近期客户有需求,导出某些审计数据,供审计人进行核查,只能导出成文本或excel格式的进行查看,这里我们使用sqluldr2工具进行相关数据的导出。
oracle导出数据为文本格式比较麻烦,sqluldr2是灵活的强大的oracle文本导出程序,是之前阿里大拿首席dba楼方鑫开发的小工具,oracle有自己的一个sqlldr工具,是将文本载入到oracle库中用的,而现在这个sqluldr中间加了个u是un的意思,小工具是用oracle的C语言接口写成,短小精干运行速度快,工具很强大,而且批量导出效率非常高,使用灵活,多个平台版本都有对应的工具。
命令参数:
./sqluldr2 SQL*UnLoader: Fast Oracle Text Unloader (GZIP, Parallel), Release 4.0.1 (@) Copyright Lou Fangxin (AnySQL.net) 2004 - 2010, all rights reserved. License: Free for non-commercial useage, else 100 USD per server. Usage: SQLULDR2 keyword=value [,keyword=value,...] Valid Keywords: user = username/password@tnsname sql = SQL file name query = select statement field = separator string between fields record = separator string between records rows = print progress for every given rows (default, 1000000) file = output file name(default: uldrdata.txt) log = log file name, prefix with + to append mode fast = auto tuning the session level parameters(YES) text = output type (MYSQL, CSV, MYSQLINS, ORACLEINS, FORM, SEARCH). charset = character set name of the target database. ncharset= national character set name of the target database. parfile = read command option from parameter file for field and record, you can use '0x' to specify hex character code, =0x0d =0x0a |=0x7c ,=0x2c, =0x09, :=0x3a, #=0x23, "=0x22 '=0x27

- 直接指定sql(适合query比较长的一些语句,结果集直接输出到对应的文件里)
[oracle@m1 ~]$vi query.sql SELECT * FROM ( SELECT A.*, rownum r FROM (select aa.* ,bb.aac003,bb.aac058,bb.aac147 from GIOISX.ac10 aa,GIOISX.ac01 bb where 1=1 and aa.aac001=bb.aac001 and aa.batchid=101 order by aa.aac001,aae003,aae140 ) A WHERE rownum < =30) B WHERE r >0
#./sqluldr2 system/welcoii@cfsgal sql=/home/oracle/query.sql mode=APPEND head=yes file=/home/oracle/jgyl_ad50_%B.csv batch=yes rows=5000
0 rows exported at 2019-06-27 16:21:27, size 0 MB.
30 rows exported at 2019-06-27 16:21:27, size 0 MB.
output file /home/oracle/jgyl_ad50_1.csv closed at 30 rows, size 0 MB.
- 常规导出(head=yes 表示输出表头 log是记录日志)
sqluldr2 hr/hr123@127.0.0.1:1521/XE query="select * from bb_user_t" head=yes file=D:sqluldr2File mp001.csv log=D:sql.log or
log=+D:sqluldr2File mp003.log 如果有日志在日志后追加日志,否则覆盖替换- 使用table参数(“TABLE”选项用于指定将文件导入的目标表的名字,例如我们将EMP 表的数据导入到EMP_HIS 表中,假设这两个表的表结构一致,先用如下命令导出数据:Sqluldr2 … query=”select * from emp” file=emp.txt table=emp_his ……,或生成相应的导入控制文件)
sqluldr2 hr/hr123@127.0.0.1:1521/XE query="select * from bb_user_t" table=temp_004 head=yes file=D:sqluldr2File mp004.csv
- 大批量导出(对于大表可以输出到多个文件中,指定行数分割或者按照文件大小分割,当文件名(“FILE”选项)的后缀以小写的“.gz”结尾时,会将记录直接写入到GZIP格式的压缩文件中,如果要归档大量数据,这个功能可以节约很多的存贮空间,降低运营成本)
sqluldr2 system/welc1@sl query="select * from GIOISX.AD50 where rownum<20000" table=GIOISX.AD50 mode=APPEND head=yes file=/home/oracle/jgyl_ad50_%B.csv batch=yes rows=5000
0 rows exported at 2019-06-27 16:08:42, size 0 MB.
5000 rows exported at 2019-06-27 16:08:43, size 0 MB.
output file /home/oracle/jgyl_ad50_1.csv closed at 5000 rows, size 1 MB.
5000 rows exported at 2019-06-27 16:08:43, size 1 MB.
output file /home/oracle/jgyl_ad50_2.csv closed at 5000 rows, size 2 MB.
5000 rows exported at 2019-06-27 16:08:43, size 2 MB.
output file /home/oracle/jgyl_ad50_3.csv closed at 5000 rows, size 3 MB.
4999 rows exported at 2019-06-27 16:08:43, size 4 MB.
output file /home/oracle/jgyl_ad50_4.csv closed at 4999 rows, size 4 MB.
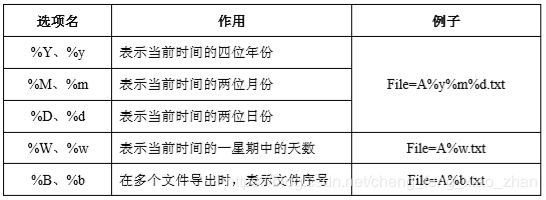
参数说明:
user = username/password@tnsname
sql = SQL file name
query = select statement (选择语句;query参数如果整表导出,可以直接写表名,如果需要查询运算和where条件,query=“sql文本”,也可以把复杂sql写入到文本中由query调用)
field = separator string between fields (
设置导出文件里的分隔符;
默认是逗号分隔符,通过 field参数指定分隔符;
例如现在要改变默认的字段分隔符,用“#”来分隔记录,导出的命令如下所示:
sqluldr2 test/test sql=tmp.sql field=#
在指定分隔符时,可以用字符的ASCII代码(0xXX,大写的XX为16进制的ASCII码值)来指定一个字符,常用的字符的ASCII代码如下:
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,双引号=0x22,单引号=0x27
在选择分隔符时,一定不能选择会在字段值中出现的字符)
record = separator string between records (记录之间的分隔字符串;分隔符 指定记录分隔符,默认为回车换行,Windows下的换行)
rows = print progress for every given rows (default, 1000000)
file = output file name(default: uldrdata.txt) (输出文件名(默认:uldrdata.txt))
log = log file name, prefix with + to append mode (日志文件名,前缀加+模式)
fast = auto tuning the session level parameters(YES)
text = output type (MYSQL, CSV, MYSQLINS, ORACLEINS, FORM, SEARCH).
charset = character set name of the target database. (目标数据库的字符集名称;导出文件里有中文显示乱码,需要设置参数charset=UTF8)
ncharset= national character set name of the target database.
parfile = read command option from parameter file (从参数文件读取命令选项;可以把参数放到parfile文件里,这个参数对于复杂sql很有用)
read = set DB_FILE_MULTIBLOCK_READ_COUNT at session level
sort = set SORT_AREA_SIZE at session level (UNIT:MB)
hash = set HASH_AREA_SIZE at session level (UNIT:MB)
array = array fetch size
head = print row header(Yes|No)
batch = save to new file for every rows batch (Yes/No) (为每行批处理保存新文件)
size = maximum output file piece size (UNIB:MB)
serial = set _serial_direct_read to TRUE at session level
trace = set event 10046 to given level at session level
table = table name in the sqlldr control file (“TABLE”选项用于指定将文件导入的目标表的名字,例如我们将EMP 表的数据导入到EMP_HIS 表中,假设这两个表的表结构一致,先用如下命令导出数据:
Sqluldr2 … query=”select * from emp” file=emp.txt table=emp_his ……)
control = sqlldr control file and path.
mode = sqlldr option, INSERT or APPEND or REPLACE or TRUNCATE
buffer = sqlldr READSIZE and BINDSIZE, default 16 (MB)
long = maximum long field size
width = customized max column width (w1:w2:...)
quote = optional quote string (可选引用字符串;引号符 指定非数字字段前后的引号符)
data = disable real data unload (NO, OFF)
alter = alter session SQLs to be execute before unload
safe = use large buffer to avoid ORA-24345 error (Yes|No) (使用大缓冲器避免ORA-24345错误;ORA-24345: A Truncation or null fetch error occurred,设置参数safe=yes)
crypt = encrypted user information only (Yes|No)
sedf/t = enable character translation function
null = replace null with given value
escape = escape character for special characters
escf/t = escape from/to characters list
format = MYSQL: MySQL Insert SQLs, SQL: Insert SQLs.
exec = the command to execute the SQLs.
prehead = column name prefix for head line.
rowpre = row prefix string for each line.
rowsuf = row sufix string for each line.
colsep = separator string between column name and value.
presql = SQL or scripts to be executed before data unload.
postsql = SQL or scripts to be executed after data unload.
lob = extract lob values to single file (FILE).
lobdir = subdirectory count to store lob files .
split = table name for automatically parallelization.
degree = parallelize data copy degree (2-128).
for field and record, you can use '0x' to specify hex character code,
=0x0d =0x0a |=0x7c ,=0x2c, =0x09, :=0x3a, #=0x23, "=0x22 '=0x27</span>
参考楼方鑫: