链表
像数组一样,链表也用来表示一系列的元素。
与数组不同的是,组成链表的格子不是连续的。它们可以分布在内存的各个地方。这种不相邻的格子,就叫作结点。
每个结点除了保存数据,它还保存着链表里的下一结点的内存地址。
这份用来指示下一结点的内存地址的额外数据,被称为链。
链表如下图所示。

链表相对于数组的一个好处就是,它可以将数据分散到内存各处,无须事先寻找连续的空格子。
读取
读取链表中某个索引值的最坏情况,应该是读取最后一个索引。这种情况下,因为计算机得从第一个结点开始,沿着链一直读到最后一个结点,于是需要N步。由于大O记法默认采用最坏情况,所以我们说读取链表的时间复杂度为O(N)。这跟读取数组的O(1)相比,的确是一大劣势。
查找
链表的查找效率跟数组一样。记住,所谓查找就是从列表中找出某个特定值所在的索引。对于数组和链表来说,它们都是从第一格开始逐个格子地找,直至找到。如果是最坏情况,即所找的值在列表末尾,或完全不在列表里,那就要花O(N)步。
插入
在某些情况下,链表的插入跟数组相比,有着明显的优势。回想插入数组的最坏情况:当插入位置为索引0时,因为需要先将插入位置右侧的数据都右移一格,所以会导致O(N)的时间复杂度。然而,若是往链表的表头进行插入,则只需一步,即O(1)。

删除

经过一番分析,链表与数组的性能对比如下所示。
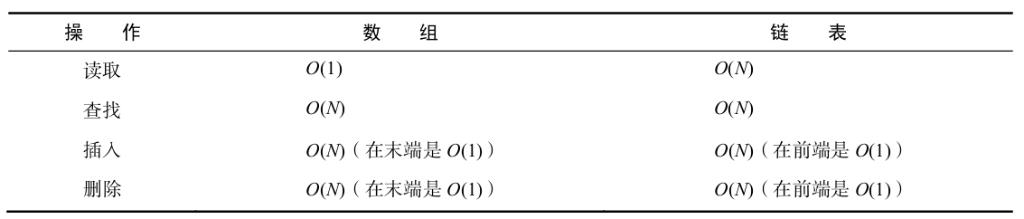
尽管两者的查找、插入、删除的效率看起来差不多,但在读取方面,数组比链表要快得多。
高效地遍历单个列表并删除其中多个元素,是链表的亮点之一。
双向链表
双向链表跟链表差不多,只是它每个结点都含有两个链,一个指向下一结点,另一个指向前一结点。此外,它还能直接访问第一个和最后一个结点。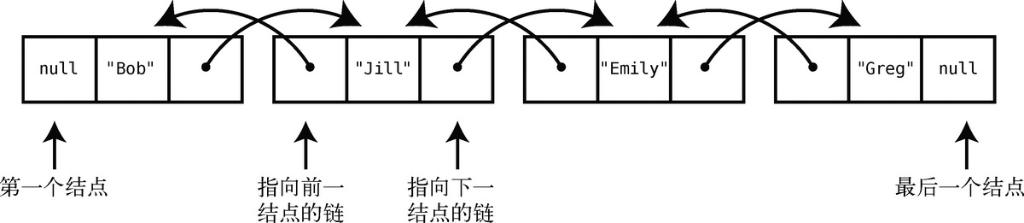
因为双向链表能直接访问前端和末端的结点,所以在两端插入的效率都为O(1),在两端删除的效率也为O(1)。由于在末尾插入和在开头删除都能在O(1)的时间内完成,因此拿双向链表作为队列的底层数据结构就最好不过了。
参考:数据结构与算法图解.11.1