Introduction
图文检索问题上存在两个核心挑战:准确率以及速度。作者基于transformer提出了VisualSparta模型(Sparse Transformer Fragment-level Matching),兼顾了准确率和检索速度。本文的贡献包括:
1) 提出了一个新的基于片段交互作用的图文检索模型,并取得了SOTA的性能;
2) 反向索引 (Inverted index) 被证实对图文检索有效。
VisualSparta Retriever
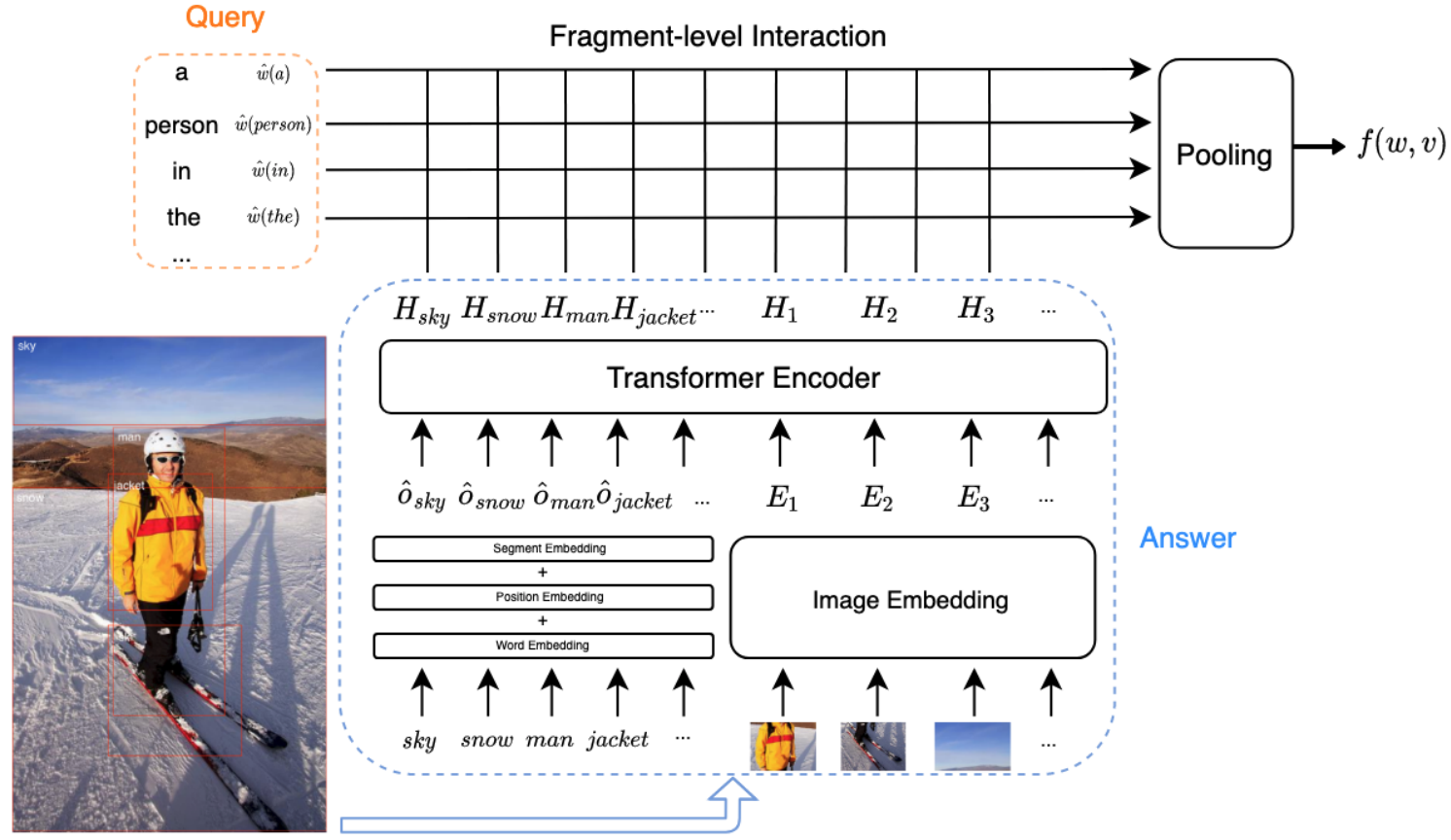
Query Representation
不同于一些方法对query编码成文本序列,本方法先将query编码成词向量,即:![]() ,其中
,其中![]() ,每个query可以表示为:
,每个query可以表示为:![]() 。
。
Visual Representation
对于每幅图像,作者采用了三种特征:局部的深度特征,局部的位置特征,目标标签特征。
1) 局部的深度特征 (regional deep feature):采用Faster-RCNN提取,即:![]() ;
;
2) 局部的位置特征 (regional location feature):每个局部都包含六个位置特征,即![]() ;
;
每个图像的局部都采用上述两个特征的级联:![]() ,图像特征为:
,图像特征为:![]() ;
;
3) 目标标签特征 (object label feature):对于每个局部都采用三种编码,即:word embedding、position embedding、segment embedding,即:![]() ,图像的标签特征为:
,图像的标签特征为:![]() 。
。
图像特征表示为:![]() ,最后再输入到Transformer中,即:
,最后再输入到Transformer中,即:![]() 。
。
Scoring Function
计算图文相似度采用如下过程:
先计算每个局部与每个单词的相似度,即:![]() ;
;
采用一个训练的bias和ReLU计算投影,即:![]() ;
;
对所有局部相似度取log并进行累加,即: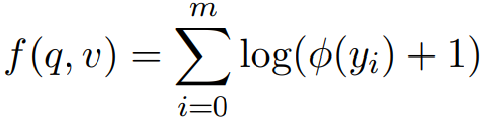 。
。
Retriever training
目标函数为:![]() 。
。
(反向索引那部分没有看的很明白)
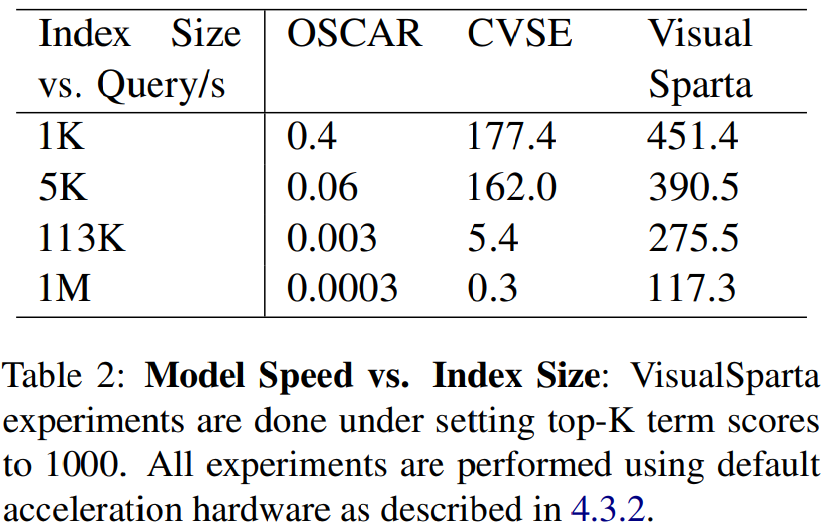
Experiments