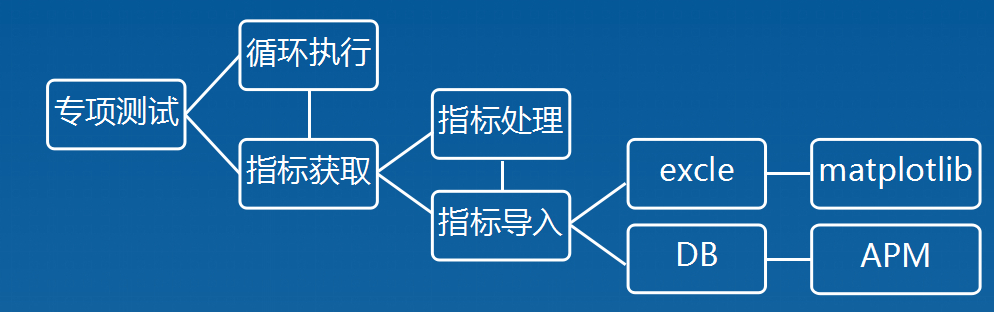
步骤一:循环执行&指标获取,准确点来说是实现循环启动某个页面(adb shell am start)时指标数据获取
具体实现可以看下核心代码
__author__ = 'niuzhigang' # -*- coding: utf-8 -*- #encoding=utf-8 import os import time import datetime import sys import subprocess import xlwt from tempfile import TemporaryFile from xlwt import Workbook dir = r'C:Users iuzhigangDesktoppacketautoScript' print dir now_time = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S') print now_time print (os.getcwd()) os.chdir(dir) print (os.getcwd()) if os.path.exists("TotalTime.log")==True: os.remove("TotalTime.log") if os.path.exists("StartAppDalvikPss.log")==True: os.remove("StartAppDalvikPss.log") if os.path.exists("StartAppNativePss.log")==True: os.remove("StartAppNativePss.log") if os.path.exists("StartAppTOTALPss.log")==True: os.remove("StartAppTOTALPss.log") if os.path.exists("AppCpuThr.log")==True: os.remove("AppCpuThr.log") restartAppCrashlog = os.popen("adb logcat | findstr /I XXX | findstr /I Crash >> XXXCrash.log") restartAppAlllog = os.popen("adb logcat | findstr /I XXX >> XXXAll.log") restartAllCrashlog = os.popen("adb logcat | findstr /I Crash >> AllCrash.log") for i in range(1000): try: restartAppTotalTime = os.popen("adb shell am start -W -S com.XXX.app.ui/.homepage.LaunchActivity | findstr TotalTime >> TotalTime.log") time.sleep(5) #print restartAppTotalTime.read(); for x in range(5): StartAppTOTALPss = os.popen("adb shell dumpsys meminfo -a com.XXX.app.ui | findstr TOTAL >> StartAppTOTALPss.log") #print StartAppTOTALPss.read(); StartAppTOTALPss = os.popen("adb shell dumpsys meminfo -a com.XXX.app.ui | findstr Native | findstr Heap >> StartAppNativePss.log") #print StartAppTOTALPss.read(); StartAppTOTALPss = os.popen("adb shell dumpsys meminfo -a com.XXX.app.ui | findstr Dalvik | findstr Heap >> StartAppDalvikPss.log") #print StartAppTOTALPss.read(); restartAppCpuThr = os.popen("adb shell top -d 1 -n 2 -m 1 -s cpu | findstr com.XXX.app.ui >> AppCpuThr.log") #print restartAppCpuThr.read(); time.sleep(2) #强制杀死进程 StopApp = os.popen("adb shell am force-stop com.XXX.app.ui") time.sleep(1) StartApp = os.popen("adb shell am start -W -n com.XXX.app.ui/.homepage.LaunchActivity") time.sleep(5) OnceStopApp = os.popen("adb shell am force-stop com.XXX.app.ui") time.sleep(1) except Exception,e: print Exception,":",e #print "在没有出现异常的情况下执行的循环次数为:"+i #出现异常点击返回键退出APP程序 BackKeyStart = os.popen("adb shell input keyevent 4") time.sleep(1) BackKeyEnd = os.popen("adb shell input keyevent 4") #出现异常按home键 HomeKeyStart = os.popen("adb shell input keyevent 3") #强制杀死进程 StopApp = os.popen("adb shell am force-stop com.XXX.app.ui") time.sleep(1) continue
首先针对这个专项目前我只收集了cpu、Thr、totaltime、jni层和java层的pss、crash
感兴趣的同学可以收集battery,network等~
再说明下第一次force-stop了为什么我又做了app的重启操作之后再force-stop app呢?
原因1:不属于重启的异常导致手机异常没办法再次拉起app(系统异常),原因2:内部异常也可能导致无法下次start正常以至于程序出现假死的情况。
因此在正常start的情况下收集完本次循环中指标数据又做了下面的start和force-stop操作,当然这次启动我是不记录指标的~
最后说明下为什么做了except操作,可能系统导致程序运行出现异常的情况下也是有可能的,所以做了一系列的手机回到home操作后重启app后,跳出本次异常继续执行下一个循环~
当然,上面的except不一定都是出现这个情况,可以根据实际情况来下,当然写的多了异常考虑我觉得会更好~因为不能在设定的循环过程中没执行完就结束本次循环~
步骤二:指标处理&指标导入,准确点来说就是通过adb命令无法把每项具体的指标以一个list方法展现,因此我们要对搜集到的指标数据按照一定格式进行处理,把每个指标进行剥离后导入excel或者DB
说明下,我写的导入DB的脚本不是从txt里面读取的数据~而是excel
首先大家可以看下从txt读入excel(主要包括数据剥离和数据计算)
__author__ = 'niuzhigang' # -*- coding: utf-8 -*- #encoding=utf-8 import os import time import datetime import xlwt from tempfile import TemporaryFile from xlwt import Workbook dir = r'C:Users iuzhigangDesktoppacketautoScript' print dir now_time = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S') print now_time print (os.getcwd()) os.chdir(dir) print (os.getcwd()) #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableTotalTime = file.add_sheet('TotalTime') #每列给出名称 tableTotalTime.write(0,0,'TotalTime') #写出第二列的平均值名称 tableTotalTime.write(0,1,'AvgTotalTime') TotalTimefpath = r'C:Users iuzhigangDesktoppacketautoScriptTotalTime.log' #打开文件并读取 f = open(TotalTimefpath,'r') line = f.readlines() len = 1 SumTotalTime = 0 for item in line: #转为list list = item.split( ) TotalTime = list[1] print u"TotalTime耗时为:"+TotalTime+"ms" tableTotalTime.write(len,0,float(TotalTime)) len = len + 1 #获取totaltime总值 SumTotalTime += float(TotalTime) print u"TotalTime总耗时为:"+str(SumTotalTime) #求平均值 AvgTotalTimeint = SumTotalTime/(len-1) print AvgTotalTimeint #获取TotalTime的平均值且保留2位小数 AvgTotalTime = float('%.2f' % AvgTotalTimeint) tableTotalTime.write(1,1,AvgTotalTime) print AvgTotalTime f.close() #保存excel并命名 file.save('TotalTime.xlsx') #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableTOTALPss = file.add_sheet('TOTALPss') #每列给出名称 tableTOTALPss.write(0,0,'TOTALPss') #写出第二列的平均值名称 tableTOTALPss.write(0,1,'AvgTOTALPss') TOTALPssfpath = r'C:Users iuzhigangDesktoppacketautoScriptStartAppTOTALPss.log' #打开文件并读取 f = open(TOTALPssfpath,'r') line = f.readlines() len = 1 SumTOTALPss = 0 for item in line: #转为list list = item.split( ) TOTALPss = list[1] print u"TOTALPss占用大小为:"+TOTALPss+"Kb" # print TOTALPss 并存入excel为整数类型 tableTOTALPss.write(len,0,float(TOTALPss)) len = len + 1 #获取TOTALPss总值 SumTOTALPss += float(TOTALPss) print len print u"SumTOTALPss总pss为:"+str(SumTOTALPss) #求平均值 AvgTOTALPssint = SumTOTALPss/(len-1) print AvgTOTALPssint #获取TOTALPss的平均值且保留2位小数 AvgTOTALPss = float('%.2f' % AvgTOTALPssint) tableTOTALPss.write(1,1,AvgTOTALPss) print AvgTOTALPss f.close() #保存excel并命名 file.save('TOTALPss.xlsx') #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableNativePss= file.add_sheet('NativePss') #每列给出名称 tableNativePss.write(0,0,'NativePss') #写出第二列的平均值名称 tableNativePss.write(0,1,'AvgNativePss') NativePssfpath = r'C:Users iuzhigangDesktoppacketautoScriptStartAppNativePss.log' #打开文件并读取 f = open(NativePssfpath,'r') line = f.readlines() len = 1 SumNativePss = 0 for item in line: #转为list list = item.split( ) NativePss = list[2] print u"NativePss占用大小为:"+NativePss+"Kb" # print Cpu 并存入excel为整数类型 tableNativePss.write(len,0,float(NativePss)) len = len + 1 #获取TOTALPss总值 SumNativePss += float(NativePss) print u"SumNativePss总pss为:"+str(SumNativePss) #求平均值 AvgNativePssint = SumNativePss/(len-1) print AvgNativePssint #获取TOTALPss的平均值且保留2位小数 AvgNativePss = float('%.2f' % AvgNativePssint) tableNativePss.write(1,1,AvgNativePss) print AvgNativePss f.close() #保存excel并命名 file.save('NativePss.xlsx') #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableDalvikPss= file.add_sheet('DalvikPss') #每列给出名称 tableDalvikPss.write(0,0,'DalvikPss') #写出第二列的平均值名称 tableDalvikPss.write(0,1,'AvgDalvikPss') DalvikPssfpath = r'C:Users iuzhigangDesktoppacketautoScriptStartAppDalvikPss.log' #打开文件并读取 f = open(DalvikPssfpath,'r') line = f.readlines() len = 1 SumDalvikPss = 0 for item in line: #转为list list = item.split( ) DalvikPss = list[2] print u"DalvikPss占用大小为:"+DalvikPss+"Kb" # print Cpu 并存入excel为整数类型 tableDalvikPss.write(len,0,float(DalvikPss)) len = len + 1 #获取TOTALPss总值 SumDalvikPss += float(DalvikPss) print u"SumDalvikPss总pss为:"+str(SumDalvikPss) #求平均值 AvgDalvikPssint = SumDalvikPss/(len-1) print AvgDalvikPssint #获取TOTALPss的平均值且保留2位小数 AvgDalvikPss = float('%.2f' % AvgDalvikPssint) tableDalvikPss.write(1,1,AvgDalvikPss) print AvgDalvikPss f.close() #保存excel并命名 file.save('DalvikPss.xlsx') #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableCpu = file.add_sheet('AppCpuResult') tableThr = file.add_sheet('AppThrResult') #每列给出名称 tableCpu.write(0,0,'%Cpu') tableThr.write(0,0,'Thr') #写出第二列的平均值名称 tableCpu.write(0,1,'AvgCpu') tableThr.write(0,1,'AvgThr') AppCpuThrfpath = r'C:Users iuzhigangDesktoppacketautoScriptAppCpuThr.log' #打开文件并读取 f = open(AppCpuThrfpath,'r') line = f.readlines() len = 1 SumCpu = 0 SumThr = 0 for item in line: #转为list list = item.split( ) cpu = list[2] Thr = list[4] print u"cpu利用率为:"+cpu+u" 线程数为:"+ Thr # 截取字符串% Cpu = cpu.rstrip('%') # print Cpu 并存入excel为整数类型 tableCpu.write(len,0,float(Cpu)) tableThr.write(len,0,float(Thr)) len = len + 1 #获取cpu总值 SumCpu += float(Cpu) #获取cpu总值 SumThr += float(Thr) print u"SumCpu总cpu为:"+str(SumCpu) print u"SumThr总thr为:"+str(SumThr) #求平均值 AvgCpuint = SumCpu/(len-1) AvgThrint = SumThr/(len-1) print AvgCpuint print AvgThrint #获取Cpu和Thr的平均值且保留2位小数 AvgCpu = float('%.2f' % AvgCpuint) AvgThr = float('%.2f' % AvgThrint) tableCpu.write(1,1,AvgCpu) tableThr.write(1,1,AvgThr) print AvgCpu print AvgThr f.close() #保存excel并命名 file.save('AppCpuThrResult.xlsx') if os.path.exists("TotalTime.log")==True: os.rename("TotalTime.log",now_time+"TotalTime.log") if os.path.exists("StartAppTOTALPss.log")==True: os.rename("StartAppTOTALPss.log",now_time+"StartAppTOTALPss.log") if os.path.exists("StartAppNativePss.log")==True: os.rename("StartAppNativePss.log",now_time+"StartAppNativePss.log") if os.path.exists("StartAppDalvikPss.log")==True: os.rename("StartAppDalvikPss.log",now_time+"StartAppDalvikPss.log") if os.path.exists("AppCpuThr.log")==True: os.rename("AppCpuThr.log",now_time+"AppCpuThr.log")
这个脚本我目前一方面主要是完成数据剥离和计算,另一方面进行了保存,保留了历史记录!!!详细的说明都是excel操作,我就不多说了,不懂的可以私信或者留下评论~
好了,数据导入excel,数据从txt转入excel大家可以从下图(拿CPU举例~)视觉上看下变化,数据怎么剥离、怎么导入、怎么计算的~
TXT格式的数据截图:
EXCEL格式的数据截图:
一般来说接下来就要考虑根据数据出图~那我们就按照一般的思路来出图,根据excel列表数据画图~
借助matplotlib插件库,这个我就粗略的介绍下根据excel列表数据如何自动化画出伸缩图,就给大家晒下py脚本吧~
不多余介绍,都是简单方法的使用完成图的自动伸缩,因为这个方式感觉很笨拙~为什么笨拙?下面就会讲~
__author__ = 'niuzhigang' # -*- coding: utf-8 -*- #encoding=utf-8 import numpy as np import matplotlib.pyplot as plt #X,Y轴数据 y = [20,59,11,12,16,20,15,12,16,21,34,48,11,15,18,16,17,17,11,25,16,9,10,18,16,18,18] #计算list y的长度 ylen = len(y) #print ylen #(开始值、终值 、元素个数作为X坐标目的实现X轴自动伸缩) xArray = np.linspace(0,ylen,ylen,endpoint=False) #list与array互相转换,转为list x = xArray.tolist() print x #创建绘制图像像素大小 #plt.figure(figsize=(15,10)) #在当前绘图对象绘图(XY轴数据,红色实线,线宽度) plt.plot(x,y,"c",linewidth=1) #X轴标题 #plt.xlabel("line") #Y轴标题 plt.ylabel("date") #图标题 plt.title("Cpu%") #显示网格 plt.grid(True) #显示图 plt.show() #保存图 plt.savefig(r"C:Users iuzhigangDesktoppacketautoScriptCpu.png")
说了通过excel画图很笨拙,为什么?原因一:不是UI的方式展现,看起来不方便(想想如果做成报表是不是很好)原因二:死的就是死,没有你想的维度查看、对比等等~
那么接下来,我就讲下导入DB的操作
步骤三:导入DB,具体脚本如下,目前主要从平均值、具体版本执行过程中抓取的详细数据
平均值的目的暂时是做成不同版本之间比较,详细数据目的是检查本版本此指标的走势~
有个问题说下:为什么设置版本(var)为变量,因为目前没有什么好的办法主动获取版本号~
如果其他上神有思路的话可以提供下~
__author__ = 'niuzhigang' # -*- coding: utf-8 -*- #encoding=utf-8 import MySQLdb import xlrd #版本号 ver = "'9.1.0'" #页面activity pageActivity = "'homepage.LaunchActivity'" #连接数据库 conn= MySQLdb.connect( host='10.10.30.200', port = 3306, user='mobtest', passwd='XXX520', db ='test', ) #创建游标目的操作数据库 cur = conn.cursor() #通过游标cur 操作execute方法来创建表 cur.execute("create table if NOT EXISTS AutoTest_AvgTotalTime(id int NOT NULL auto_increment primary key ,totalTimeAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllTotalTime(id int NOT NULL auto_increment primary key ,totalTimeAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AvgTOTALPss(id int NOT NULL auto_increment primary key ,totalPssAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllTOTALPss(id int NOT NULL auto_increment primary key ,totalPssAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AvgNativePss(id int NOT NULL auto_increment primary key ,totalPssAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllNativePss(id int NOT NULL auto_increment primary key ,nativePssAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AvgDalvikPss(id int NOT NULL auto_increment primary key ,totalPssAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllDalvikPss(id int NOT NULL auto_increment primary key ,dalvikPssAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AvgCpu(id int NOT NULL auto_increment primary key ,cpuAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllCpu(id int NOT NULL auto_increment primary key ,cpuAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AvgThr(id int NOT NULL auto_increment primary key ,thrAvgResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") cur.execute("create table if NOT EXISTS AutoTest_AllThr(id int NOT NULL auto_increment primary key ,thrAllResult varchar(255) ,excVersion varchar(255),excPage varchar(255),excTerminal varchar(255) NOT NULL DEFAULT 'App',creatTime timestamp NOT NULL DEFAULT NOW() )") #读取平均值并插入mysql path = r'C:Users iuzhigangDesktoppacketautoScriptTotalTime.xlsx' wb = xlrd.open_workbook(path) tableTotalTime = wb.sheets()[0] TotalTimeValue = tableTotalTime.cell(1, 1).value TotalTime = str(TotalTimeValue) print u"启动耗时为:"+ TotalTime #插入totaltime平均值 cur.execute("insert into AutoTest_AvgTotalTime values(DEFAULT," + TotalTime + "," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #捕获到有效数据的行数 nrows=tableTotalTime.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allTotalTimeValue=tableTotalTime.cell(line_num,0).value allTotalTime = str(allTotalTimeValue) print allTotalTime #插入本迭代执行所有totaltime cur.execute("insert into AutoTest_AllTotalTime values(DEFAULT,"+allTotalTime+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #读取平均值并插入mysql path = r'C:Users iuzhigangDesktoppacketautoScriptTOTALPss.xlsx' wb = xlrd.open_workbook(path) tableTOTALPss = wb.sheets()[0] TOTALPssValue = tableTOTALPss.cell(1, 1).value TOTALPss = str(TOTALPssValue) print u"TOTALPss为:"+ TOTALPss #插入TOTALPss平均值 cur.execute("insert into AutoTest_AvgTOTALPss values(DEFAULT," + TOTALPss + "," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #捕获到有效数据的行数 nrows=tableTOTALPss.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allTOTALPssValue=tableTOTALPss.cell(line_num,0).value allTOTALPss = str(allTOTALPssValue) print allTOTALPss #插入本迭代执行所有TOTALPss cur.execute("insert into AutoTest_AllTOTALPss values(DEFAULT,"+allTOTALPss+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #读取平均值并插入mysql path = r'C:Users iuzhigangDesktoppacketautoScriptNativePss.xlsx' wb = xlrd.open_workbook(path) tableNativePss = wb.sheets()[0] NativePssValue = tableNativePss.cell(1, 1).value NativePss = str(NativePssValue) print u"NativePss为:"+ NativePss #插入NativePss平均值 cur.execute("insert into AutoTest_AvgNativePss values(DEFAULT," + NativePss + "," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #捕获到有效数据的行数 nrows=tableNativePss.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allNativePssValue=tableNativePss.cell(line_num,0).value allNativePss = str(allNativePssValue) print allNativePss #插入本迭代执行所有NativePss cur.execute("insert into AutoTest_AllNativePss values(DEFAULT,"+allNativePss+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #读取平均值并插入mysql path = r'C:Users iuzhigangDesktoppacketautoScriptDalvikPss.xlsx' wb = xlrd.open_workbook(path) tableDalvikPss = wb.sheets()[0] DalvikPssValue = tableDalvikPss.cell(1, 1).value DalvikPss = str(DalvikPssValue) print u"DalvikPss为:"+ DalvikPss #插入DalvikPss平均值 cur.execute("insert into AutoTest_AvgDalvikPss values(DEFAULT," + DalvikPss + "," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #捕获到有效数据的行数 nrows=tableDalvikPss.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allDalvikPssValue=tableDalvikPss.cell(line_num,0).value allDalvikPss = str(allDalvikPssValue) print allDalvikPss #插入本迭代执行所有DalvikPss cur.execute("insert into AutoTest_AllDalvikPss values(DEFAULT,"+allDalvikPss+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #读取平均值并插入mysql path = r'C:Users iuzhigangDesktoppacketautoScriptAppCpuThrResult.xlsx' wb = xlrd.open_workbook(path) tableCpu = wb.sheets()[0] cpuValue = tableCpu.cell(1, 1).value cpu = str(cpuValue) print u"cpu利用率为:"+ cpu tableThr = wb.sheets()[1] thrValue = tableThr.cell(1, 1).value thr = str(thrValue) print u"thr数为:"+ thr #插入Cpu平均值 cur.execute("insert into AutoTest_AvgCpu values(DEFAULT," + cpu + "," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #插入Thr平均值 cur.execute("insert into AutoTest_AvgThr values(DEFAULT,"+thr+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") #捕获到有效数据的行数 nrows=tableCpu.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allCpuValue=tableCpu.cell(line_num,0).value allCpu = str(allCpuValue) print allCpu #插入本迭代执行所有cpu cur.execute("insert into AutoTest_AllCpu values(DEFAULT,"+allCpu+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #捕获到有效数据的行数 nrows=tableThr.nrows line_num = 0 for i in range(nrows): #获取一行的所有值,每一列的值以列表项存在 if i > 0: line_num += 1 allThrValue=tableThr.cell(line_num,0).value allThr = str(allThrValue) print allThr #插入本迭代执行所有thr cur.execute("insert into AutoTest_AllThr values(DEFAULT,"+allThr+"," + ver + "," + pageActivity + ",DEFAULT,DEFAULT)") else: print u"数据为空" #关闭游标 cur.close() #提交 conn.commit() #关闭数据库连接 conn.close(
好了,导入数据sql的数据如下
平均值方面:
详细数据方面:
后面就是APM读取数据且支持维度查询了~APM暂时不是我来搞,所以~~~……后续截图大家可以看下~
补充 截图:平均趋势图如下:
另外指标采集的数据比较多,画出来的详细图,相对来说不易观察,且点与点堆积比较密集,视觉上很不理想,因此对数据做了聚合之后再导入EXCEL以及DB的!
处理方式为每10项数据求和后得出来的平均值导入EXCEL和DB!(不满足10条没在做平均值而是把不满足10条的数据没做处理直接导入)
具体实现如下:
__author__ = 'niuzhigang' # -*- coding: utf-8 -*- #encoding=utf-8 import os import time import datetime import xlwt from tempfile import TemporaryFile from xlwt import Workbook dir = r'C:Users iuzhigangDesktoppacketautoScript' print dir now_time = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S') print now_time print (os.getcwd()) os.chdir(dir) print (os.getcwd()) #创建文件 file = Workbook(encoding='utf-8') #创建sleet tableTotalTime = file.add_sheet('TotalTime') #每列给出名称 tableTotalTime.write(0,0,'TotalTime') #写出第二列的平均值名称 tableTotalTime.write(0,1,'AvgTotalTime') TotalTimefpath = r'C:Users iuzhigangDesktoppacketautoScriptTotalTime.log' #打开文件并读取 f = open(TotalTimefpath,'r') line = f.readlines() a = 1 SumTotalTime = 0 TotalTimeArry = [] TotalTimeArryNew = [] offset = 0 #每几项聚合求平均值 step = 10 for item in line: #转为list list = item.split() TotalTime = list[1] TotalTimeArry.append(int(TotalTime)) # print u"TotalTime耗时为:"+TotalTime+"ms" # print TotalTimeArry length = len(TotalTimeArry) while offset < length: tmp = TotalTimeArry[offset:offset + step] # print tmp if len(tmp) == step: avg = 0 for t in tmp: avg += t avg /= float(step) TotalTimeArryNew.append(avg) else: for t in tmp: TotalTimeArryNew.append(t) offset += step print TotalTimeArryNew #计算聚合后的总值 SumTotalTime = 0 for x in TotalTimeArryNew: SumTotalTime += x tableTotalTime.write(a,0,float(x)) a += 1 # print a print SumTotalTime #求平均值 AvgTotalTimeint = SumTotalTime/(a-1) # print AvgTotalTimeint #获取TotalTime的平均值且保留2位小数 AvgTotalTime = float('%.2f' % AvgTotalTimeint) tableTotalTime.write(1,1,AvgTotalTime) print AvgTotalTime f.close() #保存excel并命名 file.save('TotalTime.xlsx')
执行结果前与后的对比:
一:数量对比
聚合前:
聚合后:
二:数值对比:
聚合前:
聚合后: