第三章 内核编程基础
这章我们来深入讨论一下内核Api的结构与定义。我们也深入分析一下在驱动中的代码调用机制。最后,我们把所有的知识汇总在一起完成我们第一个驱动函数。
在这章中:
- 通用内核编程指南
- Debug 与 Release 版本
- 内核API
- 函数与错误码
- 字符串
- 动态内存分配
- 列表
- 驱动对象
- 设备对象
通用内核编程指南
开发内核驱动需要 Windows Driver Kit (WDK),需要正确的头文件和库文件。内核API是由C语言组成,与用户模式的开发非常详细。当然也有几处不同,表3-1总结了内核编程与用户编程非常重要的不同。
未处理异常
在用户模式中未捕获的隐藏会造成进程崩溃。内核模式的代码,另一方便,默认是信任模式,是无法从一个未处理异常中恢复的。这种异常会造成一个臭名昭著的蓝屏死机(BSOD)(新版本的Windows可能对于这种崩溃使用不同的颜色)。这个BSOD可能第一次作为一个惩罚出现,但是这是一个必要的保护机制。允许代码继续执行可能会对Windows造成不可逆转的损坏(比如删除重要的文件或者注册表),这些错误可能造成Windows无法启动。因此,立刻停止可能造成的潜在损坏相比而言是更好的。我们将在第六章更加详细的讨论BSOD。
所有的都会导向一条简单的结论:内核模式下编程一定要十分小心,不要跳过任何细节和错误检查。
中止
当一个进程中止,无论出于什么原因 - 正常,未处理异常或者由内部代码中止 - 将从来不会泄露任何东西:所有的私有内存会被释放,所有的句柄会被关系。当然提前关闭句柄可能造成数据损失。比如一个文件句柄在将数据刷新到磁盘上之前被关系 - 但是不会造成资源泄漏;这是由内核所保证的。
内核驱动,另一方面,是不会提供这样的保证的。如果当驱动卸载时仍然拥有着一块分配的内存或者打开一个内核句柄 - 这些资源将不会被自动的释放,只有在操作系统下次重启时才会被释放。
为什么会这样呢?为什么内核无法跟踪驱动的分配和资源使用,当驱动卸载时自动释放。
从理论上来说,这个是可以实现的(虽然目前内核无法追踪这些资源的使用)。这真正的问题是对于内核来尝试进行这样的清理是非常危险的。内核不知道驱动泄漏出于什么原因。丽日,这驱动可以分配一些缓冲区然后将其传给另一个与它合作的驱动。这第二个也可能使用内存缓冲区然后释放掉它。如果内核尝试释放缓冲区当第一个驱动卸载时,这第二个驱动会造成一个访问权限冲突,最后会造成系统朋克。
再次强调一下,内核驱动有责任清理自身,不会有第二个这样做的。
函数返回值
通常用户模式代码,API的返回值有时会被忽略的,开发者非常乐观地认为有些调用的函数不会失败。对于有些函数,可能对也可能不对。但是糟糕的是,一个未处理的异常可能造成程序崩溃;对于系统,然而,仍然是完整的。
忽视内核API的返回时可能更加危险(看之间的中止这一节),通常来说应该避免,其实看起来“无辜”的函数也可能由于一些错误调用失败,因此黄金法则就是 - 总是检查内核APIs的返回状态。
IRQL
Interrut Reques Level(IRQL)是一个内核非常重要的概念,这将在之后的第六章被进一步讨论。可以这样说,处理的IRQL等级通常为0,更详细一点,用户代码通常在零级别上运行。在大多数情况下仍然为零,但不是全部时候。高于0级别的IRQL等级将会在第六章来讨论。
C++的使用
在用户模式的编程中,C++已经用了很多年了,它和内核API组合调用工作的很好。在内核模式中,微软开始正式在Visual Studio 2012 和 WDK8 中支持C++。C++并不是强制性的,当然,但是它对于内存资源释放有是非重要的优势,其使用一种被称为资源获取的初始化(RAII)的C++习惯用法、我们将使用一些RAII习惯来确保我们不会造成资源泄漏。
C++大部分是内核所完全支持的,但是C++ Runtime和一些C++的特性是不能被使用的:
- new 和 delete 操作符是不支持的,将会造成编译失败。这是因为他们的操作时从用户堆空间中分配内存,这与内核是没有关系的。这内核API有一些与C函数 malloc free相似的,我们将在该节之后讨论它。但是,可以像在用户模式c++中那样重载这些操作符,并调用内核分配和释放函数。我们也将在之后的章节中看到。
- 具有非默认构造函数的全局变量将无法调用 - 没有人可以调用这些构造函数。在下面这些情况应该避免:
- 避免在构造函数中添加然和代码,还是创建一些Init函数,以便在驱动代码中显示地调用这些函数(在DriverEntry中)。
- 置为全局变量分配一块内存,动态地创建这些实例。编译器将确保生成正确的代码来调用构造其,假设new和delete操作符已经被重载而有效,我们在这节之后会看到。
- C++异常关键字(try,catch,throw)将无法被编译。这是因为C++异常处理机制需要我们在运行时,这在内核中无法进行。我们异常处理只能使用SEH - 一种内核处理异常的机制,我们将在第六章来看到SEH更多的处理细节。
- 标准的C++库将无法在内核中使用。虽然绝大多数模板无法编译,因为他们依赖于用户模式的库和语法。也就是说,模板作为C++的一种语言特性无法在内核中很好地运行,比如,可以为用户模式库类型创建可选类型,例如std::vector<>, std::wstring。
在本市中使用C++的例子中,大多体现了下面这些特定:
- 这Nullptr关键字,表现为一个真正的NULL指针。
- 在声明和初始化变量时允许类型推断的auto关键字。这有助于减少混乱,节省一些打字时间,并专注于重要的部分。
- 模板将在有意义时使用。
- 重载new和delete操作符
- 对于RAII类型的构造器和析构器。
严格一点说,驱动可以被纯C没有任何问题地编写。如果你喜欢这种方式,你可以使用C后缀而不是C++后缀编写,这将自动调用C编译器。
测试与调试
在用户模式下编写代码,一般在开发者的机器中编写代码(如果所有的依赖被满足),调试通常有附加的调试器(Visual Studio大多是这种情况)来运行程序。
在内核模式,测试一般在另一个机器中完成,通常是有开发者机器所控制的虚拟机,如果蓝屏死机现象发生,开发者的机器将不会受到影响。调试内核代码一定要用另一台机器,在该机器中驱动代码被执行。因为在内核模式下,触发一个断点是中断的整个机器,不是一个实际的进程。这意味着一般有开发者机器控制调试器,而第二个机器(通常是虚拟机)来执行驱动代码。这两个机器一定要通过某种机制连接,为了让数据可以在主机与目标机之间流通。我们将在第五章看到内核调试的更多细节。
Debug版本 vs Release版本
就像用户项目的构建,构建内核驱动可以使用Debug或Release模式,这不同是与用户模式下非常相似的 - Debug构建将默认不会使用优化,而是更容易调试。Release构建使用了编译器中的优化器来尽可能产生更快的代码,当然,这儿也存在一些不同。
在内核中的实际的术语为 Checked(Debug) 和 Free(Release)。虽然Visual Studio 内核项目继续使用 Debug/Release术语,更老的文档使用Checked/Free术语。从编译器的角度来说,Kernel Debug 定义了DBG符号,并且将其设置为1(与_DEBUG符号在内核代码中定义是相似的),这意味着你是用DBG符号来区分Debug与Release。实际上Kdprint宏确实是这样做:在Debug模式下它编译为DbgPrint函数,然而在Release模式下它什么也不编译,这就导致了KdPrint在Release构建下是无效的。我们会在第10章钢架详细的讨论信息记录的其他方式。
内核API
内核驱动通常使用内核导出的API。这些函数将作为内核API来进行参考。大多数函数由内核模块(NtOskrnl.exe)所运行,但是有一些由其他的模块来运行,比如HAL(hal.dll)。
内核API是C函数的一个集合、大多数API都存在一个前缀来指出函数的作用。表3-2展示了比较常用的前缀以及它们的意义:
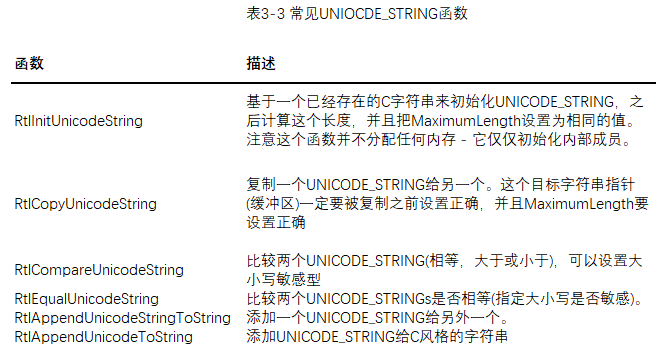
wcs前缀是C Unicode 字符串,而 str前缀是C风格字符串。 前缀 _s在有些函数中表示是一个安全的函数,其中需要提供给函数一个额外的参数,来表示这个字符串的最大长度,为了不能转换比大小更多的数据。
动态内存分配
驱动经常动态地分配内存。在第一章中我们讨论过该,内核栈大小非常小,因此任何大块的内存都应该被动态地分配。
内核提供两种内存池给驱动使用(内核本身也使用它们):
- 分页内存 - 如果需要的话内存池可能被分配出去;
- 非分页内存 - 内存池将永远不会被分配初期,其保留在RAM中。
明显地,非分页内存池将会是更好的选择,因为其不会触发一个也异常。我们在本书中的后面看到需要分配费分页内存。驱动应该尽量少的使用这个内存池,只在使用时需要。在另外的情况下,驱动应该使用分页内存,这个POOL_TYPE枚举展示了池的类型,这个枚举包含了很多池的类型,但我们只应该使用其中的三个:PagedPool,NonPagePool,NonPagedPoolNx(在没有执行拒绝的情况下为非分页内存)。
下面总结了几个常用的内核内存池的函数

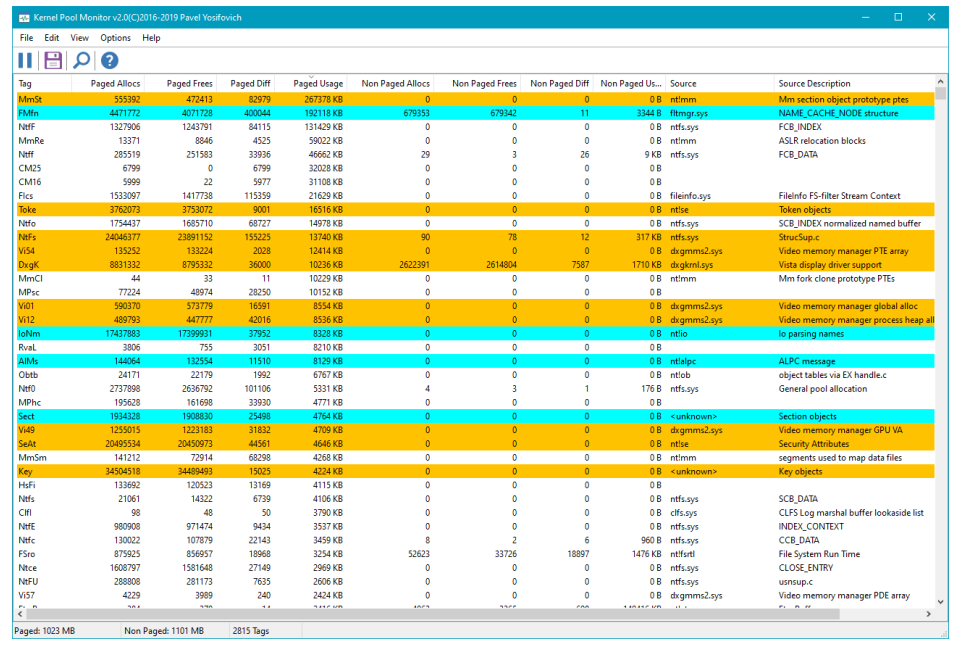
函数中这个tag参数允许使用4个字节标记这块内存,一般来说,这个值由驱动定义的4个ASCII字符组成,或者这个驱动的其他部分。这个标签可以被用来检测是否内存泄漏 - 驱动卸载之后仍然存在标签。这些分配池(和它们的标签)可以使用Poolmon WDK 工具,欧哲我们自己的PoolMonX工具(下载从http://www.github.com/zodiacon/AllTools)。图3-1展示了PoolMonX的屏幕快照(v2)。
下列代码展示了一个内存分配和字符串拷贝来保存DriverEntry传递的注册路径的例子,释放内存在卸载例程中。

列表
在很多情况下,内核使用双向循环链表。例如,在系统中所有的进程由一个EPROCESS结构管理,其连接起来使用一个双向循环链表,这个头部存储在内核变量PsActiveProcessHead中。
所有的这些链表由相似的风格建立,这LIST_ENTRY结构定义如下:
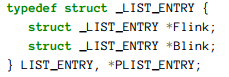
图3-2描述了一个头和三个实例的组合

一个这样的结构被嵌入到真实的结构中。例如,这EPROCESS结构,这LIST_ENTRY类型的ActiveProcessLinks成员,指出了下一个和前一个EPROCESS结构的LIST_ENTRY对象。这个链表的头部被分开存储;在这个进程的例子中,是PsActiveProcessHead。得到这个指针基于的实结构体地址可以使用CONTAINING_RECORD宏。
例如,假设你打算管理像如下定义的MyDataItem类型。
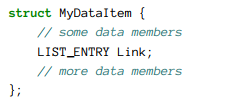
当这些链表工作时,我们有一个这种链表的同步,存储在一个变量中。这意味着我们可以使用这个Flink成员遍历到下一个这链表LIST_ENTRY的。得到一个LIST_ENTRY,我们所希望的是这个MyDataItem,其包含着这个链表成员,CONTAINING_RECORD宏使用如下:
这个宏进行正确的偏移计算,之后抛出正确的数据类型(在这个例子中是MyDatItem)。

表3-5展示了常见的链表函数。所有的操作都使用常数时间。
在表3-4中的最后三个函数表示该操作自动使用一个称为spinlock的同步锁,SpinLock将在第六章讨论。

驱动对象
我们早已看到DriverEntry接受两个参数,第一个是驱动对象,其在WDK头部官方文档中半定义的称为DRIVER_OBJECT。“半定义”意味着这些文档化的成员有的被驱动使用,有的没有。这个结构早已被内核分配和初始化绝大部分。之后这提供一个DriverEntry(在驱动卸载例程之前)。在此时,驱动的作用是进一步初始化该结构来指出该驱动支持的哪些操作。
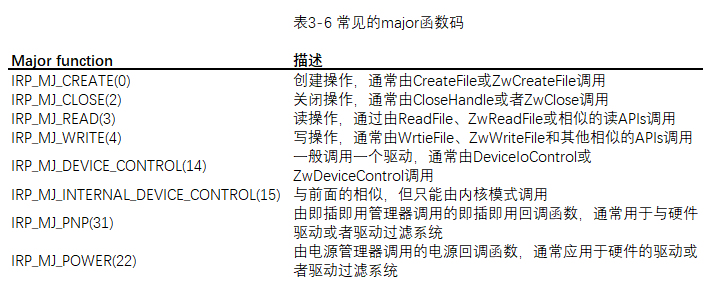
我们在第二章中看到了一个例子 - 卸载例程。其他的重要的设置初始化的操作被称为Dispatch Routine。这个一个指针数组在DRIVER_OBJECT的MajorFunction成员。这组指令了这个驱动支持哪些实际的操作,比如Create、Read、Write等。这些指示用IRP_MJ_前缀定义。表3-6展示了这些常见的函数码和它们的意义。
最初,MajorFunction数组由内核初始化,来指向一个内核例程。IopInvalidDeviceRequest,这返回给调用者一个错误状态,指明了哪个操作是不支持的。这意味着在DirverEntry中需要初始化它支持的实际操作,使用默认值来保留其他所有入口。
例如,在该处我们的驱动例子中不支持派发函数,这意味着驱动没有办法通讯。一个驱动至少支持IRP_MJ_CREATE和IRP_MJ_CLOSE操作来允许打开一个驱动对象的句柄。我们将在下一个章节实践这些想法。
设备对象
虽然一个驱动对象看起来是与客户端交流的好的参与者,但实际情况并不如此。客户端与驱动通信的实际端点是设备对象。设备对象是半文档化的DEVICE_OBJECT结构体实例。没有设备对象,这里没人交流。这意味着驱动至少给出一个驱动对象,给予一个名字,问了能与客户端建立连接。
CreateFile函数接手的第一个参数被称为"文件名",但是实际指向一个设备对象名,这儿真实的文件只是其中一个特殊的例子。这个CreateFile名字有时引起误解 - 这个词“文件”实际意味着文件对象。打个一个文件或设备将创建一个内核结构FILE_OBJECT的实例,其是另一个半文档化的结构。
更精准地说,CreateFile接收一个符号链接,一个内核对象其知道如何指向另外一个内核结构(你可以认为一个符号链接在概念上类似于文件系统的快捷方式)。所以的符号链接可以在用户模式的CreateFile或CreateFile2函数调用来定位到一个命名为 ??.的对象管理目录。这个可以使用Sysinternals工具WinObj看到。图3-3展示了这个目录(名为Global??在WinObj中)。
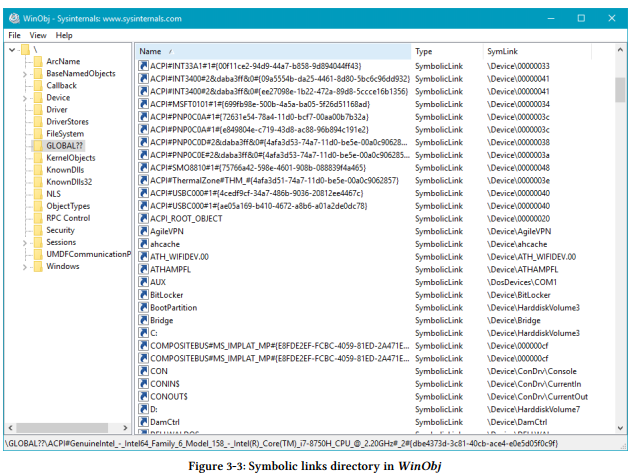
这些名字看起来非常相似,比如 C:,Aux,Con。的确,这个CreateFile调用这个正确的"file names"。其他的入口看起来像长而神秘的字符串,这些实际上是由I/O管理器为硬件生成的,其调用IoRegisterDeviceinterface Api。这些类型的符号链接将不会在这本书中使用。
大多数在??目录中的符号链接指向一个在Device目录下的内核驱动名。在这个目录下的名字不允许被用户模式调用者直接访问。但是他们可以由内核调用者使用IoGetDeviceObjectPointer Api来使用。
一个典型的例子是Process Explorer驱动。当Process Explorer驱动在管理员模式启动时,其加载了一个驱动。这个驱动给Process Explorer超越其用模式APIs所能获得的权限。例如,Process Explorer它的线程对话框中可以完全展示一个线程的调用堆栈,其包括在内核模式中的。这类型的信息是不可能从用户模式中获得的;它的驱动提供了消失的信息。
这个由Process Explorer调用的驱动创建了一个单独的设备对象为了Process Explorer能够打开设备和发出请求。这意味着这个设备对象一定要被命名和必须在??目录下有一个符号链接;在这里,这命名为PROCEXP152,可能指明其为15.2版本(在写这个时)。图3-4展示了在WinObj.的符号链接。

注意这个Process Explorer.s设备的符号链接指向 DevicePROCEXP152,这内部名字只能由内核调用者访问。这个由Process Explorer实际调用的CreateFile基于的一定一个\..前缀的符号名字。这是必要的,这样对象管理解析器将不会假设这个"PROCEXP152"指向一个当前目录下的文件。这个Process Explorer如何打开它的设备对象句柄(注意注意双反斜杠,因为使用了反斜杠转义字符)。

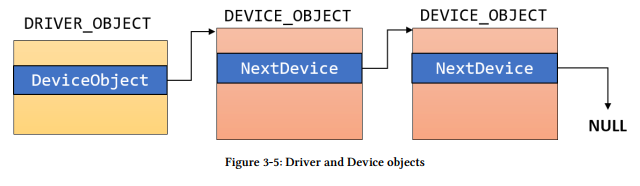
一个驱动使用IoCreateFile函数来创建一个设备对象。这个函数分配并且初始化一个设备对象,返回给调用者其指针。这个设备对象实例将保存在DRIVER_OBJECT结构的DeviceObject成员中。如果超过一个驱动被创建,他们构成了一个单项链表,那儿DEVICE_OBJECT的NextDevice成员指向下一个驱动。注意设备对象其被插入到链表头,所以这个第一个被创建的设备对象保存在最后,它的NextDevice指针指向NULL。这个关系在图3-3中被描述。