正如上一篇我们提到过,进程是Linux系统中仅次于文件的基本抽象概念。正在运行的进程不仅仅是二进制代码,而是数据、资源、状态和虚拟的计算机组成。我们今天主要介绍进程的概念,组成,运行状态和生命周期等。
1、进程的概念
进程就是处于执行器的程序(目标代码放在某种存储介质上)。
但进程并不仅仅局限于一个可执行程序代码,通常还要包含其他资源,比如:
打开的文件,挂起的信号,内核内部数据,处理器状态,一个或多个具有内存映射的内存地址空间,一个或多个可执行线程,存放全局变量的数据段等。
内核需要有效而又透明地管理所有细节。
执行线程(thread of execution),简称线程(thread),是进程中活动的对象。每个线程都拥有自己的虚拟存储器,包括程序计数器,栈,一组进程寄存器。
一个进程只有一个虚拟内存实例,所以,进程下的所有线程共享相同的内存地址空间。
进程的另一个名字是任务(task),Linux内核通常把进程叫做任务。
2、进程描述符及任务结构
内核把进程列表存放在任务队列(task list)的双向循环链表中。链表中的每一个节点都是类型为task_struct称为进程描述符(process descriptor)的结构。
每个进程描述符都包含了一个具体进程的所有信息。在32位机器上,大约有1.7KB。所以它包含了前面进程的定义中提到的“打开的文件,挂起的信号......”诸多信息。
Linux内核通过slab分配器分配task_struct结构,这样能达到对象复用和缓存着色的目的。在Linux2.6后面的内核中,每个任务的新的thread_info结构在内核栈的尾端分配,该结构中task指针存放的是指向该任务实际task_struct的指针。
而事实上,Linux内核栈是比较小的,在x86上,32位机的内核栈8KB,64位机是16KB。当然可以配置,每个处理器也都有自己的栈。但是也说明了内核栈不大,而一个进程描述符占了1.7KB,已经是相对较大了。
内核通过一个唯一的进程标识值PID来标识每个进程。PID是一个数,实际上为int类型。PID的最大默认值为32768。当然可以配置。
这个值代表了系统中可以同时存在的进程的最大数目,值越小,转一圈就越快。但是值一大,如果要切换进程,又成了一问题。该PID存在task_struct结构中,实际上最终目的是得到进程描述符。所以通过current宏找到当前正在运行的进程的速度显得尤为重要,硬件体系结构不一样,处理不一样。有的通过专门的寄存器存放当前进程描述符指针。而x86寄存器有限,只能在内核栈尾端创建thread_info结构,通过计算偏移间接地查找task_struct结构。
3、进程状态
进程的状态如下图所示,分为五种,系统中的每个进程一定处在其中的一种。进程的当前状态存储在进程描述符的state域。
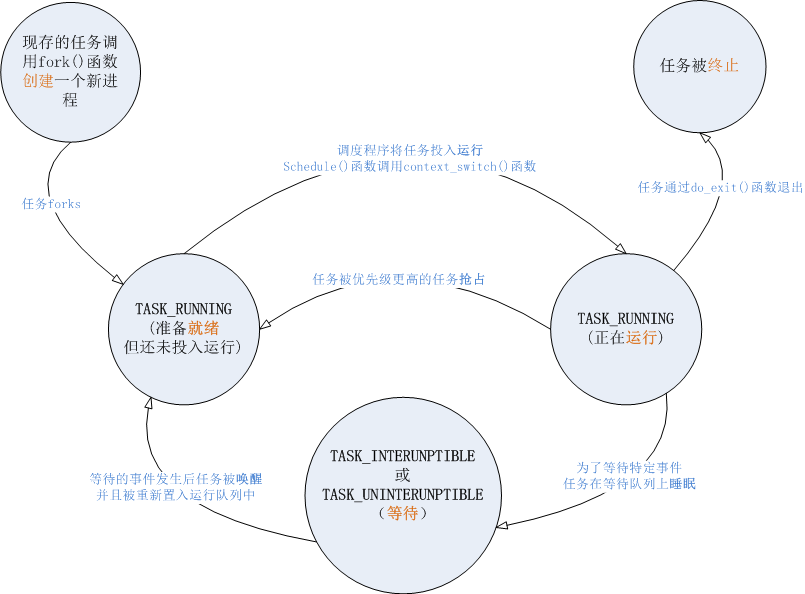
该进程状态图非常准确而简要的描述了进程状态的切换,说明了进程从创建到运行到销毁的过程,也说明了进程被抢占或者被中断的转换过程。当然可能需要结合书或者这连续几章的介绍会了解得更加深刻。
下面我们先分开描述五个状态的含义。
TASK_RUNNING(运行):进程是可执行的,就绪或者正在运行。就绪表示已经加入到运行队列中等待执行。同时,该状态也是进程在用户空间中唯一可能的状态,所以只有该状态在用户空间和内核空间都能表示。
TASK_INTERRUPTIBLE(可中断):进程正在睡眠(即被阻塞),等待某些条件的达成即可被唤醒。
TASK_UNINTERRUPTIBLE(不可中断):该进程即使在等待时也不受干扰,不接收信号,使用较少。
注,ps aux查看进程stat字段为D状态,不可中断又不能杀死的进程。它可能正在执行一个重要的任务或者持有一个信号。进程启动之初也是处于这个状态。
__TASK_TRACED:被其他进程跟踪的进程,例如通过ptrace对调试进程进行跟踪。
__TASK_STTOPED(停止):进程停止执行;进程没有投入运行也不能投入运行。
细心的你可能会发现,这五个状态和图上的五个状态明显不一样。是的,但我认为都没毛病。上图是整体的状态切换,而这里应该是作者站在内核的角度进行列举。
4、进程上下文的定义
TASK_RUNNING中我们提到了用户空间和内核空间,我们在这里在从进程状态来看看进程上下文的定义。
进程上下文在上一篇基本概念中提到过。
可执行程序代码是进程的重要组成部分,这些代码从一个可执行文件载入到进程的地址空间执行。
一般程序在用户空间执行,当一个程序执行了系统调用或者触发了某个异常,它就陷入内核空间。此时,我们称内核“代表进程执行”并处于进程上下文中。
注1:系统调用和异常处理程序是内核与外界的接口的统称,即内核的所有访问都必须通过这些接口。
注2:中断上下文在基础概念中亦提过,在中断上下文中,系统不代表进程执行,而是执行了一个中断处理程序,而往往和驱动相关。所以不会有进程干扰它,此时也不会存在进程上下文。也可以理解为内核要么处于进程上下文中,要么处于中断上下文中,当然也可以休息用户空间工作即可。
5、进程ID与进程树
每个进程都有唯一的ID进行标识,即进程ID,简称PID。在Linux系统中,进程之间存在一个明显的进程关系,所有的进程都是PID为1的init(centos 7为systemd)进程的的后代。
而PID为0表示空闲进程,即当没有其他进程在运行时,内核运行该空闲进程。
所以,每一个进程都有一个父进程,每一个进程也可以拥有0个或者多个子进程,这样组成了一颗进程树。
6、进程的创建、执行和终止
Unix的进程创建很特别。许多其他的操作系统都提供了产生(spawn)进程的机制,首先在新的地址空间里创建进程,读入可执行文件,最后开始执行。
Unix与之不同,将上述的步骤分解到两个单独的函数中去执行:fork()和exec()。exec()代表了execve()等一系列函数。
首先创建一个新的进程,然后,通过exec系统调用把新的二进制程序加载到该进程中。
6.1 fork()系统调用
Linux通过clone()系统调用实现fork()。
fork()、vfork()和__clone()库函数都根据各自需要的参数标志去调用clone(),然后clone()去调用do_work()。
写时复制
传统的fork()系统调用直接把所有的资源复制给新创建的进程。现代的Linux操作系统使用写时复制(copy-on-write COW)页来实现。
写时复制是一种可以推迟甚至免除复制数据的技术(惰性算法),内核此时并不复制整个进程地址空间,父子进程共享同一份拷贝。
只有在需要写入时,数据才会进行复制,而且虚拟内存是分页来处理,某一页被修改了会产生缺页中断,该页才需要复制,所以使各个进程拥有各自的拷贝。所以加快了进程的创建。
再回到fork(),内核有意选择子进程首先执行。因为一般子进程马上调用exec()函数,这样避免写时复制的额外开销。因为如果父进程首先执行的话,有可能开始向地址空间写入。
通过fork()系统调用,可以创建一个和当前进程一样的进程。新进程称为原进程的“子进程”,原进程称为“父进程”。在子进程中,成功的fork()返回0;在父进程中,fork()会返回子进程的pid。
除了一些本质性区别,父子进程在其他各方面都是相同的:
- 子进程的资源统计信息清零;
- 所有挂起的信号都会被清除,也不会被子进程继承;
- 所有文件锁也都不会被子进程所继承。
vfork()
它是在COW出现之前的一种进程创建方式,现在因为有了COW,所以该方式已经基本不使用了。
除了不能拷贝父进程的页表项外,它和fork()的功能相同。子进程作为父进程的一个单独线程在它的地址空间运行,父进程被阻塞,直到子进程退出或者执行exec()。
线程在Linux中的实现
Microsoft Windows或Sun Solaris等操作系统在内核中提供了专门支持线程的机制。而Linux操作系统中,线程看起来就像是一个普通的进程。
在Linux内核中,并没有线程的概念。所以它的创建和普通进程类似,只是需要选择不同的参数。
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
这些参数表示父子俩共享地址空间、文件系统资源、文件描述符和信号处理函数。
对比一下普通进程fork()的实现是:
clone(SIGCHILD, 0);
所以,传递给clone()的参数标志决定了新创建进程的行为方式和父子进程之间共享的资源种类。
内核线程
内核经常需要在后台执行一些操作。这种任务可以通过内核线程(kernel thread)完成——独立运行在内核空间的标准进程。
内核线程和普通进程的区别在于内核线程没有独立的地址空间!因为它们只在内核空间运行,不需要去用户空间。
内核线程和普通进程一样,可以被调度,可以被抢占。
我们在Linux系统中运行ps -ef命令,可以看到很多内核线程,比如flush和ksoftirqd等等。
内核是通过从kthreadd内核进程中衍生出来所有新的内核线程。
6.2 exec()系统调用
前面提到过exec()不是一具体函数,而是代表了6个函数,如下。
execl() execlp() execle()
execv() execvp() execve()
第一行三个函数表示参数是可变的,第二行表示参数是固定的,即可变的变成了数组。l表示list,v表示vector。
第二列的p表示会在用户的绝对路径下查找可执行文件,即参数指定的文件名必须在用户路径下。p代表path。
第三列的e表示会为新进程提供新的环境变量。
六个函数只有execve()是唯一的系统调用,其他是在其基础上封装的C库函数。
一个exec()系统调用会把二进制程序加载到内存中,替换地址空间原来的内容,并开始执行,这个过程称为“执行(executing)”一个新的程序。
execl("/bin/vi", "vi", NULL);
第一个参数表示二进制程序的路径,第二个参数一般表示程序名称,该程序是“vi”编辑器。NULL表示最后的参数,前面提到过l代表了可变参数。
execl("/bin/vi", "vi", "/home/test/123.txt", NULL);
上面的示例加了一个参数,该参数表示vi编辑的对象。
成功的execl调用不仅改变了地址空间和进程映像,还改变了进程的其他一些属性:
- 所有挂起的信号都会丢失。
- 捕捉到的所有信号都会还原为默认处理方式,因为信号处理函数已经不在地址空间了。
- 丢弃所有内存锁。
- 大多数线程的属性还原成默认值。
- 重置大多数进程相关的统计信息。
- 清空和进程内存地址空间相关的所有数据,包括所有映射的文件。
- 清空所有只存在于用户空间的数据,包括C库的一些功能(如atexit()的函数行为)。
但是进程的某些属性还是没有改变,如pid,ppid,优先级,所属的用户和组。
还有文件描述符也被继承了下来,所以实际操作中一般会在调用exec前关闭打开的文件,当然也可以通过fcntl(),让内核去自动完成关闭操作。
6.3 进程终止
exit()系统调用
一般来说,进程的析构是自身引起的。它发生在进程调用exit()系统调用时,即可以显示调用,也可以隐式地从某个程序的主函数返回(如C语言编译器会自动在main()函数的返回点加上exit())。当然也可能被动的终结,比如信号通知或异常处理等。不管进程如何终结,该任务大部分通过do_exit()来完成。
在终止进程之前,C库会按顺序执行以下关闭进程的步骤。
- 调用任何由atexit()或on_exit()注册的函数,和在系统中注册时顺序相反。
- 清空所有已打开的标准I/O流。
- 删除由tmpfile()函数创建的所有临时文件。
这些步骤完成了在用户空间需要做的所有工作,最后exit()会调用_exit(),内核可以处理终止进程的剩余工作。
内核清理进程创建的、不再使用的资源,包括但不局限于:分配内存、打开文件和System V的信号量。清理完成后,内核会摧毁进程并告知父进程其子进程已近终止。
注:atexit()是POSIX标准函数,而on_exit()是SunOS 4定义的,新版本的Solaris也不再支持了。atexit()主要用来指定的注册函数作为终止函数。
按上述方式将进程终结后,系统还保留了它的进程描述符,在父进程获得已经终结的子进程的信息后,或者通知内核它并不关注那些信息后,子进程的task_struct结构才会被释放。
等待子进程终止
如果父进程在子进程之前退出,必须有机制来保证子进程能找到一个新的父亲,否则这些成为孤儿的进程就会在退出时永远处于僵尸(EXIT_ZOMBIE)状态,白白地耗费内存。
Linux内核提供了一些接口,可以获取已终止子进程的信息。
wait(), waitpid(), waitid(), wait3(), wait4()
前面三个是标准的POSIX标准定义的,后两个不是。常使用的是waitpid()函数,等待某个特定的子进程,当然也可以是一组进程,主要依据是第一个参数的值。
init进程会周期性地调用wait()来检查子进程,清除所有与其相关的僵尸进程。
ps:事实上,在实际项目中,碰到过几次僵尸进程,情况好的重启系统恢复正常,情况差的出现过重启失败,只能按电源键。所幸的是这种情况极少,出现僵尸进程一般是性能撑不住的情况下。但我的疑问是,为啥systemd进程没有检查到该僵尸进程呢??如果能检查到并清理的话,那么我们则只需再启动应用程序即可。
附录:
简单测试
#include <stdio.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
int main(){
int ret;
pid_t pid;
pid_t pidSelf = getpid();
printf("hello, my pid is %d~
", getpid());
pid = fork();
if (pid == -1)
return -1;
else if (pid == 0){
printf("hello, child process, my pid is %d
", getpid());
//exit(-1);
sleep(5);
}
else if (pid > 0){
printf("hello, father process, my pid is %d!
", getpid());
}
printf("hello world, my pid is %d!
", getpid());
waitpid(-1, NULL, 0);
printf("end, my pid is %d.
", getpid());
return ret;
}
输出结果:
hello, my pid is 2816~
hello, father process, my pid is 2816!
hello world, my pid is 2816!
hello, child process, my pid is 2817 //而后暂停5s.
hello world, my pid is 2817!
end, my pid is 2817.
end, my pid is 2816.
参考资料:
《Linux内核设计与实现》