Introduction
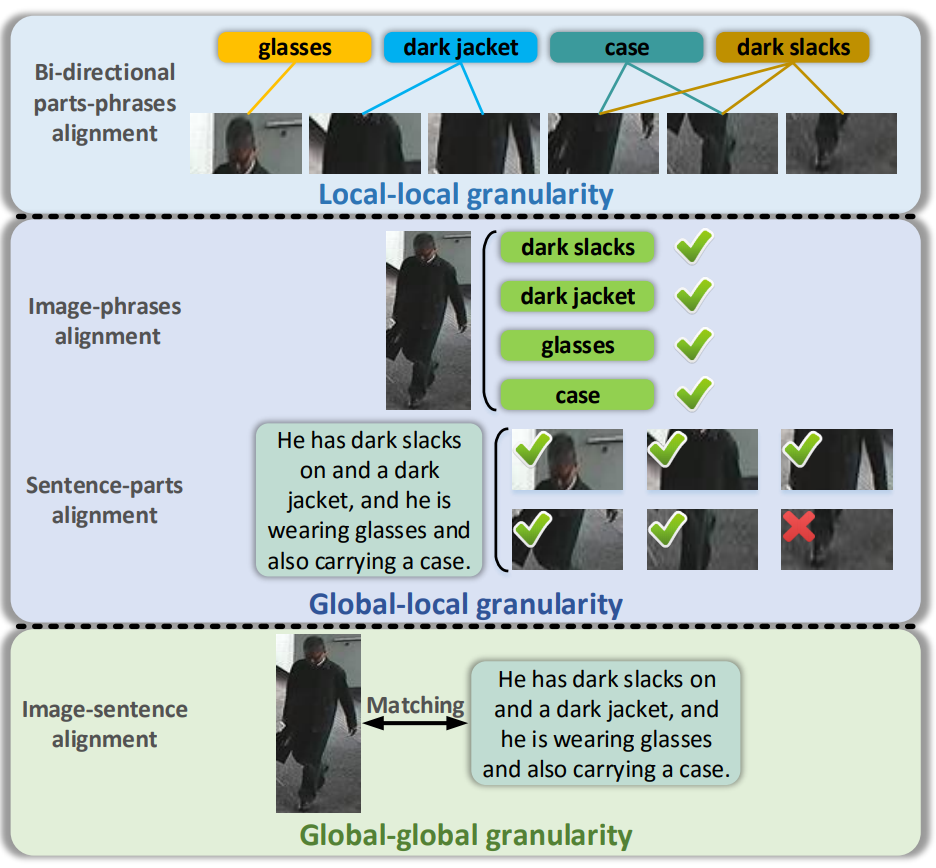
作者认为现有方法没有考虑跨模态之间局部与全局的关系,比如下图的一些情况。

为此作者提出了Multi-granularity Image-text Alignment (MIA) 方法实现global-global、global-local、local-local三种层面的对齐。具体而言,global-global层面对齐采用了Global Contrast (GC) 模块;global-local层面对齐挖掘了局部和全局的隐藏联系,并用Relation-guided Global-local Alignment (RGA) 模块来去除无关局部的影响;local-local层面对齐采用了Bi-directional Fine-grained Matching (BFM) 模块来匹配局部。
Proposed Approach
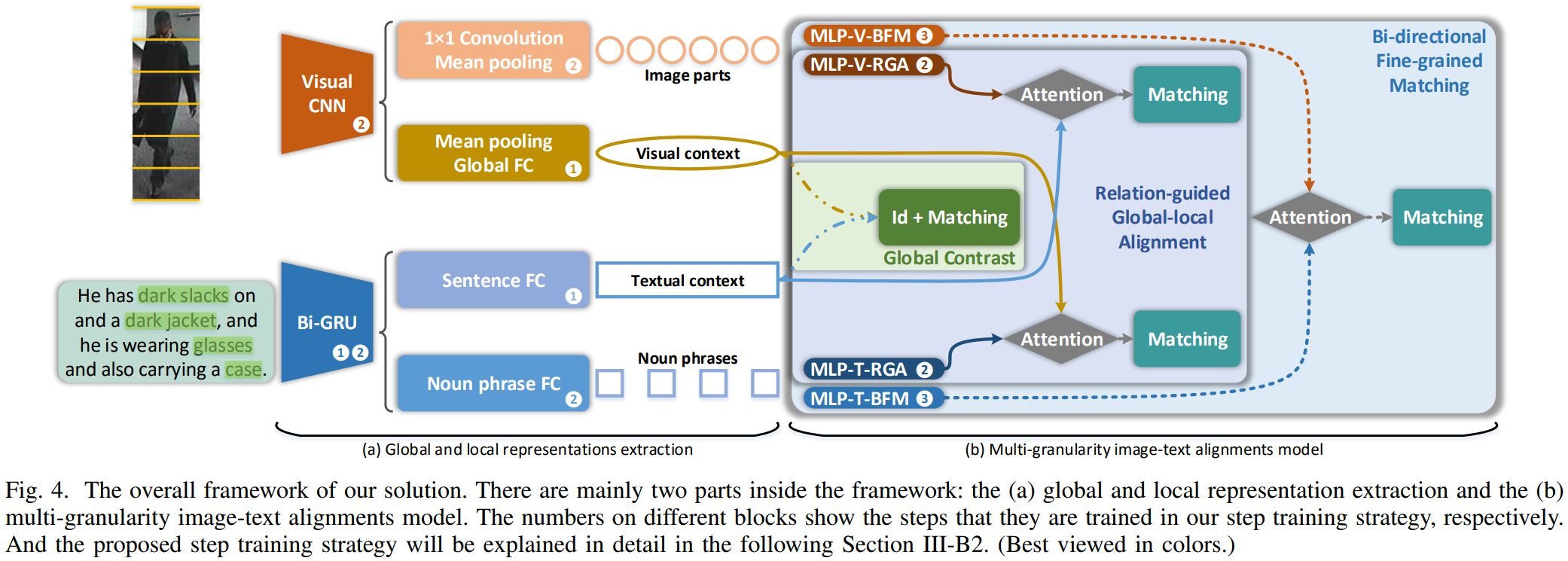
框架分为两部分:特征提取器和多粒度对齐模块。特征提取器分别提取了图像和文本的局部/全局特征。多粒度对齐模块具体如下:
(1)Global Contrast (GC):
图像的CNN特征提取容易理解。文本的全局特征是把双向的GRU的尾端输出级联,再通过FC获取。计算两种模态全局特征向量的相似度:
![]()
(2)Relation-guided Global-local Alignment (RGA):
图像的局部特征容易理解。文本的局部特征采用名词短语的hidden state输出。作者采用了Natural Language ToolKit (NLTK) 来获取名词短语。类似于全局文本特征的提取方法,每个名次短语都采用双向尾端输出级联+FC提取特征。
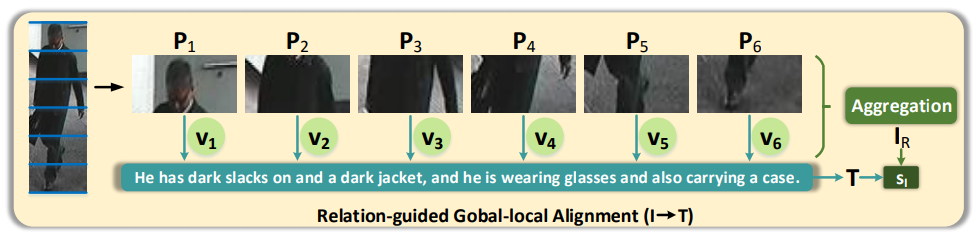
上图距离了图像局部特征与文本全局特征的对齐策略(文本局部特征与图像全局特征的对齐也同理)。每个图像局部与文本全局的关联度计算为:
![]()
其中![]() 表示视觉上的多层感知机,
表示视觉上的多层感知机,![]() 为相似度计算,通过关联度进行加权求和,得到新的视觉特征如下:(理解为注意力机制)
为相似度计算,通过关联度进行加权求和,得到新的视觉特征如下:(理解为注意力机制)
![]()
同理,也可以计算图像全局和文本局部的关联度,由此加权求和得到新的文本特征,即:
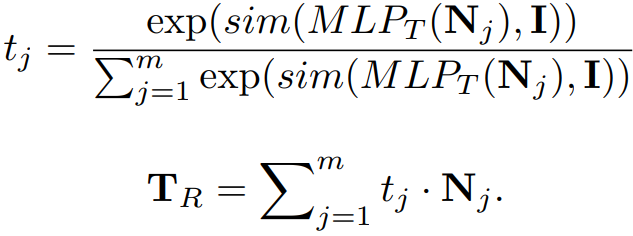
则新特征对应的相似度计算为:
![]()
![]()
(3)Bi-directional Fine-grained Matching (BFM):

思想与local-global类似,从图像角度出发,提取特征如上图所示,每个图像局部都和每个文本计算相关度,再加权求和得到视觉特征,计算过程如下:
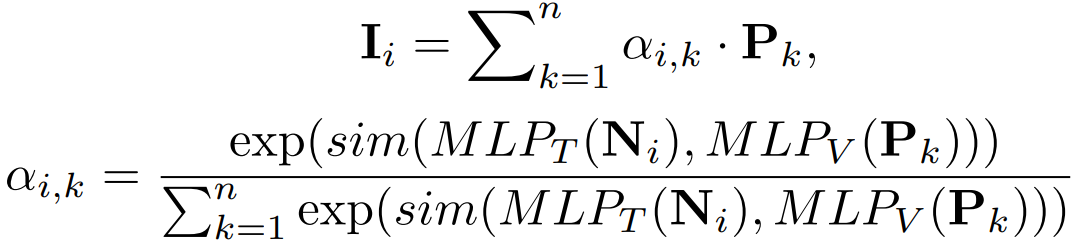
同理,从文本角度出发:

相似度计算分别为:
![]()
![]()
(4)相似度融合:

(5)学习策略:
目标函数包含两部分,一个是ID损失,即:

第二个是匹配损失,即:
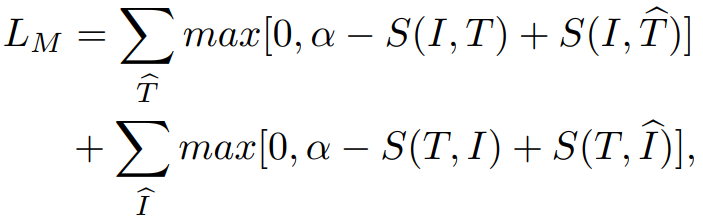
第一阶段仅使用ID损失训练全局特征,第二阶段使用ID损失和匹配损失联合训练全局-局部特征,第三阶段使用匹配损失训练局部-局部特征。
Experiments
(1)实验设置:
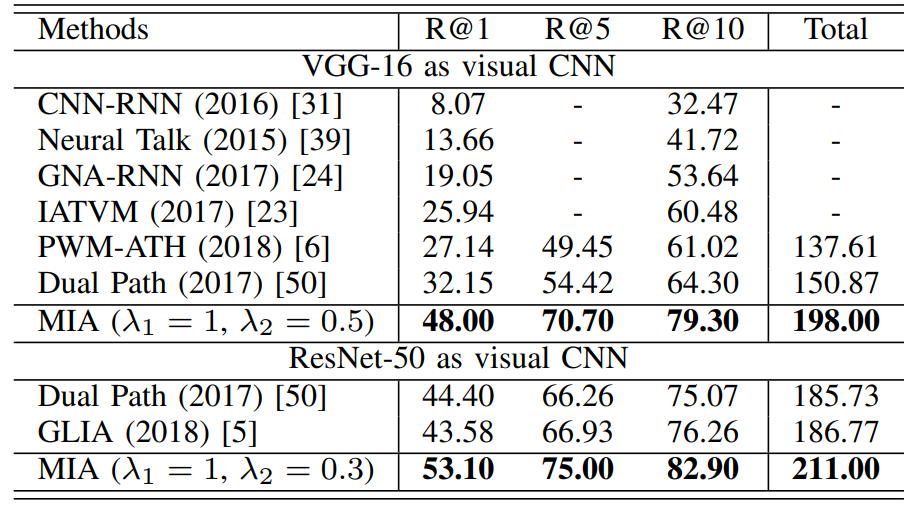
视觉CNN采用预训练的VGG-16、ResNet-50,图像裁剪为384x128,采用随机镜像进行数据增强,采用Cosine计算相似度,采用Adam优化器,batchsize设置为96。第一阶段的学习率设置为0.001,迭代10次;第二阶段的学习率设置为0.0002,每10次迭代下降0.1,迭代15次;第三阶段的学习率设置为0.0002,迭代5次。
(2)实验结果: