一、前言
1、这一文开始进入Storm流式计算框架的学习
二、Storm简介
1、Storm与Hadoop的区别就是,Hadoop是一个离线执行的作业,执行完毕就结束了,而Storm是可以源源不断的接受数据源,不停的对数据进行处理,而数据就行水流一样不停的流进来,经过处理,再将结果存入数据库或者做其他用途
2、基础概念
(1)Tuple(元组):数据流传递的基本单元,相当于数据的流动通过Tuple作为对象来传递
(2)Spout(龙卷):相当于数据源,通过重写nextTuple()方法,源源不断的将数据流入我们的处理框架
(3)Bolt(闪电):处理数据的节点,通过重写execute()方法,接收Spout送出的数据,并进行任意的业务处理,处理完毕还可以将数据继续流入下一个Bolt,组成一条链
(4)Topology(拓扑):连接以上各个组件,使其组成一个拓扑结构,比如将多个Bolt组成一条数据链
3、举例说明:比如我们现在要统计一下《战争与和平》这本书的每个英文单词出现的数量
(1)编写Spout代码,将书的内容源源不断的通过句子输入到我们的体系中
(2)编写多个Bolt来处理数据,比如第一个Bolt专门来将句子切分成单词,第二个Bolt专门来统计每个单词出现的数量,每个Bolt之间通过定义Bolt来流动数据,比如统计的Bolt,定义一个二元元组(单词,数量),第一个值就是具体的单词,第二个值就是这个单词出现的数量
(3)通过Topology将以上组件连接成一个完整的系统
三、Storm安装
1、下载Storm的tar.gz包,并解压
tar zxvf /work/soft/installer/apache-storm-1.2.2
2、修改配置文件
(1)storm.ymal,分别配置我们的Zookeeper集群(前文中已经搭建好了)的各个节点和nimbus节点的高可用性,避免单点故障,我们的环境有两个机器,所以都写上
vim /work/soft/apache-storm-1.2.2/conf/storm.yaml storm.zookeeper.servers: - "storm1" - "storm2" nimbus.seeds: ["storm1", "storm2"]
3、输入python检查一下机器是否安装了python,如果没有则安装python,安装完毕再执行python,发现可以进入,然后ctrl+D退出即可
apt-get install python-minimal
4、启动Storm集群,通过以下命令分别启动nimbus、supervisor和控制台UI,nohup可以当SSH客户端关闭时,不会将进程杀死,后缀加一个&,可以理解为让进程在后台运行
nohup /work/soft/apache-storm-1.2.2/bin/storm nimbus & nohup /work/soft/apache-storm-1.2.2/bin/storm supervisor & nohup /work/soft/apache-storm-1.2.2/bin/storm ui &
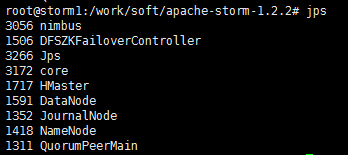
4、通过jps命令查看进程是否正常启动,如果看到config_value,说明还没启动完毕,稍等一下就好了

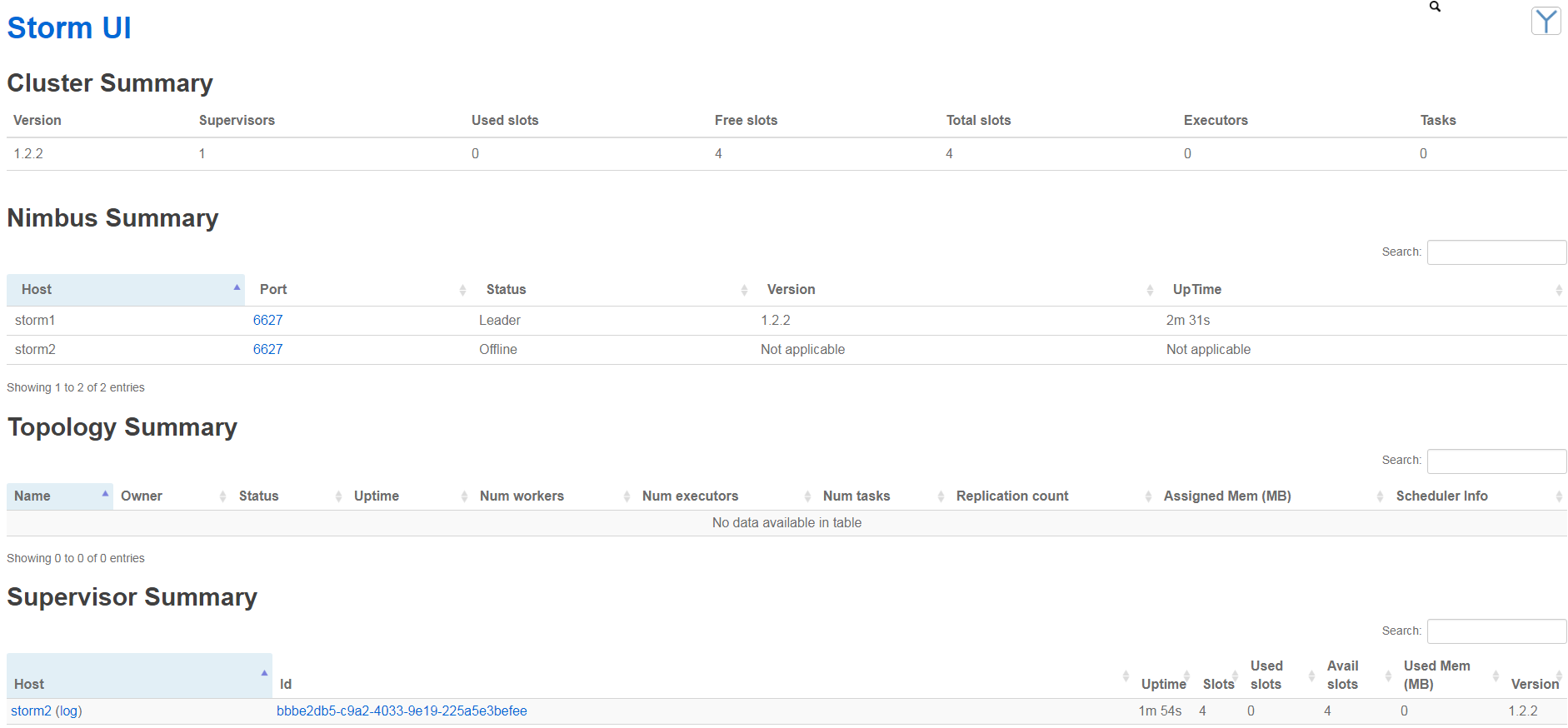
5、打开8080端口,可以看到控制台,正常运行
四、Storm代码编写
我们根据以上的思路写一个简单的单词统计任务,我们先放在开发环境上面跑代码,是不需要Storm集群环境的,等我们写好代码并在本地跑通后,就可以搭建Storm集群,在集群上面跑了,关于单词统计的代码网上很容易找到,下面阐述一下实现的思路,可以对照着以下文字来看代码,更好理解
1、创建一个maven工程,引入以下依赖,由于我这里的思路是:通过Rabbitmq获取消息数据,Storm进行数据流处理,将结果存储为Json格式并存入HBase。所以我需要引入如下依赖
<!-- HBase -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.1.1</version>
</dependency>
<!-- Storm -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.4</version>
<scope>provided</scope>
</dependency>
<!-- Json -->
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20140107</version>
</dependency>
<!-- RabbitMQ -->
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.5.0</version>
</dependency>
2、因为要使用HBase,所以参照上文的操作,还要将Hadoop的配置文件拷贝到项目中。环境搭建好后,开始编写代码
3、首先编写Spout,也就是数据的来源,创建一个类实现IRichSpout接口,并重写nextTuple()方法,在这个方法里实现数据的生产,比如读取数据库(RDS或NoSQL),从消息队列获取数据(Kafka、RabbitMQ),将输出的数据定义成Tuple(元组),通过重写declareOutputFields()方法,定义元组的key和数量,然后在nextTuple()方法中将元组的内容通过emit()方法传递到下一个组件
4、编写Bolt,也就是数据的处理者,创建一个类实现IRichBolt接口,并重写execute(Tuple tuple)方法,这个方法就是处理数据的逻辑了,在这里可以编写各种代码对接收到的Tuple进行处理,处理完毕后,和Spout一样,可以将数据通过定义Tuple的方式传递到下一个组件,每个Bolt会对数据进行特定的处理,然后传递给下一个Bolt,这样就可以组成一条数据流的处理链
5、编写Topology,拓扑将上面编写的组件连接起来,组成一个拓扑图,数据就在这个拓扑图里面持续的“流动”,永不停歇,拓扑也是程序的入口,所以创建一个主函数,在主函数里面创建一个TopologyBuilder对象,通过setSpout()、setBolt()方法将上面的组件连接起来,连接的方式涉及到Storm的八种Grouping策略
(1)Shuffle Grouping(随机分组):最常用的分组方式,将Tuple平均随机分配到各个Bolt里面
(2)Fields Grouping(字段分组):根据指定字段进行分组,比如我们按照word字段进行分组,相同word值的Tuple会被分配到同一个Bolt里面
(3)All Grouping(广播分组):所有的Bolt都可以收到Tuple
(4)None Grouping(无分组):将Tuple随机分配到各个Bolt里面
(5)Global Grouping(全局分组):将Tuple分配到task id值最低的task里面
(6)Direct Grouping(直接分组):生产者Bolt决定消费者Bolt可以接受的Tuple
(7)Local or Shuffle Grouping(本地或者随机分组):Bolt在同一进程或存在多个task,元组会随机分配这些task
(8)Custom Grouping (自定义分组):通过实现CustomStreamGrouping接口来定义自定义分组
6、通过TopologyBuilder连接好各个组件后,就可以提交任务了,提交任务分两种方式:本地提交和集群提交
(1)本地提交:提交到开发环境中,不需要安装Storm环境,只需要引入Storm的依赖包即可,使用LocalCluster类的submitTopology方法提交任务
(2)集群提交:提交到Storm集群中,使用StormSubmitter类的submitTopology方法提交任务
五、提交jar包到集群
1、首先我们要修改一下pom文件,将之前引入的storm-core依赖里面加<scope>provided</scope>,目的是storm-core这个依赖排除掉,因为这个依赖只是本地测试调试依赖的,集群中不需要这个依赖,如果不加会报错,还要记得修改拓扑的代码,使用StormSubmitter类来提交
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.0.4</version>
<scope>provided</scope>
</dependency>
2、通过编译器将我们的maven项目打包成jar
mvn clean install
3、将jar包拷贝到集群的集群里面,因为我们的代码使用到了HBase,所以要记得把项目中的配置文件夹也拷贝过来(core-site.xml、hbase-site.xml、hdfs-site.xml),jar是扫描不到jar包里的配置文件的,把配置文件放到与jar包同级目录下即可
4、执行命令将jar包提交到集群中运行,命令后面要记得指定主函数的全包名
nohup /work/soft/apache-storm-1.2.2/bin/storm jar /work/jar/mytest.jar com.orange.heatmap.Main &
5、进入8080控制台,可以看到我们刚才提交的拓扑,点击进去可以查看运行的状态
