SQL笔记
数据库相关概念
1.DB:数据库,保存一组有组织的数据的容器
2.DBMS:数据库管理系统,又称为数据库软件(产品),用于管理DB中的数据
3.SQL:结构化查询语言,用于和DBMS通信的语言
基本SQL操作
1.操作数据库
-- 查询数据库
show databases;
-- 创建数据库
create database newDatabase;
-- 删除数据库
drop database newDatabase;
2.操作数据表
-- 选择指定数据库
use testDB;
-- 查询当前数据库下的全部数据表
show tables;
-- 创建表
create table tb_user(
id int(11) not null auto_increment primary key,
name varchar(255) not null,
age int(11)
);
-- 创建表,存在则不会创建
create table if not exists tb_user2(
id int(11) not null auto_increment primary key,
name varchar(255) not null,
age int(11)
);
-- 使用旧表创建新表(只复制表的结构,不复制表的数据)
create table newTable like tb_user;
-- 使用旧表(部分列)创建新的表(既复制表的结构又复制表的数据)
create table newTables as select id,name,age,matching from tb_user;
-- 使用就表创建新表(全部列,既复制表的结构又复制表的数据)
create table newTable1 as select * from tb_user;
-- 查询表的结构
desc testAlter;
show columns from testAlter;
-- 将A表的查询结果插入到B表中。
insert into tb_new_user select * from tb_user;
-- 清除表中的数据
-- 注意:删除表的所有行,但表的结构、列、约束、索引等不会被删除;不能用于有外建约束引用的表
truncate table tb_new_user;
-- 删除表如果存在
drop table if exists tb_new_user2;
-- 对数据表的列进行操作
-- 对表的重命名
alter table tb_user1 rename [TO] tb_new_user1;
-- 增加列
alter table tb_user add new_column varchar(255) comment '这是新增列';
alter table tb_user add column new_column varchar(255) comment '这是新增列';
alter table tb_user add column new_column varchar(255) not null comment '这是新增的非空列';
alter table tb_user add column new_column int(11) not null default 0 comment '这是新增非空默认为0的列';
-- 删除列
alter table tb_user drop column newColumn;
alter table tb_user drop newColumn;
-- 修改列
alter table tb_user change column new_column newColumn varchar(256) not null ;
alter table tb_user change column new_column newColumn int(11) not null default 0 comment '修改列名';
3.select语句
1.普通查询
-- 查询整张表的所有列
select * from tb_user;
-- 查询指定列
select id, name from tb_user;
2.distinct
-- 使用 distinict语句 (获得不同的值)(查询结果的所有列与别的记录)
select distinct name,age from tb_user;
select distinct name from tb_user;
3.where
-- where 子句 筛选
select * from tb_user where id = 1;
4.order by
-- 按id降序
select * from tb_user order by id desc;
-- 按id升序
select * from tb_user order by id asc;
-- 多条件排序
select * from tb_user order by name,age asc;
5.and , or
-- and 子句
select * from tb_user where name = 'yanghao' and age = 21;
-- or 子句
select * from tb_user where name = 'yanghao1' or age = 21;
6.like
-- like 子句 模糊查询
select * from tb_user where name like '%hao';
select * from tb_user where name like 'yang%';
select * from tb_user where name like '%yang%';
-- % - 百分号表示零个,一个或多个字符
-- _ - 下划线表示单个字符
select * from tb_user where name like 'yanghao_';
7.between and
-- BETWEEN运算符是包含性的:包括开始和结束值。
-- between and
select * from tb_user where id between 1 and 2;
select * from tb_user where id not between 1 and 2;
8.null
-- is null ,is not null
select * from tb_user where matching is null;
select * from tb_user where matching is not null;
9.limit
-- limit
select * from tb_user limit 2;
-- 去下标为1的开始,2条。注意与between and 进行区分
select * from tb_user limit 1,2;
10.in
-- IN 运算符
select * from tb_user where id in (1,2,3);
select * from tb_user where name in ('yanghao', 'lisi');
-- 利用子查询的结果作为in的元素
SELECT
*
FROM
tb_user
WHERE
NAME IN ( SELECT NAME FROM tb_user WHERE id IN ( 2, 3 ) );
select * from tb_user;
11.case
-- switch(case) 语句
SELECT
id,
NAME,
age,
(CASE matching WHEN 0 THEN '零' WHEN 1 THEN '壹' WHEN 2 THEN '贰' end) AS number
FROM
tb_user;
12.if
select if(true,'yes','no') as status;
-- if 函数
select id,name,age,matching , if(sex = 'w','女','男') as '姓别' from tb_user;
12.group by
-- group by
select sex, count(sex) count from tb_user group by sex;
select name, count(*) count from tb_user group by name;
select name,age,count(*) count from tb_user group by name,age;
13.union
-- 并集,将多个结果连接起来
select * from tb_user where name like '%hao%'
union
select * from tb_user where age = 18;
4.insert语句
-- insert插入语句
-- (两种,一种是插入全部字段,则可以简化为如下)
insert into tb_user values(6,'zhangsan',18,1,1);
insert into tb_user (name,age,matching, newColumn) values( 'zhangsan',20,1,1);
5.update语句
-- update 更新语句
update tb_user set name = 'lisi' where id = 4;
6.delete语句
-- delete 删除语句
delete from tb_user where id = 5;
7.函数
-- 个数
select count(*) as totalCount from tb_user;
-- 总和
select sum(age) as totalAge from tb_user;
-- 平均值
select avg(age) as avgAge from tb_user;
-- 最大
select max(age) as maxAge from tb_user;
-- 最小
select min(age) as minAge from tb_user;
8.事务
create table runoob_transaction_test ( id int(5)) engine = innodb; # 创建数据库
select * from runoob_transaction_test;
begin;
insert into runoob_transaction_test (id) values (5);
insert into runoob_transaction_test (id) values (6);
commit;
select * from runoob_transaction_test;
begin;
insert into runoob_transaction_test (id) values (7);
rollback;
select * from runoob_transaction_test;
commit;
SQL 连接(JOIN)
INNER JOIN:如果表中有至少一个匹配,则返回行
LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行
RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行
FULL JOIN:只要其中一个表中存在匹配,则返回行
0.Sql 之 笛卡尔积
注释:INNER JOIN 与 JOIN 是相同的。
数据库表:
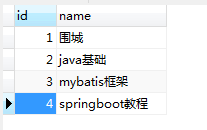
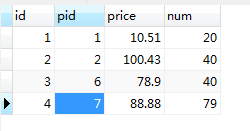
首先,我们需要先明白一个概念——笛卡尔积:
笛卡尔积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
例子:
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为
{
(a, 0),
(a, 1),
(a, 2),
(b, 0),
(b, 1),
(b, 2)
}。
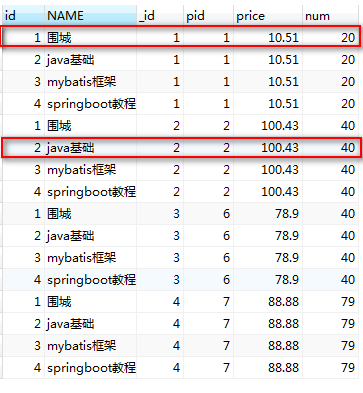
现在来观察上面两个表形成的笛卡尔积:
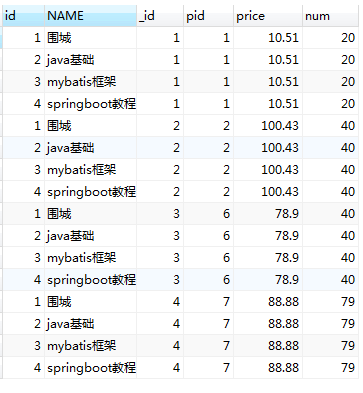
1.Sql 之 inner join
注释:INNER JOIN 与 JOIN 是相同的。(相当于取交集)
注释:INNER JOIN 关键字在表中存在至少一个匹配时返回行。
SQL join 用于把来自两个或多个表的行结合起来。
最简单的就是内连接,inner join.
-- 使用where连接
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
FROM
product p,
product_detail pd
WHERE
p.id = pd.pid;
-- inner join or join
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
from product p
INNER join product_detail pd
on p.id = pd.pid;
以上两种方式查询的结果是一样的。(两个都相当于内连接)
总结:内连接inner join是将两个或两个以上的表连接起来,用on来连接,只用当on所限制的条件满足的时候,笛卡尔积组成的结果行才会返回。
如下图:(只有on后面的条件,p.id = pd.pid成立的时候)
2.Sql 之 left join | left outer join
注释:LEFT JOIN 关键字从左表(Websites)返回所有的行,即使右表(access_log)中没有匹配。
-- left join or left outer join
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
from product p
left join product_detail pd
on p.id = pd.pid;
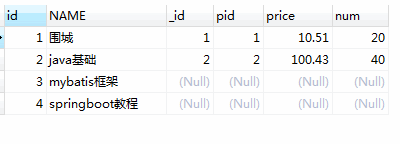
在左连接的基础上加上过滤条件
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
from product p
left join product_detail pd
on p.id = pd.pid and p.id = 1
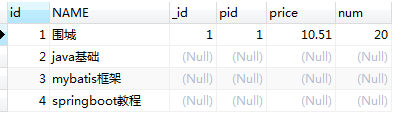
使用where进行过滤的

注意:在使用 left jion 时,on 和 where 条件的区别如下:
- 1、 on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录。
- 2、where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
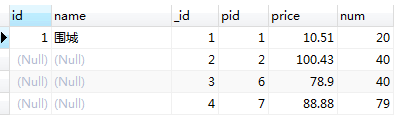
3.Sql 之 right join | right outer join
注释:RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
select
p.id,
p.name,
pd.id as _id,
pd.pid,
pd.price,
pd.num
from product p
right join product_detail pd
on p.id = pd.pid
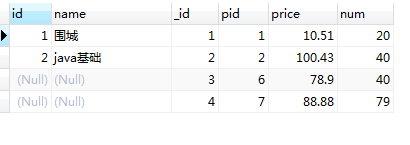
加入过滤条件的有连接 on 后面接and进行过滤
select
p.id,
p.name,
pd.id as _id,
pd.pid,
pd.price,
pd.num
from product p
right join product_detail pd
on p.id = pd.pid
and pd.pid = 1
select
p.id,
p.name,
pd.id as _id,
pd.pid,
pd.price,
pd.num
from product p
right join product_detail pd
on p.id = pd.pid
-- and pd.pid = 1
where pd.pid = 1

使用on过滤和where过滤跟上面的左连接是一样的。
4.Sql 之 full join | full outer join
注释:FULL OUTER JOIN 关键字返回左表(Websites)和右表(access_log)中所有的行
(使用方式如上面两种那样,但是mysql不支持全连接)
5.Sql 之 union and union all
但是可以使用union关键字来实现所谓的全连接
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
FROM
product as p
left JOIN product_detail pd
ON p.id = pd.pid
UNION
SELECT
p.id,
p.NAME,
pd.id AS _id,
pd.pid,
pd.price,
pd.num
FROM
product p
right join product_detail pd
on p.id = pd.pid;
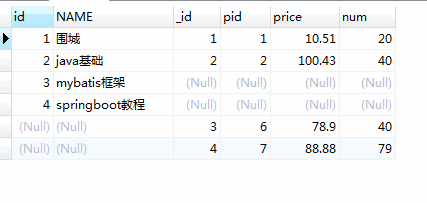
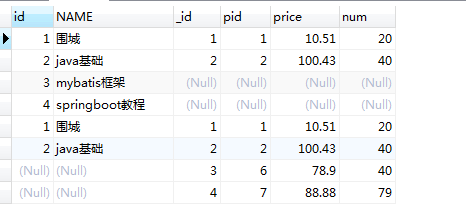
上面是使用的是union,不显示重复行,但是如果把union换成union all 那么就会把重复行显示出来,
效果如下图:(union all)
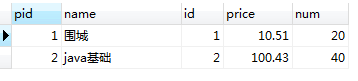
6.Sql 之 natural join
SELECT
*
FROM
product
NATURAL JOIN product_detail
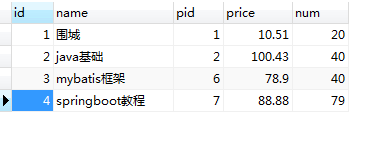
注释:自然连接默认是匹配两个表列名相同的,然后不重复显示。
如下图,将数据库表设计改变:(改变第一个表的id名为pid)
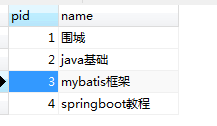
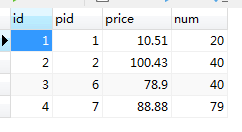
结果如下:
哪些情况需要建立索引
- 1.主键自动建立唯一索引
- 2.频繁作为查询条件的字段应该建立索引
- 3.查询中与其他表关联的字段,外键关系建立索引
- 4.频繁更新的字段不适合创建索引 --- 因为每次更新不单单是更新了记录还会更新索引,加重了IO负担
- 5.where条件里用不到的字段不创建所以
- 6.单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
- 7.查询中排序的字段,排序字段若通过索引去访问将大大提高排序的速度
- 8.查询中统计或者分组字段
哪些情况不要创建索引
1.表记录太少
2.经常增删改的表 (why:提高了查询速度,同时却会降低更新表的速度,如对表进行insert,update,delete,因为在更新表时,mysql不仅要保存数据,还需要保存一下索引文件)。
3.数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。
注意:如果某个数据列包含许多重复数据的内容,为它建立索引就没有太大的实际效果。
性能分析> Explain
解释:
使用Explain关键字可以模拟优化器执行sql查询语句,从而知道mysql是如何处理你的sql语句。
分析你的查询语句或者是表结构的性能瓶颈。
能干嘛:
- 1.表的读取顺序
- 2.数据读取操作的操作类型
- 3.哪些索引可以使用
- 4.哪些索引被实际引用
- 5.表之间的引用
- 6.每张表有多少行被优化器查询
语法:
explain sql

id:
select 查询的序列,包含一组数字,表示查询中执行select字句或操作表的顺序
三种情况:
1.id相同,执行顺序由上到下
2.id不同,如果是子查询,id序号会递增,id值越大优先级越高,越先被执行。
3.id不同,同时存在
select_type:
查询的类型,主要是用于区别 普通查询、联合查询、子查询等的复杂查询
1.simple
简单的select查询,查询中不包含子查询或者union
2.primary
查询中若包含任何复杂的子部分,最外层查询则被标记为primary。
3.subquery
在select或where列表中包含子查询
4.derived
在from列表中包含的子查询被标记为derived(衍生) mysql会递归执行这些子查询,把结果放在临时表中
5.union
若第二个select出现在union之后,则会标记为union;若union包含在from子句的子查询中,
外层select将标记为:derived
6.union result
从union表获取结果的select、。
table:
显示这一行的数据是关于哪一张表的
type:
显示查询使用了哪种类型:(好>查)
system > const > eq_ref > ref > range > index > all
system:
表只用一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也忽略不计
const:
表示通过索引一次就找到了,const用于比较primary key或unique索引。因为只匹配一行数据,索引很快,
如果将主键置于where列表中,mysql就能将该查询转换为一个常量。
eq_ref:
唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
ref:
非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行
然而,它可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。
range:
只检索给定的范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where字句中出
现了between,<,> ,in 等查询,这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,
而结束与另一点,不用扫描全部索引。
index:
full index scan, index 与 all区别为index类型只遍历索引树,这通常比all快,因为索引文件通常比
数据文件小。(也就是说虽然all和index都是读全表,但是index是从索引中读取的,而all是从硬盘中读取的)
all:
full table scan,将遍历全表以找到匹配的行。
备注:一般来说:得保证查询至少达到range级别,最好能达到ref。
possible_keys:
显示可能应用在这张表中的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
key:
实际使用的索引。如果为null,则没有使用索引。
查询中若使用了覆盖索引,则该索引和查询的select字段重叠。
key_len:
表示索引中使用的字节数,key 通过该列计算查询中使用的索引的长度,在不损失精确性的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算得到,而不是通过
表内检索得出。
ref:
显示索引的哪一列被使用了,如果可能的话,是一个常数,哪些列或常量被用于查找索引列上的值
rows:
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
extra:
包含不适合在其他列中显示但十分重要的额外信息
1.using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。mysql中无法利用索引
完成的排序操作称为“文件排序”。
2.using temporary
使用了临时表保存中间结果,mysql在对查询结果排序时使用临时表,常见于排序order by 和
分组查询group by
3.using index
表示相应的select操作中使用了覆盖索引,避免访问了表的数据行,效率不错。
如果同时出现了using where,表明索引被用来执行索引键值的查找。如果没有同时出现using where,
表明索引用来读取数据而非执行查找动作。
4.using where
表明使用了where过滤
5.using join buffer
使用了连接缓存
6.impossible where
where字句的值总是false,不能用来获取让任何元组
7.select tables optimized away
在没有group by字句的情况下,基于索引优化min/max操作或者对于myisam存储引擎优化count(*)操作。
不必等到执行阶段在进行计算,查询执行计划生成的阶段即完成优化
8.distinct
优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作。
索引失效
1.全值匹配我最爱
2.最佳左前缀法则(如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左列并且不跳过索引中的列)
3.不在索引列上做任何操作(计算,函数,(自动或手动)类型转换),会导致索引失效而转向全表扫描
4.存储引擎不能使用索引中范围条件右边的列
5.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
6.mysql在使用不等于(!=货值<>)的时候无法使用索引而导致全表扫描、
- is null. is not null 也无法使用索引
8.like 以通配符开头('%abc...')mysql索引失效会变成全表扫描的操作
9.字符串不加单引号索引失效
10.少用or,用它来连接时会索引失效