最近在弄一个微信的公众帐号,涉及到火车票查询,之前用的网上找到的一个接口,但只能查到火车时刻表,12306又没有提供专门的查票的接口。今天突然想起自己直接去12306上查询,抓取查询返回的数据包,这样就可以得到火车票的信息。这里就随笔记一下获取12306余票的过程。
首先,我用firefox浏览器上12306查询余票。打开firefox的Web控制台,选上网络中的“记录请求和响应主体”
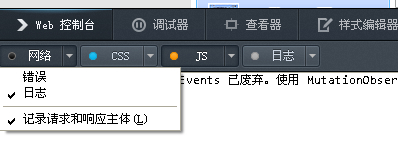
然后输入地址日期信息之后点击网页上的查询按钮,就能在Web控制台下看到网页请求的地址了:

就是图片中的第二条,即当你点击查询按钮时,处理该事件的实际地址。点开它可以看到
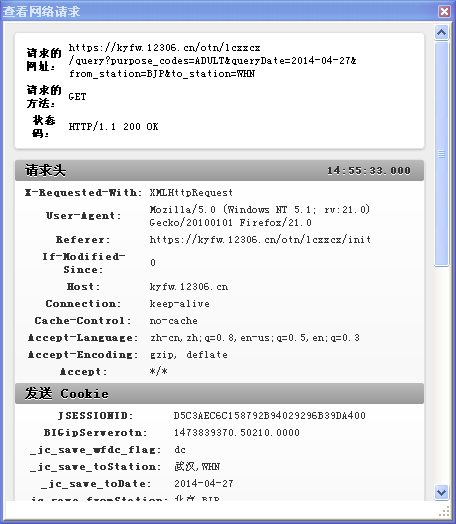
请求网址,请求头,响应头和响应主体这些东西,响应主体里就是我们需要的火车票信息。
有了这个请求网址了就可以到实际代码中进行操作了。可以发现网址的格式是
前面是处理请求的地址,后面接的参数purpose_codes是指成人票(AADULT),学生票(自己去试试吧),queryDate就是日期,from_station和to_station顾名思义就是出发站和到达站了。这里北京和武汉分别表示为BJP和WHN。
到java代码里就可以直接写https请求来获取火车票信息数据包了
public static List<NewTrain> getmsg(String startCity,String endCity,int isAdult) throws Exception{ List<NewTrain> trains = new ArrayList<NewTrain>(); String sstartCity = CityCode.format(startCity); String sendCity = CityCode.format(endCity); TrustManager[] tm = {new MyX509TrustManager()}; SSLContext sslContext = SSLContext.getInstance("SSL", "SunJSSE"); sslContext.init(null, tm, new java.security.SecureRandom()); // 从上述SSLContext对象中得到SSLSocketFactory对象 SSLSocketFactory ssf = sslContext.getSocketFactory(); String type = "ADULT"; if(isAdult == 1){ type = "0X00"; } String urlStr = "https://kyfw.12306.cn/otn/lcxxcx/query?purpose_codes="+type+"&queryDate=2014-04-27&from_station="+sstartCity+"&to_station="+sendCity; URL url = new URL(urlStr); HttpsURLConnection con = (HttpsURLConnection) url.openConnection(); con.setSSLSocketFactory(ssf); InputStreamReader in = new InputStreamReader(con.getInputStream(),"utf-8"); BufferedReader bfreader = new BufferedReader(in); StringBuffer sb = new StringBuffer(); String line = ""; while ((line = bfreader.readLine()) != null) { sb.append(line); } System.out.println(sb.toString()); }
这段代码的cityCode.format()是自己写的将中文的站名转换为字母组合,下面那几行是关于https请求的。网址就是刚才获取到的网址。这段代码执行后得到的输出内容如下:

很容易看出来这些数据是一条条的json数据(我进行了简单的处理,让他一条条打印出来)。
既然是json数据就好办了。取出一条数据来进行分析就可以分析出来key值代表的意思。我只分析了几个我需要的key值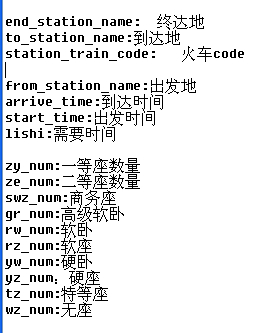
然后就直接写一个Train类来储存火车票的信息,便于之后显示用了。
public class NewTrain { private String to_station_name; //到达地 private String station_train_code; //火车编号 private String from_station_name; //出发地 private String start_time; //出发时间 private String arrive_time; // 到达时间 private String lishi; // 需要时间 private String zy_num; // 一等座数量 private String ze_num; // 二等座数量 private String swz_num; // 商务座数量 private String gr_num; // 高级软卧数量 private String rw_num; // 软卧数量 private String rz_num; // 软座数量 private String yw_num; // 硬卧数量 private String yz_num; // 硬座数量 private String tz_num; // 特等座数量 private String wz_num; // 无座数量 }
接下来的工作就很简单了,将json数据放入Train类对象中。
好了,基本工作完成了,接下来的工作就是将功能整合到项目里去了。
这其中用到的中文站名跟字母组合的一个txt文件(读txt获取中文站名对应的字母的组合,有一些可能不全,大家有好的资源可以提供给我一下,谢了~)
如果大家需要可以邮件我376751704@qq.com (第一次写这个不知道怎么上传附件~)