| 所属课程 | 软件工程1916|W(福州大学) |
| 作业要求 | 结对第二次—文献摘要热词统计及进阶需求 |
| 结对学号 | 221600327、221600329 |
| 基本需求Github项目地址 | PairProject1-Java |
| 进阶需求Github项目地址 | PairProject2-Java |
| 作业目标 | 运用结对编程完成作业,增强团队协作能力 |
| 参考文献 | 《构建之法》、《数据结构与算法分析 Java语言描述》 |
PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 20 | 30 |
| • Estimate | • 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | 1060 | 1290 |
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 120 |
| • Design Spec | • 生成设计文档 | 10 | 20 |
| • Design Review | • 设计复审 | 30 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| • Design | • 具体设计 | 30 | 40 |
| • Coding | • 具体编码 | 800 | 960 |
| • Code Review | • 代码复审 | 60 | 60 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 80 | 120 |
| • Test Report | • 测试报告 | 40 | 60 |
| • Size Measurement | • 计算工作量 | 10 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1160 | 1440 |
目录
- 1.WordCount基本需求
- 2.WordCount进阶需求
- 3.其他
- 3.1、代码规范
- 3.2、分工情况
- 3.3、Github的代码签入记录
- 3.4、遇到的代码模块异常或结对困难及解决方法
- 3.5、评价队友
- 3.6、感想
- 3.7、学习进度
任务1、WordCount基本需求
1.1、PSP表格
1.2、需求分析
(一)成品:wordCount的命令行程序
(二)功能性需求:统计input.txt中的以下几个指标
- 统计文件的字符数:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
- 统计文件的单词总数,单词:至少以4个英文字母开头,跟上字母数字符号,单词以分隔符分割,不区分大小写。
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词,123file不是一个单词。file,File和FILE是同一个单词
- 统计文件的有效行数:任何包含非空白字符的行,都需要统计。
- 统计文件中各单词的出现次数,最终只输出频率最高的10个。频率相同的单词,优先输出字典序靠前的单词。
- 按照字典序输出到文件result.txt:例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
- 输出的格式为
characters: number
words: number
lines: number
: number
: number
...
(三)非功能性需求
1.接口封装
- 统计字符数 ;
- 统计单词数 ;
- 统计最多的10个单词及其词频 ;
1.3、解题思路
1.3.1统计字符数:
我理解的input.txt的内容应该是,文件中只包含ascii码以及空格,水平制表符,换行符这些字符。所以想直接用String存储文件内容,用String.length()来得到字符数。但是这个会有一个问题,就是在windows平台下,换行符是用" ",String.length()会统计为两个字符,用“ ”代替“ ”,即可解决问题。
1.3.2统计单词数:
文件由两种字符分割符(空格,非字母数字符号)和非分隔符构成,单词统计与非分割符无关,所以直接为了接下来split方便,将所有的分割符都替换为“|”,第二步分割字符串,第三步,使用正则表达式匹配题目所规定的单词,统计单词数。
1.3.3统计有效行数:
一开始我想的统计行数是使用readline();去读出每一行,然后逐行判断这行有没有ascii码值<32的字符存在,因为ascii码值小于32的是在文本中不显示的,所以我开始的想法就是这样的;不过试了一下之后发现对于" "之类的字符和空白行单靠ascii码是区分不出来的,然后在网上找了资料之后,发现String.trim().isEmpty()是可以去除空白行然后统计的,最后使用的是这个方法。
1.3.4统计各单词的出现次数,输出频率Top10的单词:
因为处理场景为单机,所以决定选用散列表,顺序扫描刚刚的到的单词数组,当扫描到某个关键词时,就去散列表里查询。如果存在,就将对应的次数加一;如果不存在,就将他插入到散列表,并记录为1,以此类推,遍历完后,散列表中就存储了不重复的单词以及其出现的次数。
然后就是求Top10,建立一个大小为10的小顶堆,遍历散列表,依次取出每个单词及对应出现的次数,然后与堆顶的单词比较。如果出现次数比堆顶单词的次数多,就删除堆顶单词,将这个次数更多的关键词加入到堆中,以此类推,遍历完散列表,堆中的单词就是出现次数top10的单词。然后排序输出。
1.4、设计过程
1.4.1代码组织&接口设计:
-
bean包:Word类
-
unitl包:BasicWordCount类、IOUnitls类
-
BasicWordCount类:
-
统计字符数函数 :
/** * 计算文件字符数 * @param fileName 文件名 * @return long 字符数 */ public long characterCount(String fileName){} -
统计行数 :
/** * 计算文件行数 * @param fileName 文件名 * @return long 行数 */ public long lineCount(String fileName){} -
统计单词数 :
/** * 计算文件单词数 * @param fileName 文件名 * @return long 单词数 */ public long wordCount(String fileName){} -
统计词频top10的10个单词及其词频 :
/** * 计算出现次数top10的单词及其词频 * @param fileName 文件名 * @return Word[] 单词数组 */ public Word[] topTenWord(String fileName) {}
-
-
IOUnitls类:
-
读文件
/** * 读入指定文件名的文件数据 * @param fileName 文件名 * @return BufferedReader * @throws IOException */ public static BufferedReader readFile(String fileName){} -
写文件
/** * 将制定字符串输出到result.txt * @param fileContent 字符串 */ public static void writeFile(String fileContent, String fileName) {}
-
-
1.4.2关键代码及其流程图(词频Top10单词统计):
解题思路
流程图:
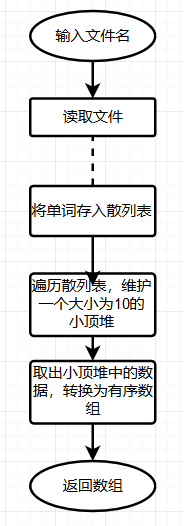
代码:
//进行统计的散列表
public Word[] topTenWord(String fileName) {
...//省略读取文件、将文本处理成单词数组的过程
Map<String, Integer> countMap = new HashMap<>();
for(int i = 0; i < splitStrings.length; i++) {
if(Pattern.matches(regex, splitStrings[i])) {
Integer outValue = countMap.get(splitStrings[i]);
if (null == outValue) {
outValue = 0;
}
outValue++;
countMap.put(splitStrings[i], outValue);
}
}
//求top10
PriorityQueue<Word> topN = new PriorityQueue<>(10, comp);
Iterator<Map.Entry<String, Integer>> iter = countMap.entrySet().iterator();
Map.Entry<String, Integer> entry;
while (iter.hasNext()) {
entry = iter.next();
if (topN.size() < 10) {
topN.offer(new Word(entry.getKey(), entry.getValue()));
} else {
// 如果当前数据比小顶堆的队头大,则加入,否则丢弃
if (topN.peek().getCountNum() < entry.getValue()) {
topN.poll();
topN.offer(new Word(entry.getKey(), entry.getValue()));
}
}
}
//结果集
Word[] result = null;
int wordCount = countMap.size();
if(wordCount < 10) {
result = new Word[(int) wordCount];
}else {
result = new Word[10];
}
topN.toArray(result);
//对top10单词排序
Arrays.sort(result, comp);
return result;
}
复杂度分析:遍历散列表需要 O(n) 的时间复杂度,一次堆化操作需要 O(logK) 的时间复杂度,所以最坏情况下,n个元素都入堆一次,所以最坏情况下,求TopK的时间复杂度是O(nlogk)。
1.5、性能分析
从CPU Call Tree图可以看出,耗时主要是在对字符串的分割和单词的正则匹配。
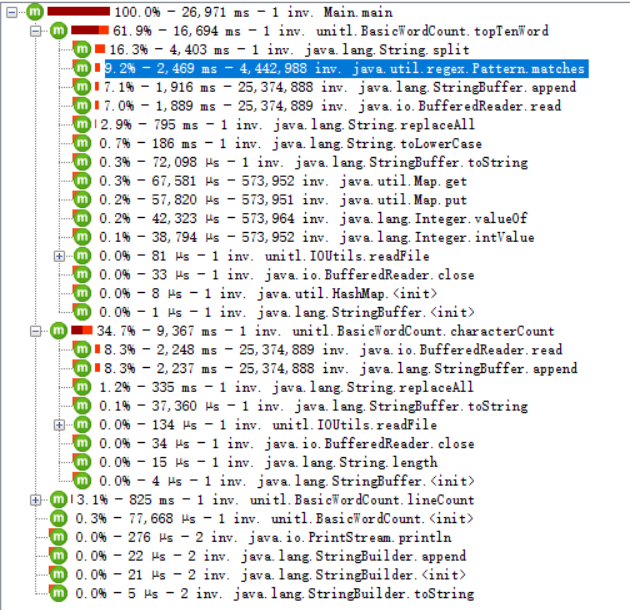
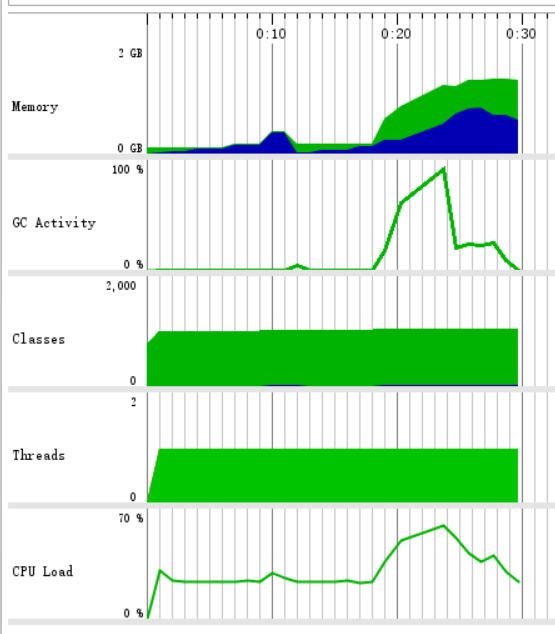
任务2、WordCount进阶需求
2.1、PSP表格
2.2、需求分析
2.2.1 成品:
①程序一:爬取CVPR2018论文到本地result.txt的命令行程序
②程序二:支持命令行参数的wordCount命令行程序
2.2.2功能性需求
(1)使用工具爬取论文信息**输出到result.txt文件
(2)自定义输入输出文件**
WordCount.exe -i [file] -o [file]
(3)加入权重的词频统计**
WordCount.exe -w [0|1]
(4)新增词组词频统计功能**
WordCount.exe -m [number]
(5)自定义词频统计输出**
WordCount.exe -n [number]
(6)多参数的混合使用**
WordCount.exe -i input.txt -m 3 -n 3 -w 1 -o output.txt
2.3、解题思路
2.3.1 爬取CVPR论文数据
要从网页上爬取数据,就得分析网页HTML源代码构成,从CVPR2018首页的HTML代码可以看出,在首页的论文列表中,每一篇的论文标题在HTML代码上体现为如下形式:
<dt class="ptitle"><a href="xxx.html">论文标题</a></dt>
其中<a></a>标签里的href属性为论文详情页的网页地址。
由此我们可以获取每篇论文详情页的url:
第一步就是在网页的DOM树中提取所有的<dt class="ptitle">的节点。
第二步从每个<dt class="ptitle">的节点中提取出<a>标签的href属性。
接着分析论文详情页的HTML代码,
我们可以发现,在详情页源代码中,论文标题的html代码长这个样子:
<div id="papertitle">论文标题</div>
论文摘要的html代码长这个样子:
<div id="abstract">这是论文摘要</div>
由此我们可以获取每篇论文的标题和摘要:
第一步从网页的DOM树中找到<div id="papertitle">的节点,获取他的文本即为paper title。
第二步从网页的DOM树中找到<div id="abstract">的节点,获取他的文本即为paper abstract。
2.3.2 自定义参数
自定义参数的实现是先设计一个CommandLine类,把作业中的参数作为类的私有成员,然后从String []args中读取命令行参数,存进CommandLine类中,再使用getxxxx()公有函数取出相应的参数就可以使用自定义参数了。
2.3.3 加入权重的词频统计:
从爬取的论文数据可知,title独占一行,abstract独占一行,所以可以按行处理数据。如果-w 参数为1,修改基本需求的文件,当一行的开头是title:,那么这一行的单词的权重为10。其他的一律权重为1。
2.3.4 词组词频统计:
因为词组不能跨越Title、Abstract,而且需求给定Title和Abstract都是独占一行的,所以按行读取。
然后构造一个队列,对读取的一行开始扫描,接下来的判断逻辑如下图:

扫描完后,对获得的散列表进行topK操作,即可。
2.3.4 自定义词频统计
这个很简单,基本需求规定的是top10,而这里我们只要从参数获取topK的值,传入参数,遍历单词列表,然后维护一个大小为K的小顶堆即可。
2.4、设计过程
2.4.1 代码组织和接口设计
-
bean包:Word类、CommandLine类
-
unitl包:AdvancedWordCount类、Command类、IOUnitls类
-
AdvancedWordCount类:
-
统计字符数函数 : 同基本需求
-
统计行数 : 同基本需求
-
统计单词数 : 同基本需求
-
统计单词词频topK的K个单词及其词频 :
/** * 计算单词的(加权)词频和topK * @param fileName 文件名 * @param topK 词频前K的单词 * @param isWeight 是否启用加权计算 * @return Word[] 有序单词数组 */ public Word[] topKWordWeighting (String fileName, int topK, boolean isWeight) {} -
统计词组词频topK的K个词组及其词频 :
/** * 计算词组的(加权)词频和topK * @param fileName 文件名 * @param groupNum 几个单词为一个组 * @param topK 词频前K的词组 * @param isWeight 是否启用加权计算 * @return Word[] 有序单词数组 */ public Word[] topKWordsWeighting (String fileName, int groupNum,int topK, boolean isWeight) {} -
-
Command类:
-
/** * 解析命令行参数 * @param args 参数 * @return CommandLine对象 */ public CommandLine ParseCommand(String[] args) {}
-
-
IOUnitls类(同基本需求)
-
2.4.2 关键代码(词组词频统计之词组划分):解题思路
...
//进行统计的散列表
Map<String, Integer> countMap = new HashMap<>();
while((line = bufferedReader.readLine()) != null) {
String regexTile = "Title: .*";
int weight = 1;
if(Pattern.matches(regexTile, line)) {
line = line.replaceAll("Title: ", "");
weight = 10;
}else {
line = line.replaceAll("Abstract: ", "");
weight = 1;
}
line = line.toLowerCase();
//按字符分析
int groupnumber = 0;//词组单词个数
int wordStratPosition = 0;//单词开始下标
int wordEndPosition = 0;//单词开始下标
int flagPosition = 0;//标记词组第一个单词的结束位置
Queue<String> wordReadyQueue = new LinkedList<String>();
for(int i = 0; i < line.length()-3;) {
boolean flag = false;
if(Character.isLetter(line.charAt(i))) {
if(Character.isLetter(line.charAt(i+1))) {
if(Character.isLetter(line.charAt(i+2))) {
if(Character.isLetter(line.charAt(i+3))) {
wordStratPosition = i;
for(int j=i+4; j < line.length(); ++j) {
if(!Character.isLetterOrDigit(line.charAt(j))) {
wordEndPosition = j;
//得到一个单词,加入到队列
wordReadyQueue.add(line.substring(wordStratPosition, wordEndPosition));
groupnumber++;//词组单词数+1
if(groupnumber == 1) {
flagPosition = j;
}
i=j;
flag = true;
break;
}else if((j+1)==line.length()) {
wordEndPosition = j+1;
//得到一个单词,加入到队列
wordReadyQueue.add(line.substring(wordStratPosition));
groupnumber++;//词组单词数+1
if(groupnumber == 1) {
flagPosition = j;
}
i=j;
flag = true;
break;
}
}
}else {
if(!Character.isLetterOrDigit(line.charAt(i))) {
wordReadyQueue.add(line.charAt(i)+"");
}else {
while(wordReadyQueue.poll()!=null) {}//清空队列
while(Character.isLetterOrDigit(line.charAt(i++))) {
if(i >= line.length()){
break;
}
}
groupnumber = 0;
flag = true;
}
}
}else {
if(!Character.isLetterOrDigit(line.charAt(i))) {
wordReadyQueue.add(line.charAt(i)+"");
}else {
while(wordReadyQueue.poll()!=null) {}//清空队列
while(Character.isLetterOrDigit(line.charAt(i++))) {
if(i >= line.length()){
break;
}
}
groupnumber = 0;
flag = true;
}
}
}else {
if(!Character.isLetterOrDigit(line.charAt(i))) {
wordReadyQueue.add(line.charAt(i)+"");
}else {
while(wordReadyQueue.poll()!=null) {}//清空队列
while(Character.isLetterOrDigit(line.charAt(i++))) {
if(i >= line.length()){
break;
}
}
groupnumber = 0;
flag = true;
}
}
}else {
if(!Character.isLetterOrDigit(line.charAt(i))) {
if(groupnumber!=0) {
wordReadyQueue.add(line.charAt(i)+"");
}
}else {
while(wordReadyQueue.poll()!=null) {}//清空队列
while(Character.isLetterOrDigit(line.charAt(i++))) {
if(i >= line.length()){
break;
}
}
groupnumber = 0;
flag = true;
}
}
if(groupnumber == groupNum) {//达到要求个数,加入散列表
String wordGroup = "";
String wordOfQueue = wordReadyQueue.poll();
while(wordOfQueue != null) {
wordGroup = wordGroup + wordOfQueue;
wordOfQueue = wordReadyQueue.poll();
}
groupnumber = 0;
//加权
Integer outValue = countMap.get(wordGroup.toString());
if (null == outValue) {
outValue = 0;
}
if(isWeight) {
outValue += weight;
}else {
outValue++;
}
countMap.put(wordGroup.toString(), outValue);
i = flagPosition;
}
if(!flag) {
++i;
}
}
}
...
2.4.3 关键代码(爬取论文标题和摘要):解题思路
因为之前写安卓应用曾经用户jsoup抓取教务系统上的成绩等数据,这次自然而然使用了jsoup来对论文进行爬取。代码如下:
/**
* 从cvpr网站爬取论文数据,并写入result.txt
* @param URL
*/
public static void getFile(String URL) {
BufferedWriter bufferedWriter = null;
try {
File outputFile = new File("result.txt");
bufferedWriter = new BufferedWriter(new FileWriter(outputFile));
//get方式得到HTML数据
//默认设置下,jsoup超时时间为3秒,鉴于当前网络环境,修改为10秒
//默认设置下,jsoup最大获取的长度只有1024K,设置maxBodySize(0),可不限长度
Document doc = Jsoup.connect(URL).timeout(10000).maxBodySize(0).get();
//从HTML中选择所有class=ptitle的节点
Elements paperList = doc.select("[class=ptitle]");
//从ptitle节点中选择a标签的href属性值
Elements links = paperList.select("a[href]");
int count = 0;
//分别当问每篇论文的详情页
for (Element link : links) {
//论文详情页URL
String url = link.attr("abs:href");
Document paperDoc = Jsoup.connect(url).timeout(10000).maxBodySize(0).get();
//获取论文title
Elements paperTitle = paperDoc.select("[id=papertitle]");
String title = paperTitle.text();
//获取论文Abstract
Elements paperAbstract = paperDoc.select("[id=abstract]");
String abstracts = paperAbstract.text();
//数据写入文件
bufferedWriter.write(count++ + "
");
bufferedWriter.write("Title: " + title + "
");
bufferedWriter.write("Abstract: " + abstracts + "
");
}
} catch (Exception e) {
System.out.println("获取论文数据失败");
e.printStackTrace();
}finally {
try {
if(bufferedWriter != null) {
bufferedWriter.close();
}
}catch (Exception e) {
System.out.println("获取论文数据失败");
e.printStackTrace();
}
}
}
2.5、性能分析及改进
2.5.1、性能分析
考虑到进阶的数据量可能比较大,在压力测试时,我们用了近60M的txt(近6000万的字符)文件进行测试。内存占用在1G左右,由于复用基本需求的接口,在性能测试时,依然是对字符串的分割(split)耗时最多占用内存很大,原因是因为原来的代码是把这6000万字符存放到字符数组里,在进行合法单词的判断。

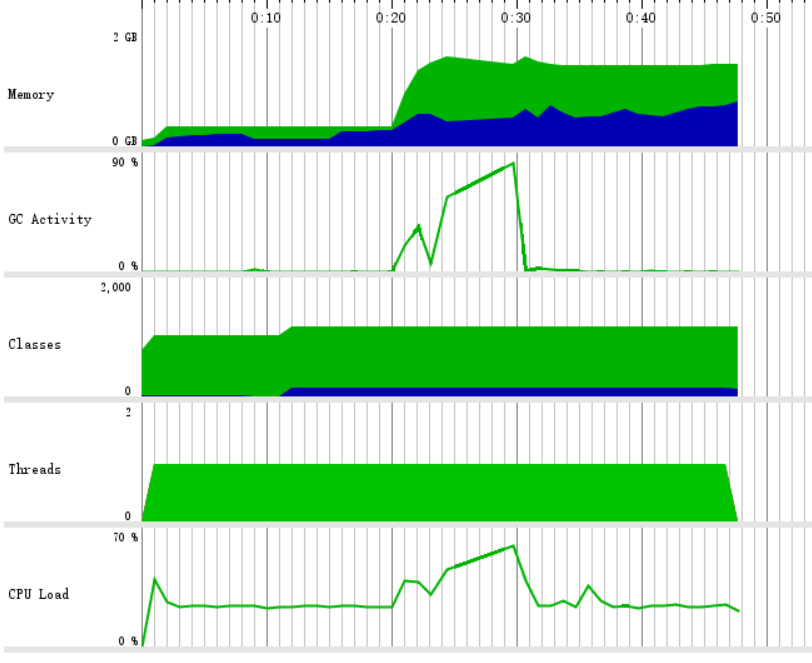
2.5.2、改进方法
在统计单词时,直接遍历一遍文本数据,识别单词的start和end的下标,直接截取单词进行识别。代码如下:
for(int i = 0; i<updateString.length();) {
startPosition = i;
endPosition = i;
while(Character.isLetterOrDigit(updateString.charAt(i++))) {
endPosition++;
}
if(Pattern.matches(regex, updateString.substring(startPosition, endPosition))) {
countOfWord++;
}
}
2.6、单元测试
我们用的是Eclipse中的JUnit4进行的测试,我们总共设计了16个测试单元,其中字符计数,词计数,行计数各三个,进阶单词和词频各两个。测试用例都是根据作业要求设计的各种字符混杂,有空白行,数字字母混杂的形式进行测试,测试结果都显示我们的程序满足了题目的要求。
| 单元测试 | 测试覆盖 | 测试代码块 | 测试个数 |
|---|---|---|---|
| BasicWordCountTest.testCharacterCount() | 普通字符、空格、各种符号 | BasicWordCountTest.CharacterCount() | 3 |
| BasicWordCountTest.testWordCount() | 普通字符、空格、各种符号,字母大小写,数字与字母各种组合 | BasicWordCountTest.WordCount() | 3 |
| BasicWordCountTest.testLineCount() | 空白行、非空白行 | BasicWordCountTest.LineCount() | 3 |
| BasicWordCountTest.testTopTenWord() | 普通字符、空格、各种符号,字母大小写,数字与字母各种组合 | BasicWordCountTest.TopTenWord() | 3 |
| AdvancedWord.TesttopWordWeighting() | 混合单词 | AdvancedWord.topWordWeighting() | 2 |
| AdvancedWord.TesttopWordsWeighting() | 混合词组 | AdvancedWord.topWordsWeighting() | 2 |
部分测试代码
package Untils;
import static org.junit.Assert.*;
import org.junit.Test;
public class BasicWordCountTest {
public static BasicWordCount basic=new BasicWordCount();
static String fileName="testinput2.txt";
String []testTopWord= {"abcd123","here","your","aaaa","abss","bbbb","cccc","ddda","dera","esds"};
int []testTopWordCount= {7,2,2,1,1,1,1,1,1,1};
@Test
//测试字符统计
public void testCharacterCount() {
System.out.println(basic.characterCount(fileName));
assertEquals(189,basic.characterCount(fileName));
}
//测试单词统计
@Test
public void testWordCount() {
basic.wordCount(fileName);
assertEquals(21,basic.wordCount(fileName));
}
@Test
//测试top10单词
public void testTopTenWord() {
basic.topTenWord(fileName);
for(int i=9;i>0;i--) {
System.out.println(testTopWord[9-i]+"=="+i+"=="+basic.topTenWord(fileName)[i].getKey());
assertEquals(testTopWord[9-i],basic.topTenWord(fileName)[i].getKey());
assertEquals(testTopWordCount[9-i],basic.topTenWord(fileName)[i].getCountNum());
}
}
@Test
//测试行数
public void testLineCount() {
basic.lineCount(fileName);
assertEquals(4,basic.lineCount(fileName));
}
}
其中一个测试结果截图
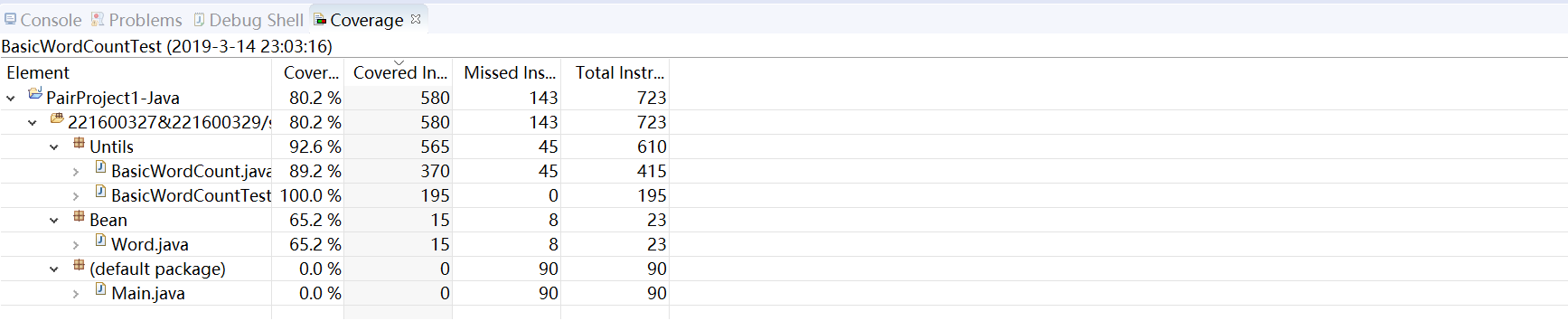
在JUnit4的测试下,我们的总体代码覆盖率在80%左右,其中Main.java类是用来输出结果的类,所以没有加入测试,还有一些原因是很多的异常处理是没有办法触发的,这些代码没有覆盖住。不过我们主要代码的覆盖率都在90%左右,甚至以上的,所以说我们的测试结果还是对程序正确性做了有力验证的。
三、其他
3.1、代码规范:
码出高效 :阿里巴巴Java开发手册终极版v1.3.0
3.2、分工情况
221600327:
行数统计、命令行参数解析、输入输出模块代码编写、单元测试、文档编写
221600329:
字符统计、单词统计、词频统计模块代码编写、爬虫设计和实现、性能测试、文档编写
3.3、Github的代码签入记录
3.4、遇到的代码模块异常或结对困难及解决方法
本来我们认为的词组词频统计会过滤掉单词间的非法字母数字字符,而后来助教重申了需求,要求输出这些字符。因为原先的做法是先把非法字母数字字符都替换掉,然后再进行操作。这需求一改,不就全凉了。后面只能一个字符一个字符的遍历,再截取单词。但是最后发现在数据量大的时候,不采用split去分割字符串,直接遍历反而速度更快,而且更省内存。
3.5、评价队友
3.5.1 221600329 评价 221600327
队友给够按时完成分配的任务,有耐心,可能基础不是特别扎实,但是肯学肯做,这点事值得肯定的。
需要改进的地方:编码能力需要加强。
3.5.2 221600327评价221600329
我的队友在我们结对中大部分时间是驾驶员的角色,他对于需求的分析能很快划分成若干个字模块,在编程方面他数据结构和算法方面的基础知识相当扎实,编码实现能力也很强。我最欣赏的是我的队友认真和仔细的态度,他对作业近乎追求完美,在满足正确性之后还尽量去优化性能;还有他的坚定的信念,就算他在这周身体不舒服,每天狂咳嗽,但是他还是没有因此落下过一点进度,这是我很敬佩的。
需要改进的地方:在任务分配方面可以均衡一些,不然会累着他自己。
3.6、 感想
这次作业碰上了我重感冒的时候,一直咳嗽不止(不敢熬夜了),再加上自己编程能力不突出,所以时间上安排的不好,对于附加部分的需求,没有时间去考虑和设计。这两次都是结对任务,我和队友之间的协作能力有了进步,但是目前还是没有很高的效率,可能还没度过学习阶段,依然处于磨合阶段。
3.7、学习进度
这两周的任务都是结对任务,所以以此为契机我们阅读了《构建之法》第四章两人合作,了解到结对编程是极限编程这一思想的具体体现,结对编程有三种形式:
①键盘鼠标式②Ping-pong式③领航员-驾驶员式。
了解到结对编程,因为在结对编程过程中有随时的复审和交流,可以减少犯错,提高解决问题的效率,形成知识传递。
了解到要做好结对编程,需要遵守相同的代码规范,在不同的阶段,不同的人之间要有不同的方式,而且要养成个人良好的生活习惯。
但是我觉得虽然结对编程有很多好处,但是结对编程的两个队友,编程水平不能相差过大,不然可能会造成交流变成了教学,浪费更多的时间,影响效率。