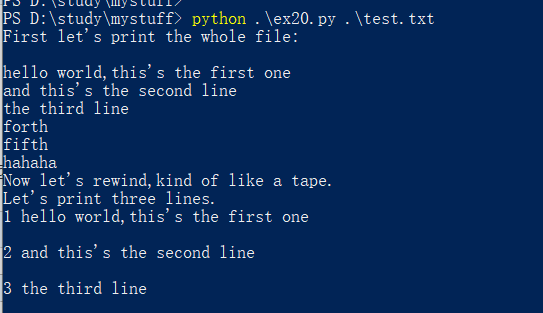
代码如下:
#-*-coding:utf-8-*-
from sys import argv
script, from_file, to_file =argv
print(open(from_file).read())
input('>')
open(to_file,'w').write(open(from_file, encoding='utf-8', errors='ignore').read()) #open文件后要记得close保存,如果open后,调用read了,可以不用额外调用close,read已经保存文件
print(open(to_file).read())
报错如下:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: illegal multibyte sequence
原因及解决办法:
1.首先,打开的文件不是gbk编码,所以解码报错
2.尝试了以下办法解决:
#-*-coding:utf-8-*-
from sys import argv
script, from_file, to_file =argv
print(open(from_file, encoding='utf-8', errors='ignore').read())
input('>')
open(to_file,'w').write(open(from_file, encoding='utf-8', errors='ignore').read()) #open文件后要记得close保存,如果open后,调用read了,可以不用额外调用close,read已经保存文件
print(open(to_file).read())
但会出现如下问题:
一句话的中每个单词的字母间都会有空格:
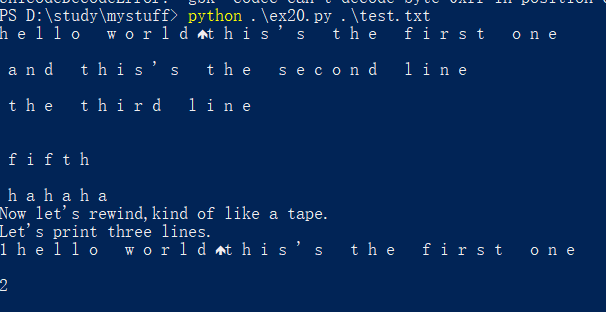
3.最终可以从根本上解决问题的方法:将需要open的文件用Notepad++打开,使用utf-8 编码,则完美解决