变量解释
- explainer.excepted_value
- 预测结果的预期,有时候是一批数据预测结果的均值??
- 分标签,如果是多分类,每一个类别都会有一个预期值,分析shap value时候选择对应标签的excepted_value
- 解释预测结果时候,从这个值出发,每个特征对预测结果有一个影响,最终决定模型的输出
- 这个结果应该也是 log odds, 因为它会出现负数
- log odds: 对数几率 = log p / (1-p)
- 假设预测为正样本的概率为0.01,那么对数几率(以10为底) = log 0.01 / 0.99 = -3.9
- 假设预测为正样本的概率为0.99,那么对数几率(以10为底) = log 99 = 1.9
- shap_values
- shape=(n_labels, n_rows, n_cols)
- 包含的信息是对每个标签,每一行,每个特征都有一个值
- 实际上我们分析时候,会单独看每一个标签的预测分析,二分类的就取label为1的shap value,也就是shap_values[1]
- 单独分析每一行的时候就是 shap_values[1].iloc[index]
KernelExplainer原理
以计算一条记录其中一个特征特征shap_values为例,说明计算过程:
- 把样本特征转换成数字
- 随意生成n个随机数作为mask,将原始的特征与这个mask计算得到新的n个特征
- 新的n个特征带入模型预测获取预测结果,观察预测结果的变化与那个特征的规律得到shap_value
使用shap解释预测结果例子
训练lightgbm模型:
import lightgbm as lgb
import shap
from sklearn.model_selection import train_test_split, StratifiedKFold
import warnings
X, y = shap.datasets.adult()
X_display, y_display = shap.datasets.adult(display=True)
# create a train/test split
random_state = 7
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=random_state)
d_train = lgb.Dataset(X_train, label=y_train)
d_test = lgb.Dataset(X_test, label=y_test)
params = {
"max_bin": 512,
"learning_rate": 0.05,
"boosting_type": "gbdt",
"objective": "binary",
"metric": "binary_logloss",
"num_leaves": 10,
"verbose": -1,
"min_data": 100,
"boost_from_average": True,
"random_state": random_state
}
model = lgb.train(params, d_train, 10000, valid_sets=[d_test], early_stopping_rounds=50, verbose_eval=1000)
model
# <lightgbm.basic.Booster object at 0x000001B96CBFAD48>
构建解释器并获取预期值:
explainer = shap.TreeExplainer(model) # 使用树模型解释器
explainer
# Out[5]: <shap.explainers._tree.Tree at 0x1b96cca5e48>
expected_value = explainer.expected_value
expected_value
# Out[7]: array([-2.43266725])
构建解释器并获取预期值:
features.shape
# Out[17]: (20, 12)
shap_values = explainer.shap_values(features) # 计算shap_values
len(shap_values)
# Out[12]: 2
shap_values[0].shape
# Out[13]: (20, 12)
绘制决策图:
shap.decision_plot(base_value=expected_value, shap_values=shap_values[1][:1], features=features_display[:1])
输出:
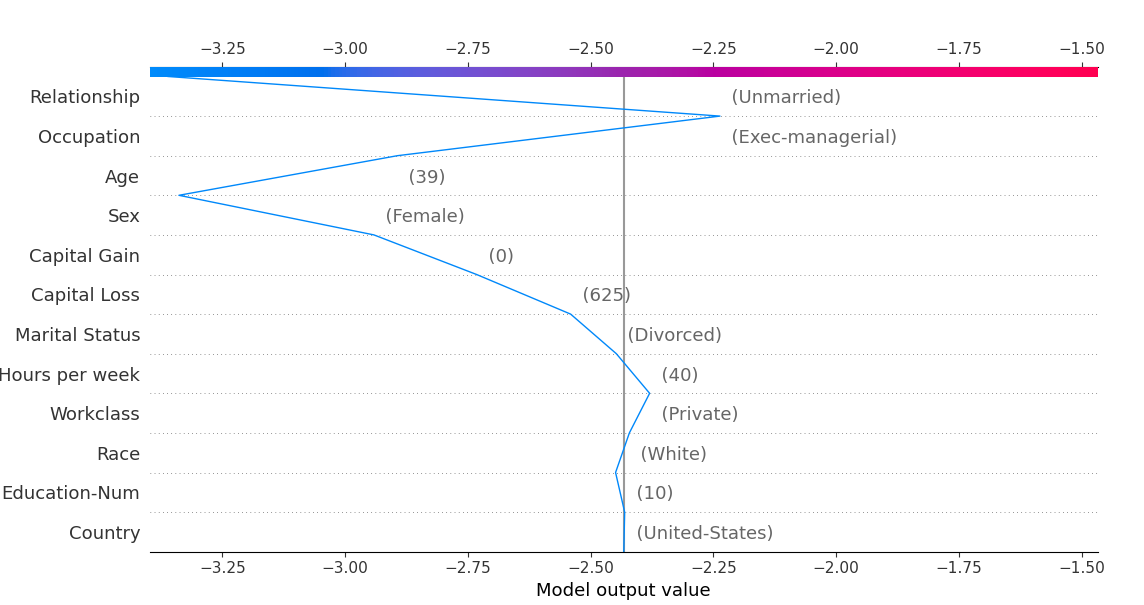
decision_plot 解释:
- x轴是模型的输出,y轴是特征名称,线表示预测的过程
- 模型的输出通常是一个概率,对这个概率取对数几率就是模型的输出
- shap_values: 要解释的数据的shap_values
- features: 估计是用来提取列名的,可以不传或者用feautues_names 代替
- 特征牵拉的幅度越大表示对预测结果的影响越大,影响分成正面影响和负面影响
- 找到那些对正面影响较大的特征以及其取值来解释预测结果
还可以使用力图来解释预测结果:
shap.force_plot(explainer.expected_value[0], shap_values[1][:1], features[:1], matplotlib=True)
