Pytorch 基础操作
主要是在读深度学习入门之PyTorch这本书记的笔记。强烈推荐这本书
1. 常用类numpy操作
torch.Tensor(numpy_tensor)
torch.from_numpy(numpy_tensor)
GPU上的Tensor不能直接转换为Numpy ndarry,要用.cpu()将其转换到CPU
# 第一种方式是定义 cuda 数据类型
dtype = torch.cuda.FloatTensor # 定义默认 GPU 的 数据类型
gpu_tensor = torch.randn(10, 20).type(dtype)
# 第二种方式更简单,推荐使用
gpu_tensor = torch.randn(10, 20).cuda(0) # 将 tensor 放到第一个 GPU 上
gpu_tensor = torch.randn(10, 20).cuda(1) # 将 tensor 放到第二个 GPU 上
# 将tensor放回CPU
cpu_tensor = gpu_tenor.cpu()
-
得到tensor大小
.size()
得到tensor数据类型
.type()
得到tensor的维度
.dim()
得到tnsor的所有元素个数
.numel() -
全1矩阵。数据类型是floatTensor
torch.ones(n, m)
转化为整型数据/浮点型数据
.long().float()
返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数
torch.rand(n, m)
返回张量,包含了从标准正态分布(均值为0,方差为1,即高斯白噪声)中抽取的一组随机数。张量的形状由参数sizes定义torch.randn(n, m)返回一个1维张量,包含在区间start和end上均匀间隔的step个点
torch.linspace(start, end, steps=100, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)沿着维度dim取最大值
max_value, max_index = torch.max(x, dim)
沿着维度dim对x求和
torch.sum(x, dim)维度的变换:
# 在第n维增加 x.unsqueeze(n) # 减少一维 x.squeeze(n) # 将 tensor 中所有的一维全部都去掉 x.squeeze() # 重新排列维度 x.permute(a, b, c) #交换tensor中的两个维度 x.transpose(a, b) # view的操作。(reshape进阶版) x.view(-1, b) # -1表示任意大小 x.view(a, b) x.view_as(others) # 这个挺方便的 # 就是将x reshape成 others的形状Tips:
pytorch中大多数的操作都支持 inplace 操作,也就是可以直接对 tensor 进行操作而不需要另外开辟内存空间,方式非常简单,一般都是在操作的符号后面加_inplace参数的理解:
修改一个对象时:
inplace=True:不创建新的对象,直接对原始对象进行修改;
inplace=False:对数据进行修改,创建并返回新的对象承载其修改结果
2. Variable及自动求导机制
导入:
from torch.autograd import Variable
将Tensor变成Variable
x = Variable(x_tensor, requires_grad=True)
每个 Variabel都有三个属性,Variable 中的 tensor本身.data,对应 tensor 的梯度.grad以及这个 Variable 是通过什么方式得到的.grad_fn
求梯度操作:
x_tensor = torch.randn(10, 5)
y_tensor = torch.randn(10, 5)
# 将 tensor 变成 Variable
x = Variable(x_tensor, requires_grad=True) # 默认 Variable 是不需要求梯度的,所以我们用这个方式申明需要对其进行求梯度
y = Variable(y_tensor, requires_grad=True)
z = torch.sum(x + y)
print(z.data)
print(z.grad_fn)
# 求 x 和 y 的梯度
z.backward()
print(x.grad)
print(y.grad)
通过调用 backward 我们可以进行一次自动求导,如果我们再调用一次 backward,会发现程序报错,没有办法再做一次。这是因为 PyTorch 默认做完一次自动求导之后,计算图就被丢弃了,所以两次自动求导需要手动设置一个东西
x = Variable(torch.FloatTensor([3]), *requires_grad*=True)
y = x * 2 + x ** 2 + 3
y.backward(*retain_graph*=True)
设置 retain_graph 为 True 来保留计算图
**Tips: **
PyTorch0.4中,.data 仍保留,但建议使用 .detach(), 区别在于 .data 返回和 x 的相同数据 tensor, 但不会加入到x的计算历史里,且require s_grad = False, 这样有些时候是不安全的, 因为 x.data 不能被 autograd 追踪求微分 。 .detach() 返回相同数据的 tensor ,且 requires_grad=False ,但能通过 in-place 操作报告给 autograd 在进行反向传播的时候.
举例:
tensor.data
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.data
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的数值被c.zero_()修改
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 反向传播
>>> a.grad # 这个结果很严重的错误,因为out已经改变了
tensor([ 0., 0., 0.])
tensor.detach()
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.detach()
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的值被c.zero_()修改 !!
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 需要原来out得值,但是已经被c.zero_()覆盖了,结果报错
RuntimeError: one of the variables needed for gradient
computation has been modified by an
此Tips从梦家的博文摘抄而来
3.构建网络
pytorch中有很多内置数学函数
import torch.nn.functional as F
来导入,例如:
F.sigmoid()
torch.clamp(input, min, max, out=None) → Tensor
来限制输入的上限和下限
手动更新参数其实挺麻烦的,可以用
torch.optim和数据类型nn.Parameter来操作
不过nn.Parameter 是默认要求梯度的
用nn.optim.SGD可以用梯度下降法来更新参数
例:
# 使用 torch.optim 更新参数
from torch import nn
w = nn.Parameter(torch.randn(2, 1))
b = nn.Parameter(torch.zeros(1))
def logistic_regression(x):
return F.sigmoid(torch.mm(x, w) + b)
optimizer = torch.optim.SGD([w, b], lr=1.)
# 进行 1000 次更新
import time
start = time.time()
for e in range(1000):
# 前向传播
y_pred = logistic_regression(x_data)
loss = binary_loss(y_pred, y_data) # 计算 loss
# 反向传播
optimizer.zero_grad() # 使用优化器将梯度归 0
loss.backward()
optimizer.step() # 使用优化器来更新参数
# 计算正确率
mask = y_pred.ge(0.5).float()
acc = (mask == y_data).sum().data[0] / y_data.shape[0]
if (e + 1) % 200 == 0:
print('epoch: {}, Loss: {:.5f}, Acc: {:.5f}'.format(e+1, loss.data[0], acc))
during = time.time() - start
print()
print('During Time: {:.3f} s'.format(during))
有几个关键操作:
optimizer.zero_grad()
归零梯度。相当于w.grad.data.zero_()
optimizer.step()
用优化器更新参数。相当于https://blog.csdn.net/lens___/article/details/83960810
w.data = w.data - 0.1 * w.grad.data
再举个栗子:
for e in range(100):
out = logistic_regression(Variable(x))
loss = criterion(out, Variable(y))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 20 == 0:
print('epoch: {}, loss: {}'.format(e+1, loss.data[0]))
上面的都是线性网络的例子,下面举一个神经网络的例子。用到nn.Parameter
# 定义两层神经网络的参数
w1 = nn.Parameter(torch.randn(2, 4) * 0.01) # 隐藏层神经元个数 2
b1 = nn.Parameter(torch.zeros(4))
w2 = nn.Parameter(torch.randn(4, 1) * 0.01)
b2 = nn.Parameter(torch.zeros(1))
# 定义模型
def two_network(x):
x1 = torch.mm(x, w1) + b1
x1 = F.tanh(x1) # 使用 PyTorch 自带的 tanh 激活函数
x2 = torch.mm(x1, w2) + b2
return x2
optimizer = torch.optim.SGD([w1, w2, b1, b2], 1.)
criterion = nn.BCEWithLogitsLoss()
# 我们训练 10000 次
for e in range(10000):
out = two_network(Variable(x))
loss = criterion(out, Variable(y))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 1000 == 0:
print('epoch: {}, loss: {}'.format(e+1, loss.data[0]))
记录一个决策边界绘制代码
def plot_decision_boundary(model, x, y):
# Set min and max values and give it some padding
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:, 0], x[:, 1], c=y.reshape(-1), s=40, cmap=plt.cm.Spectral)
np.meshgrid的作用:
知乎专栏
contour和contourf都是画三维等高线图的,不同点在于contour() 是绘制轮廓线,contourf()会填充轮廓.。详细说明:
CSDN
4. Sequential 和 Module
Sequential
# Sequential基本操作
seq_net = nn.Sequential(
nn.Linear(2, 4), # PyTorch 中的线性层,wx + b
nn.Tanh(),
nn.Linear(4, 1)
)
序列模块可以通过索引访问每一层
sq_net[0] 第一层
可以得到出第一层的权重
w0 = seq_net[0].weight
通过parameters可以取得模型的参数
param = seq_net.parameters()
模型的保存
1.
将参数和模型保存在一起
torch.save(seq_net, save_seq_net.pth')
参数一个是模型,一个是路径
读取保存的模型:
seq_net1 = torch.load('save_seq_net.pth')
2.
保存模型参数
torch.save(seq_net.state_dict(), save_seq_net_params.pth')
通过上面的方式,我们保存了模型的参数,如果要重新读入模型的参数,首先我们需要重新定义一次模型,接着重新读入参数
读入参数操作:
seq_net2.load_state_dict(toech.load('save_seq_net_params.pth))
Module
Module模板:
class 网络名字(nn.Module):
def __init__(self, 一些定义的参数):
super(网络名字, self).__init__()
self.layer1 = nn.Linear(num_input, num_hidden)
self.layer2 = nn.Sequential(...)
...
定义需要用的网络层
def forward(self, x): # 定义前向传播
x1 = self.layer1(x)
x2 = self.layer2(x)
x = x1 + x2
...
return x
注意的是,Module 里面也可以使用 Sequential,同时 Module 非常灵活,具体体现在 forward 中,如何复杂的操作都能直观的在 forward 里面执行。(想要亲身体会请看一些论文源码),里面可以用各种数据处理.
建议自己实现一个resnet网络。可以很快熟悉基本操作,以后论文基本上都是用这个网络
Module中,访问模型的某一层可以直接通过名字来访问:
l1 = mo_net.lay1(这是基本的操作吧)
访问权重:l1.weight
定义完网络,就可以for in 来训练网络了。
直接:
out = mo_net(Variable(x))
就可以得到output
保存模型一样,还是用
.state_dict()
5. 数据的读取操作(MNIST为例)
pytorch是内置了MNIST的
from torchvision.datasets import mnist
然后就可以通过内置函数来下载mnist数据集了
train_set = mnist.MNIST('./data', *train*=True, *download*=True)
test_set = mnist.MNIST('./data', *train*=False, *download*=True)
注:数据结构是这样的:
a_data, a_label = train_set[i]
a_data指的是图片矩阵,a_label则是对应的标签
读入的数据的PIL库中的格式
最好转换为numpy array格式来:
a_data = np.array(a_data, dtype='float32')
接下来就对a_data进行处理,由于要用神经元,所以得拉平,用reshape操作。当然还要正则化等数据处理。然后就可以正常进行了。用softmax函数作为评价函数即可。用BCELoss(交叉熵损失)。
注:用 _, pred = out.max(1)来记录准确度。0维是batch维,共64, 1维则是通过网络预测出来的评分结果维,有10个,我们取最大评分的pred即可。最后通过
.max(dim)方法中,若是2维函数,则是0代表每列的最大值,1代表每行的最大值
训练的时候,要用DataLoader定义一个数据迭代器
注意!这里可以进行很多操作!比如说数据的处理,图片的分割等等!
from torch.utils.data import DataLoader
# 使用 pytorch 自带的 DataLoader 定义一个数据迭代器
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
使用这样的数据迭代器是非常有必要的,如果数据量太大,就无法一次将他们全部读入内存,所以需要使用 python 迭代器,每次生成一个批次的数据
上面只是简单举一个例子。实际应用的时候最好单独写一个文件.方便修改
然后用
a, a_label = next(iter(train_data))
注意:
net.train()是进入训练模式(train集)
net.eval()是进入预测模式(test集)
一般来说打印要打印:
epoches, Train_Loss, Train_Acc, Eval_Loss, Eval_Acc。方便比较
并且,在训练和测试的过程中,要用losses,acces, eval_losses和 eval_acces集合来实时保存训练或者测试出来的loss和acc。然后训练完可以画出图来,方便对数据进行分析改进
6. 初始化参数操作
from torch.nn import init
Xavier初始化:
init,xavier_uniform(net[0].weight)
用Xavier初始化方法初始化网络的第一层
还有很多初始化方法。可以查阅:
简书
7. pytorch中实现一些优化器的方法
- SGD
# 手动实现
def sgd_update(parameters, lr):
for param in parameters:
param.data = param.data - lr * param.grad.data
调用内置函数:
optimzier = torch.optim.SGD(net.parameters(), learning_rate)
-
动量法
# 手动实现 def sgd_momentum(parameters, vs, lr, gamma): for param, v in zip(parameters, vs): v[:] = gamma * v + lr * param.grad.data param.data = param.data - v调用内置函数:
torch.optim.SGD(momentum=0.9)
仅仅在SGD函数中加一个动量变量就行了 -
Adagrad 自适应学习率优化算法
Adagrad 的核心想法就是,如果一个参数的梯度一直都非常大,那么其对应的学习率就变小一点,防止震荡,而一个参数的梯度一直都非常小,那么这个参数的学习率就变大一点,使得其能够更快地更新
(frac{eta}{s+epsilon})
def sgd_adagrad(parameters, sqrs, lr):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = sqr + param.grad.data ** 2
div = lr / tortorch.optim.Adagrad()ch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
调用内置函数:
torch.optim.Adagrad(net.parameters(), lr=1e-2)
-
RMSProp
Adagrad 算法有一个问题,就是学习率分母上的变量 s 不断被累加增大,最后会导致学习率除以一个比较大的数之后变得非常小,这不利于我们找到最后的最优解,所以 RMSProp 的提出就是为了解决这个问题。用移动平均来计算这个s
[s_i = alpha s_{i-1} + (1 - alpha) g^2 ]
g为当前求出的参数梯度,(alpha)为移动平均的系数
# 手动实现
def rmsprop(parameters, sqrs, lr, alpha):
eps = 1e-10
for param, sqr in zip(parameters, sqrs):
sqr[:] = alpha * sqr + (1 - alpha) * param.grad.data ** 2
div = lr / torch.sqrt(sqr + eps) * param.grad.data
param.data = param.data - div
用内置函数:
torch.optim.RMSprop()
-
Adadelta
Adadelta 跟 RMSProp 一样,先使用移动平均来计算 s[s = ho s + (1 - ho) g^2 ]这里 ( ho) 和 RMSProp 中的 (alpha) 都是移动平均系数,g 是参数的梯度,然后我们会计算需要更新的参数的变化量
[g' = frac{sqrt{Delta heta + epsilon}}{sqrt{s + epsilon}} g ](Delta heta) 初始为 0 张量,每一步做如下的指数加权移动平均更新
[Delta heta = ho Delta heta + (1 - ho) g'^2 ]最后参数更新如下
[ heta = heta - g' ]
# 手动实现(反正我没怎么看这部分)
def adadelta(parameters, sqrs, deltas, rho):
eps = 1e-6
for param, sqr, delta in zip(parameters, sqrs, deltas):
sqr[:] = rho * sqr + (1 - rho) * param.grad.data ** 2
cur_delta = torch.sqrt(delta + eps) / torch.sqrt(sqr + eps) * param.grad.data
delta[:] = rho * delta + (1 - rho) * cur_delta ** 2
param.data = param.data - cur_delta
调用函数:
torch.optim.Adadelta(net.parameters(), rho= 0.9)
-
Adam
现在一般都用adam# 手动实现 def adam(parameters, vs, sqrs, lr, t, beta1=0.9, beta2=0.999): eps = 1e-8 for param, v, sqr in zip(parameters, vs, sqrs): v[:] = beta1 * v + (1 - beta1) * param.grad.data sqr[:] = beta2 * sqr + (1 - beta2) * param.grad.data ** 2 v_hat = v / (1 - beta1 ** t) s_hat = sqr / (1 - beta2 ** t) param.data = param.data - lr * v_hat / torch.sqrt(s_hat + eps)调用函数:
torch.optim.Adam(net.parameters(), lr=1e-3)
8. 卷积神经网络的构建
-
卷积在pytorch中有两种方式
torch.nn.Conv2d()
torch.nn.functional.conv2d()
两个本质是一样的,输入的要求也是一样的
输入的是一个torch.autograd.Variable()类型,大小为(batch, channel, H, W)使用
nn.Conv2d()相当于直接定义了一层卷积网络结构,而使用torch.nn.functional.conv2d()相当于定义了一个卷积的操作,所以使用后者需要再额外去定义一个 weight,而且这个 weight 也必须是一个 Variable,而使用nn.Conv2d()则会帮我们默认定义一个随机初始化的 weight,如果我们需要修改,那么取出其中的值对其修改,如果不想修改,那么可以直接使用这个默认初始化的值,非常方便实际使用中我们基本都使用 nn.Conv2d() 这种形式
-
池化操作也有两种方法:
nn.MaxPool2d()
torch.nn.functional.max_pool2d() -
批标准化 Batch Normalization
首先肯定要对数据进行数据预处理。
现在一般是进行中心化和标准化。PCA和白化很少用了。
这里要注意,中心化和标准化的时候,使用的方差和均值统统都是用训练集的数据。包括预处理测试集和验证集数据的时候。批标准化,简而言之,就是对于每一层网络的输出,对其做一个归一化,使其服从标准的正态分布,这样后一层网络的输入也是一个标准的正态分布,所以能够比较好的进行训练,加快收敛速度。
pytorch 当然也为我们内置了批标准化的函数,一维和二维分别是
torch.nn.BatchNorm1d() torch.nn.BatchNorm2d()
pytorch 不仅将 γγ 和 ββ 作为训练的参数,也将 moving_mean 和 moving_var 也作为参数进行训练
9. 数据增强操作
常用的数据增强方法如下:
1.对图片进行一定比例缩放
2.对图片进行随机位置的截取
3.对图片进行随机的水平和竖直翻转
4.对图片进行随机角度的旋转
5.对图片进行亮度、对比度和颜色的随机变化
这些方法一般是用torchvision中的transforms来进行操作,还有PIL库中的image,以及sys库用来操作文件
import sys
from PIL import image
from torchvision import transforms as tfs
# 读入一张图片
im = Image.open('./cat.png')
比例缩放:
new_im = tfs.Resize((100, 200))(image)
随机位置截取:
在 torchvision 中主要有下面两种方式
一个是 torchvision.transforms.RandomCrop()
传入的参数就是截取出的图片的长和宽,对图片在随机位置进行截取;
第二个是 torchvision.transforms.CenterCrop()
同样传入截取初的图片的大小作为参数,会在图片的中心进行截取
随机水平翻转(镜像)
torchvision.transforms.RandomHorizontalFlip()
随机竖直翻转: torchvision.transforms.RandomVerticalFlip()
随机角度旋转:
torchvision.transforms.RandomRotation(a)
a是角度
亮度,对比度和颜色的变化
torchvision.transforms.ColorJitter(brightness=1, contrast=1, hue=0.5, (R,G,B))
第一个参数就是亮度的比例,第二个是对比度,第三个是饱和度,第四个是颜色
brightness: 随机从 0 ~ 2 之间亮度变化,1 表示原图
contrast: 随机从 0 ~ 2 之间对比度变化,1 表示原图
hue: 随机从 -0.5 ~ 0.5 之间对颜色变化
上面这么多图像增强方法,其实是可以联合起来用的。比如先做随机翻转,然后随机截取,再做对比度增强等等,torchvision 里面有个非常方便的函数能够将这些变化合起来,就是 torchvision.transforms.Compose()
# 举例im_aug = tfs.Compose([
tfs.Resize(120),
tfs.RandomHorizontalFlip(),
tfs.RandomCrop(96),
tfs.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5)
])
10 正则化操作与学习率衰减
regularzation现在很少用dropout, 而是用正则化来惩罚权重。
torch.optim.SGD(net.parameters(), lr=0.1, weight_decay=1e-4)
weight_decay参数就是权重衰减。 意思就是正则化。这是L2正则。
注意正则项的系数的大小非常重要,如果太大,会极大的抑制参数的更新,导致欠拟合,如果太小,那么正则项这个部分基本没有贡献,所以选择一个合适的权重衰减系数非常重要.一般尝试会用1e-4或者1e-3来进行。
在 pytorch 中学习率衰减非常方便,使用 torch.optim.lr_scheduler
或者用参数组的方式实现:
参数组:就是我们可以将模型的参数分成几个组,每个组定义一个学习率。这个参数组是一个字典,里面有很多属性,比如学习率,权重衰减等等
例:optimizer.param_groups[0]['lr']
optimizer.param_groups[0]['weight_decay']
def set_learning_rate(optimizer, lr):
for param_group in optimizer.param_groups:
param_group['lr'] = lr
...
# 训练途中修改学习率
if epoch == 20:
set_learning_rate(optimizer, 0.01) # 20 次修改学习率为 0.01
11. 主流网络实现(略)
数据集cifar10
torchvision.datasets.CIFAR10
此部分最好自己手动实现各个网络
更能熟悉
-
VGGNet:
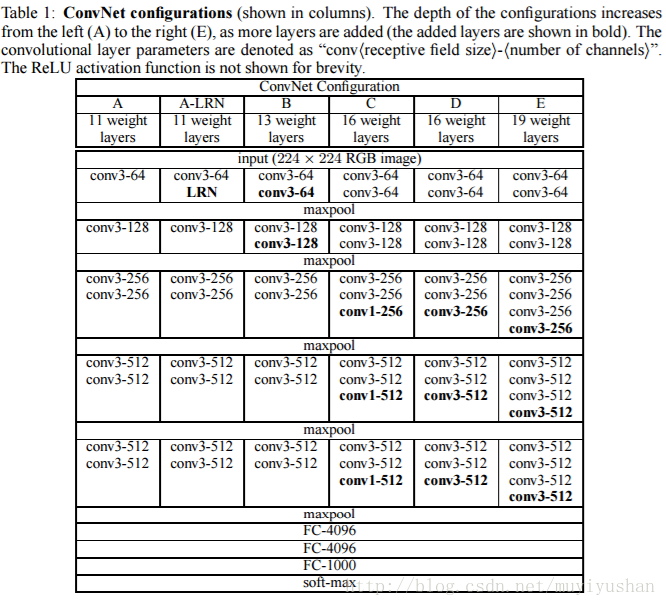
-
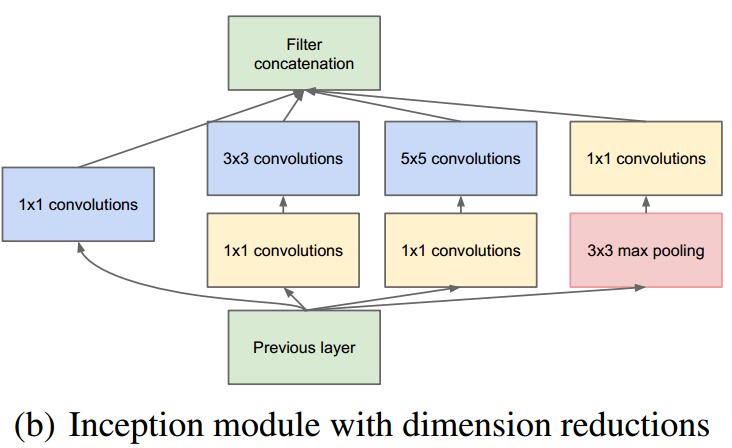
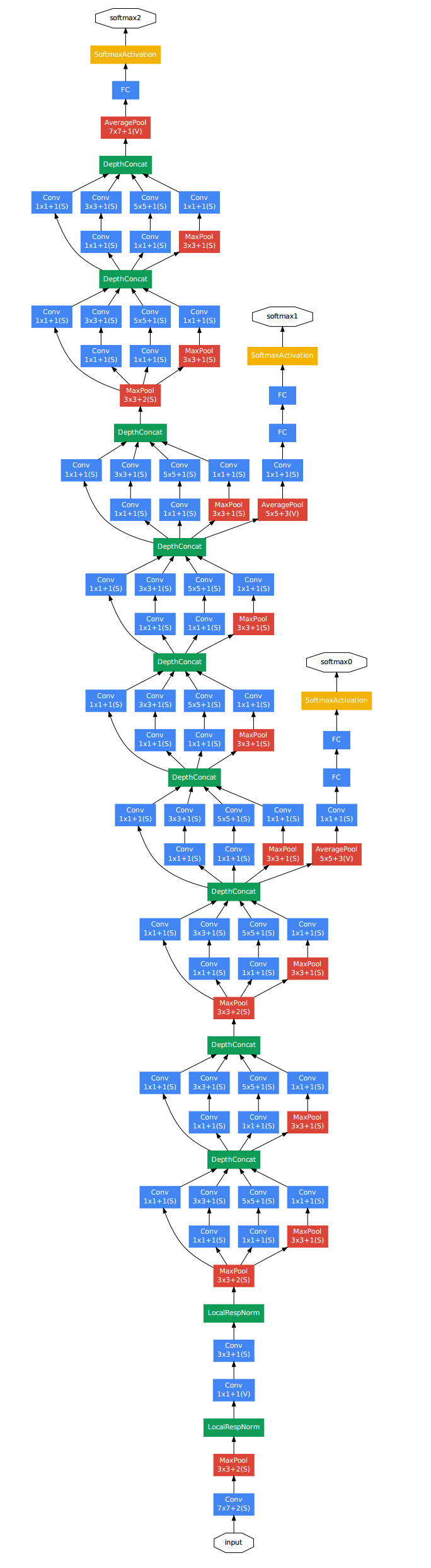
GoogleNet
GoogleNet的改进:
v1:最早的版本
v2:加入 batch normalization 加快训练v3:对 inception 模块做了调整
v4:基于 ResNet 加入了 残差连接 -
ResNet
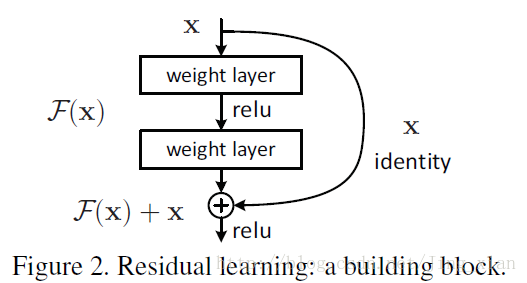

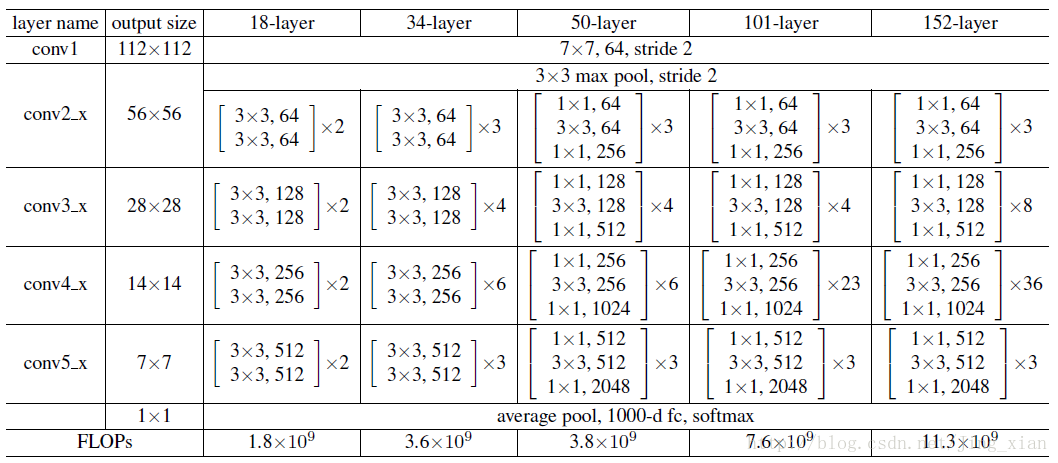
-
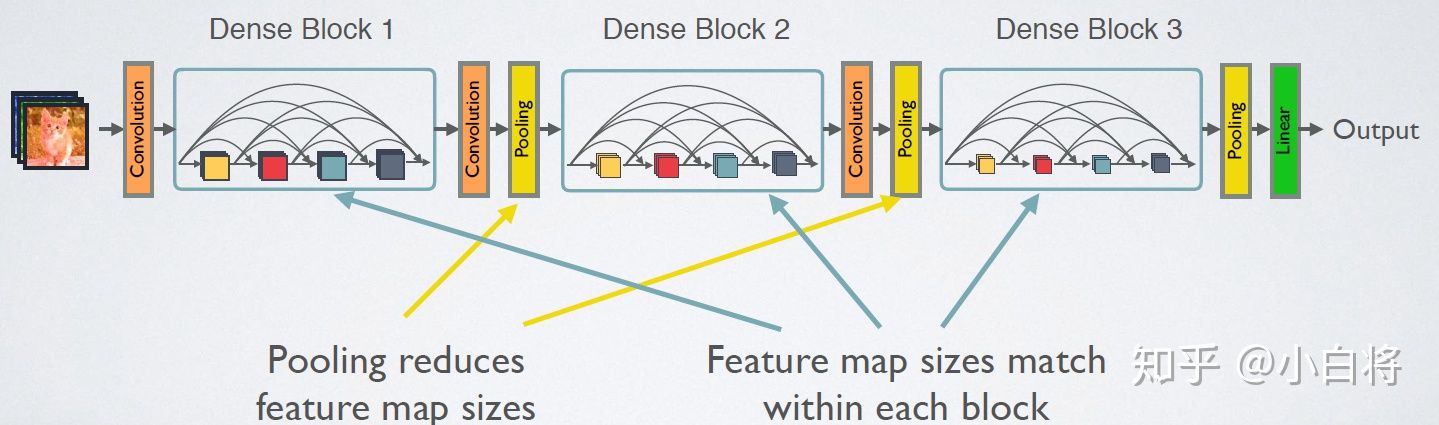
DenseNet

短路链接机制:
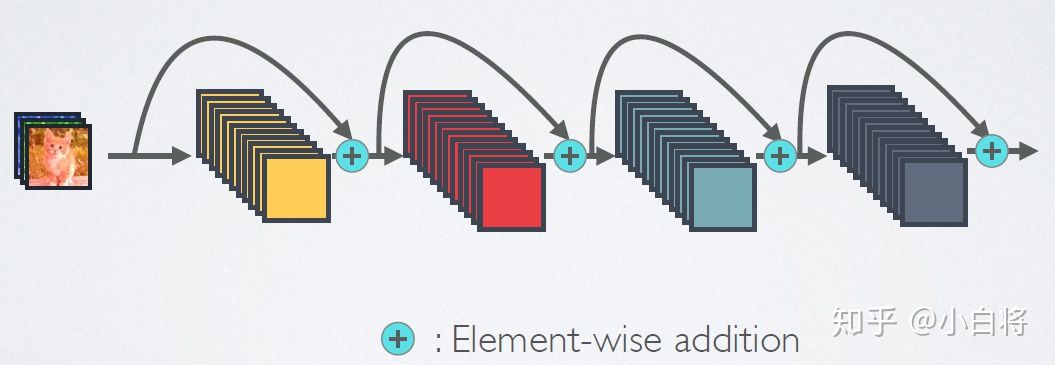
密集链接机制:
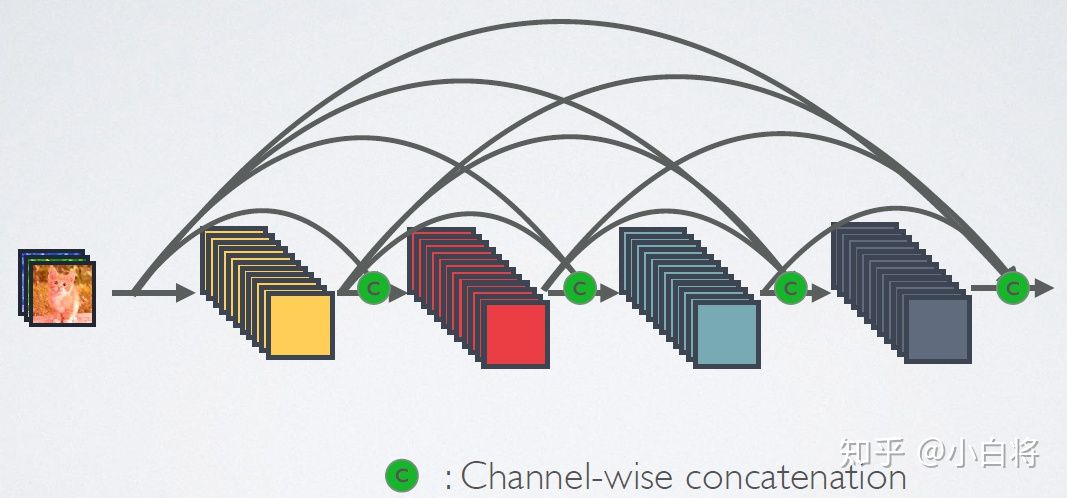
前向过程:

网络结构: