一、概述
1、介绍
为什么出现集合?
答:面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,对对象进行存储,集合就是存储对象最常用的一种方式。
数组和集合类同是容器,有何不同?
答:数组虽然也可以存储对象,但长度是固定的,集合长度是可变的。数组中可以存储基本数据类型,集合中只能存储对象(引用类型,基本类型的包装类型)。
为什么会出现这么多的容器呢?
答:因为每一个容器对数据的存储方式都有不同。这个存储方式称之为:数据结构。
什么是迭代器呢?
答:其实就是集合的取出元素的方式。
2、集合框架
简图:
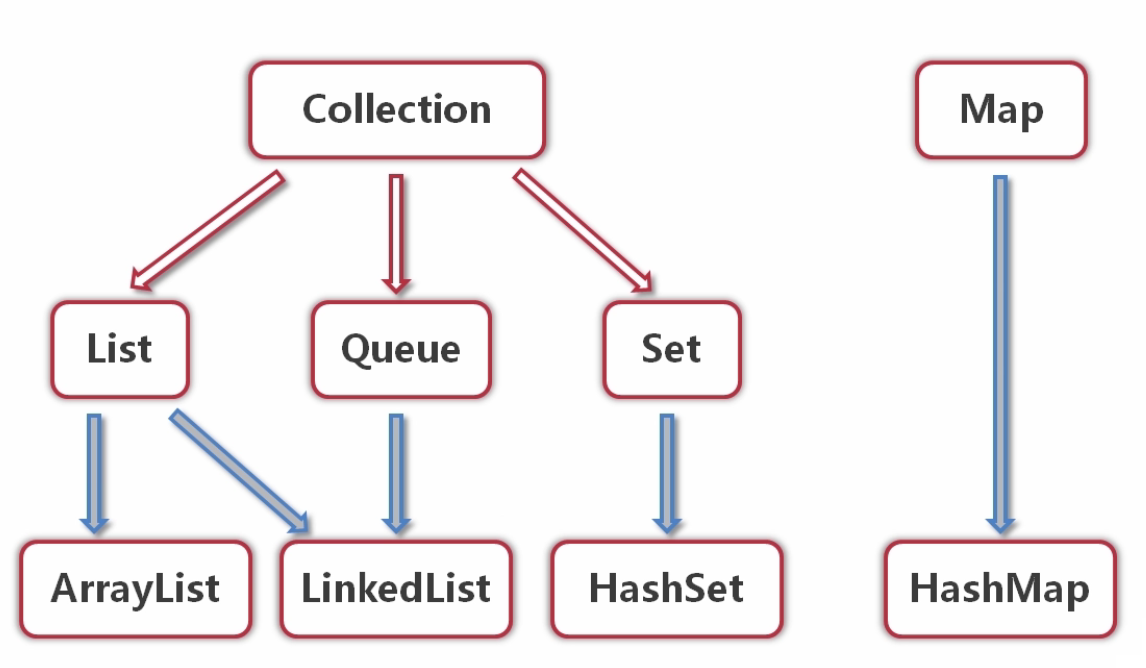
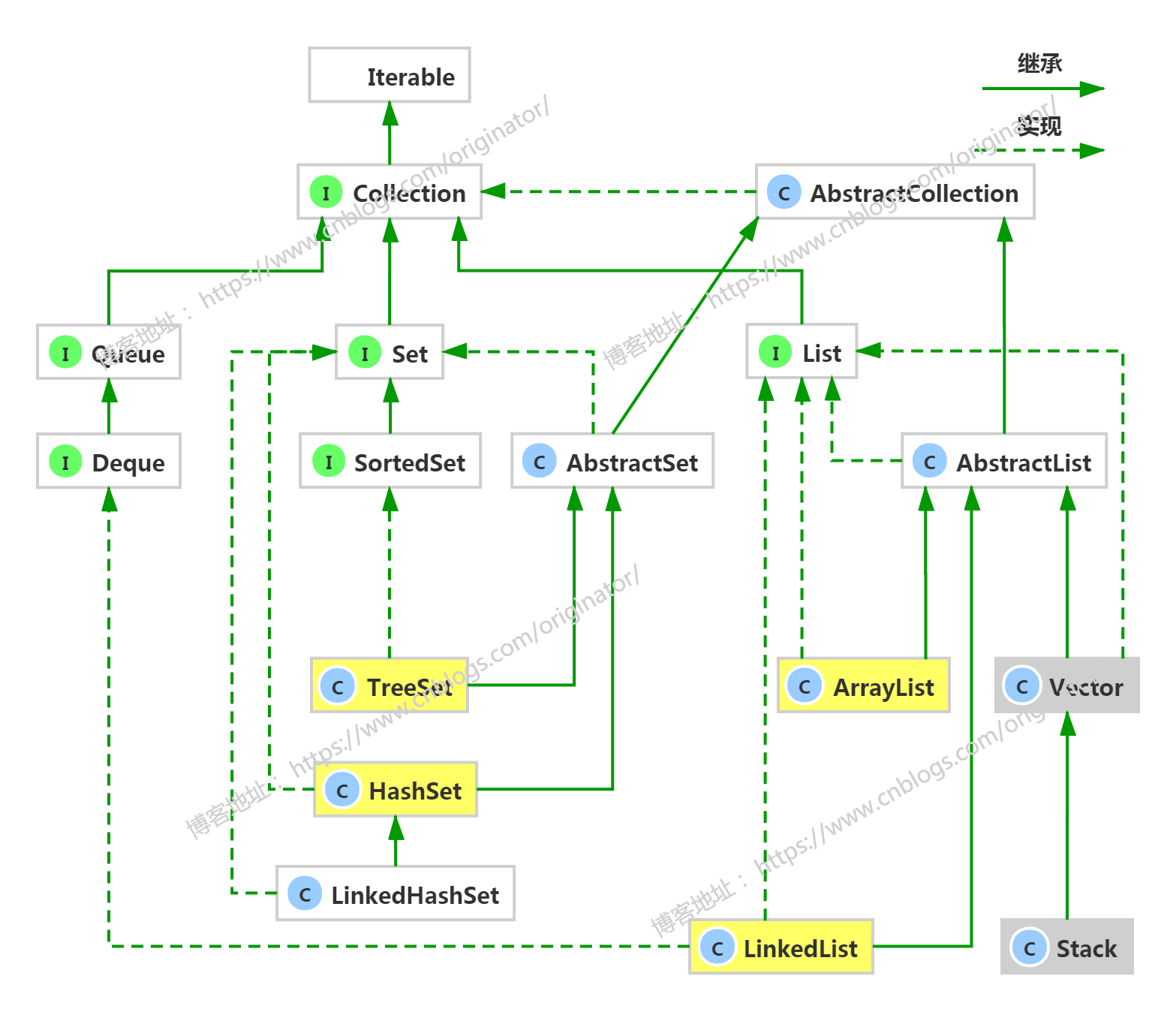
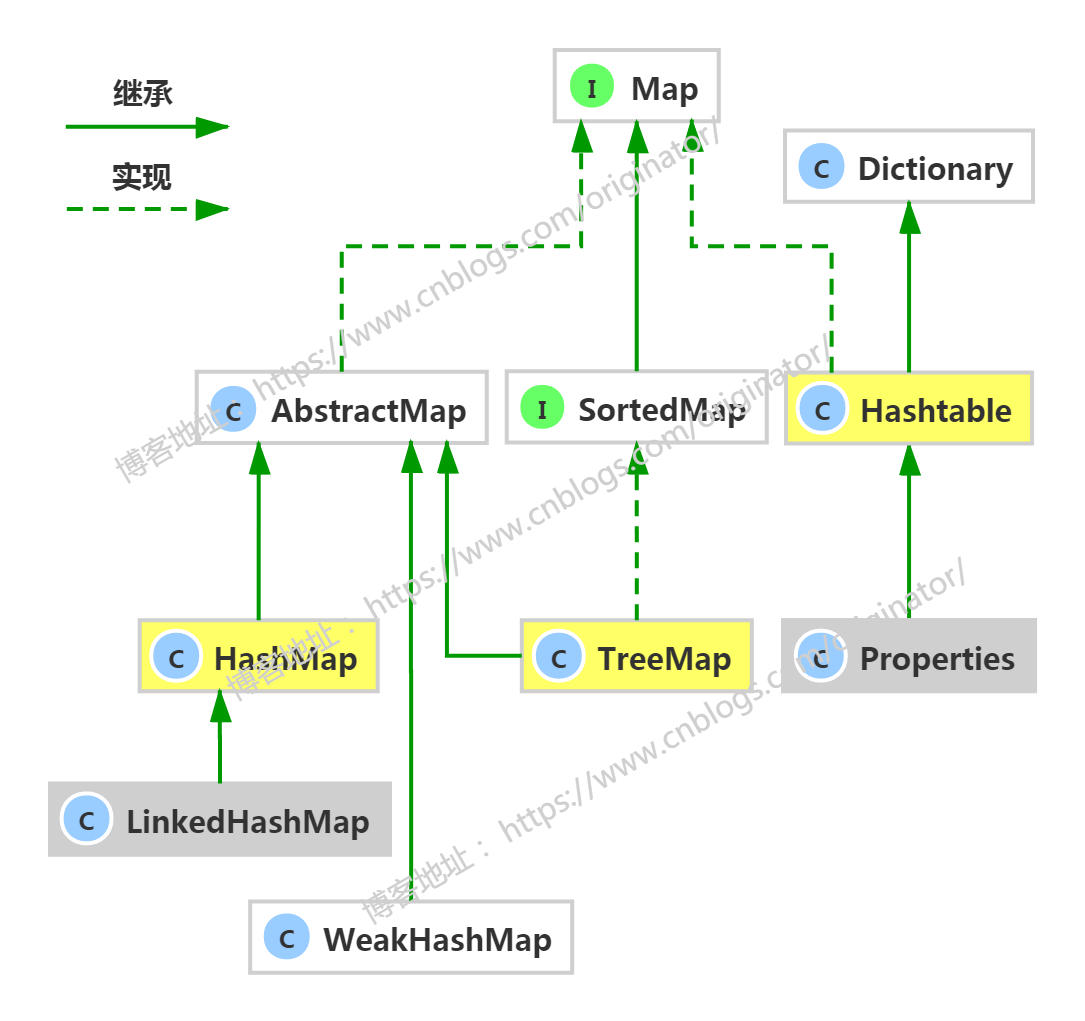
Map:
二、Collection<E>(jdk1.2)
集合中存储的都是对象的引用(地址)。
1、常用方法
add(Object obj):添加。
addAll(Collection coll):添加。
int size():获取有效元素的个数。
void clear():清空集合。
boolean isEmpty():是否是空集合。
boolean contains(Object obj):是否包含某个元素,通过元素的equals方法来判断是否是同一个对象。
boolean containsAll(Collection c):也是调用元素的equals方法来比较的。两个集合的元素挨个比较。boolean remove(Object obj) :删除,通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素。
boolean removeAll(Collection coll):删除,取当前集合的差集。
boolean retainAll(Collection c):取交集,把交集的结果存在当前集合中,不影响c。
boolean equals(Object obj):集合是否相等。
Object[] toArray():转成对象数组。
hashCode():获取集合对象的哈希值。
iterator():返回迭代器对象,用于集合遍历。
代码示例:基本方法
1 public class Main { 2 public static void main(String[] args) { 3 Collection<Object> coll = new ArrayList<>(); 4 5 coll.add("AA"); 6 coll.add("BB"); 7 coll.add(123); // 自动装箱 8 coll.add(new Date()); 9 10 System.out.println(coll.size()); // 4 11 12 Collection<Object> coll1 = new ArrayList<>(); 13 coll1.add(456); 14 coll1.add("CC"); 15 coll1.add(123); 16 17 coll.addAll(coll1); 18 System.out.println(coll); 19 20 coll.clear(); // 清空集合元素 21 22 System.out.println(coll.isEmpty()); // true 23 } 24 }
代码示例:初始化类
1 // 预先定义的实体类 2 public class Person { 3 4 private String name; 5 private int age; 6 7 // 无参构造器 8 // 有参构造器 9 // getter & setter 10 // toString() 11 12 @Override 13 public boolean equals(Object o) { 14 System.out.println("Person equals()...."); 15 if (this == o) return true; 16 if (o == null || getClass() != o.getClass()) return false; 17 Person person = (Person) o; 18 return age == person.age && 19 Objects.equals(name, person.name); 20 } 21 22 @Override 23 public int hashCode() { 24 return Objects.hash(name, age); 25 } 26 } 27 28 // 初始化的集合.下面的代码示例,集合都是这个. 29 public Collection<Object> init() { 30 Collection<Object> coll = new ArrayList<>(); 31 32 coll.add(123); 33 coll.add(456); 34 coll.add(new Person("Jerry", 20)); 35 coll.add("Tom"); 36 coll.add(false); 37 38 return coll; 39 }
1 public void method1() { 2 System.out.println(coll.hashCode()); 3 4 // 判断当前集合中是否包含obj 5 // 想要按 Person 对象的属性来比较,需要复写 equals(Object o) 6 // false --> true 7 System.out.println(coll.contains(new Person("Jerry", 20))); 8 9 // 当且仅当形参中的所有元素都存在于当前集合中.true 10 // true 11 System.out.println(coll.containsAll(Arrays.asList(123, 456))); 12 13 coll.remove(1234); 14 coll.remove(new Person("Jerry", 20)); 15 // 差集:A - B 16 coll.removeAll(Arrays.asList(123, 4567)); 17 18 System.out.println(coll); 19 20 // 两个集合完全相同,包括顺序相同(这个又具体子类决定) 21 // System.out.println(coll.equals(coll1)); 22 23 // 交集 24 coll.retainAll(Arrays.asList(123, 666)); 25 System.out.println(coll); 26 } 27 28 // 结果 29 -1200490100 30 Person equals().... 31 Person equals().... 32 Person equals().... 33 true 34 true 35 Person equals().... 36 Person equals().... 37 Person equals().... 38 [456, Tom, false] 39 []
结果分析:
①判定一个集合中是否包含某个对象,contains(Object o)方法,会调用equals(Object o)去比较,所以需要复写equals(Object o)方法。
②对象Person是第3个被加入到集合中的,比较的时候需要一个一个比较,所以equals()方法被调用了3次。
③remove(Object o)时同样equals()方法被调用了3次。
代码示例:集合 <--> 数组
1 public void method2() { 2 // 集合 --> 数组 3 final Object[] objects = coll.toArray(); 4 final Object[] array = coll.toArray(new Object[0]); 5 6 // 数组 --> 集合 7 final List<String> strings = Arrays.asList("A", "B", "C"); 8 final List<Integer> integers = Arrays.asList(123, 456); 9 }
2、Iterator<E>(迭代器)
GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。类似于"公交车上的售票员"、"火车上的乘务员"、"空姐"。
一种集合的取出元素的方式。定义在集合的内部,用于直接访问集合内 部的元素,是一个内部类。集合对象每次调用iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。Iterator主要用于遍历Collection,不包括map。
用foreach遍历Collection,底层还是使用的迭代器。迭代器原理:
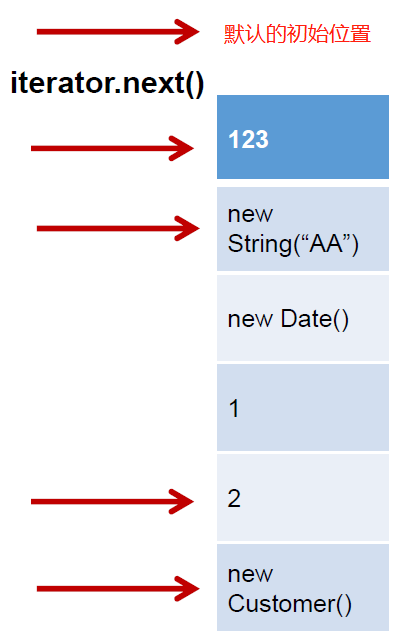
JDK8源码:

代码示例:迭代器的使用
1 // 注意:这里是迭代器里的remove,不是集合里面的。 2 public void method3() { 3 Iterator<Object> iterator = coll.iterator(); 4 while (iterator.hasNext()) { 5 // next():①指针下移 ②将下移以后集合位置上的元素返回 6 System.out.println(iterator.next()); 7 } 8 9 // 返回一个全新的迭代器 10 iterator = coll.iterator(); 11 while (iterator.hasNext()) { 12 // iterator.remove(); 报错IllegalStateException 13 final Object next = iterator.next(); 14 15 if ("Tom".equals(next)) { 16 iterator.remove(); 17 // iterator.remove(); 报错IllegalStateException 18 } 19 } 20 }
3、List<E>、Queue<E>、Set<E>(重点)
List<E>元素是有序的,可重复,因为该集合体系有索引。实现类:
ArrayList:底层使用的数组数据结构。特点:查询速度很快,但是增删稍慢(会移动后面的元素)。初始长度10,50%延长。线程不同步的。jdk1.2
LinkedList:底层使用的链表数据结构。特点:增删速度很快,查询稍慢。线程不同步的。
Vector:底层使用的数组数据结构。初始长度10,100%延长。线程同步的。后被ArrayList替代了。jdk1.0
Queue<E>有序的,可重复。实现类:
Deque<E>(接口):
LinkedList:底层使用的链表数据结构。特点:增删速度很快,查询稍慢。线程不同步的。
Set<E>元素是无序的,不重复。没有索引。实现类:
HashSet:底层使用的HashMap(数组+链表)数据结构。无序的,不可重复,线程不同步。可以存储null值。
TreeSet:底层使用的TreeMap(排序二叉树,红黑树)数据结构。可以对set集合中的元素按指定属性进行排序。有序的。查询速度比List快。
三、List<E>
1、ArrayList<E>
代码示例:迭代器的使用
1 // 其他常用方法不演示 2 public class Main { 3 public static void main(String[] args) { 4 List<String> list = new ArrayList<>(); 5 list.add("A"); 6 list.add("B"); 7 list.add("C"); 8 list.add("D"); 9 10 final Iterator<String> iterator = list.iterator(); 11 while (iterator.hasNext()) { 12 System.out.print(iterator.next()); 13 } 14 } 15 } 16 17 // 结果 18 // A B C D
2、Vector<E>
枚举就是Vector特有的取出方式,和迭代器很像,其实是一样的,由于名称过长,后被迭代器取代了。
1 public static void main(String[] args) { 2 Vector<String> vector = new Vector<>(); 3 4 vector.add("A"); 5 vector.add("B"); 6 7 // 返回此向量的组件的枚举. 8 final Enumeration<String> elements = vector.elements(); 9 10 while (elements.hasMoreElements()) { 11 System.out.println(elements.nextElement()); 12 } 13 } 14 15 // 结果 16 // A B
3、Stack<E>(栈)
1 // 先进后出 2 public class Main { 3 public static void main(String[] args) { 4 Stack<String> stack = new Stack<>(); 5 6 // 压栈 7 stack.push("A"); 8 stack.push("B"); 9 stack.push("C"); 10 11 while (!stack.empty()) { 12 // 从栈顶弹出一个.会删除元素 13 System.out.println(stack.pop()); 14 } 15 16 // 从栈顶弹出一个.不会删除元素 17 // stack.peek(); 18 } 19 } 20 21 // 结果 22 C B A
四、Queue<E>
1、Queue<E>(队列)
1 // 先进先出 2 public class Main { 3 public static void main(String[] args) { 4 Queue<Integer> queue = new LinkedList<>(); 5 6 // 添加.入队 7 queue.offer(1); 8 queue.offer(10); 9 queue.offer(5); 10 queue.offer(9); 11 System.out.println(queue); 12 13 // 出队 14 final Integer poll = queue.poll(); 15 System.out.println(poll); 16 System.out.println(queue); 17 18 // 获取.队头 19 final Integer peek = queue.peek(); 20 System.out.println(peek); 21 System.out.println(queue); 22 } 23 } 24 25 // 结果 26 [1, 10, 5, 9] 27 1 28 [10, 5, 9] 29 10 30 [10, 5, 9]
2、Deque<E>(双端队列)
3、LinkedList<E>(双向链表)
对于频繁的插入或删除元素的操作,建议使用LinkedList类,效率较高。
特有方法
addFirst():在第一个位置添加元素。
addLast()
getFirst():获取第一个元素,但不删除元素。若没有,出现异常。
getLast()
removeFirst():获取元素,但是删除元素。若没有,出现异常。
removeLast()在jdk1.6以后出现了替代方法。
offerFirst():在第一个位置添加元素。
offerLast()
peekFirst():获取元素,但不删除元素。若没有,返回null。
peekLast()
pollFirst():获取元素,但是删除元素。若没有,返回null。
pollLast()
五、Set<E>
1、介绍
Set<E>元素是不重复。没有索引。实现类:
HashSet:底层使用的HashMap(数组+链表)数据结构。无序的,不可重复,线程不安全。可以存储null值。
LinkedHashSet:底层使用的 LinkedHashMap。无序的,不可重复。
TreeSet:底层使用的TreeMap(排序二叉树,红黑树)数据结构。可以对set集合中的元素按指定属性进行排序。有序的。查询速度比List快。
以HashSet为例理解无序、不重复:
无序的:不等于随机性(并不是说打印的顺序没有按照添加的顺序),是指的存储的数据在底层数组中并非按照数组索引的顺序依次添加,而是根据数据的哈希值确定的索引位置。
不重复:调用对象equals()方法保证相同元素只添加一次。
要求:向Set(主要指:HashSet、LinkedHashSet)中添加的数据,其所在的类一定要重写hashCode()和equals()。重写的hashCode()和equals()尽可能保持一致性:相等的对象必须具有相等的散列码。
重写 hashCode() 方法的基本原则:
(1)程序运行时,同一个对象多次调用 hashCode() 方法应该返回相同的值。
(2)当两个对象的 equals() 方法比较返回 true 时,这两个对象的 hashCode() 方法的返回值也应相等。
(3)对象中用作 equals() 方法比较的 Field,都应该用来计算 hashCode 值。
重写 equals() 方法的基本原则:
当一个类有自己特有的"逻辑相等"概念,需要重写equals()的时候,总是要重写hashCode(),根据一个类的equals方法(改写后),两个截然不同的实例有可能在逻辑上是相等的,但是,根据Object.hashCode()方法,它们仅仅是两个对象。因此,违反了"相等的对象必须具有相等的散列码"。
结论:复写equals方法的时候一般都需要同时复写hashCode方法。通常参与计算hashCode的对象的属性也应该参与到equals()中进行计算。
2、HashSet<E>
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取、查找和删除性能。
底层数据结构:看JDK8的源码,HashSet底层是一个HashMap。而HashMap底层是数组+链表(7),数组+链表+红黑树(8)。
元素添加过程:由于HashSet底层就是HashMap,所以它的原理只需要了解HashMap即可。
1 // API使用 2 public class Main { 3 public static void main(String[] args) { 4 Set<String> set1 = new HashSet<>(); 5 Set<String> set2 = new HashSet<>(); 6 7 set1.add("a"); 8 set1.add("b"); 9 set1.add("c"); 10 11 set2.add("c"); 12 set2.add("d"); 13 set2.add("e"); 14 15 // 取交集 16 set1.retainAll(set2); 17 System.out.println(set1); // [c] 18 // 取并集 19 // set1.addAll(set2); 20 // System.out.println(set1); // [a, b, c, d, e] 21 // 取差集 22 // set1.removeAll(set2); 23 // System.out.println(set1); // [a, b] 24 } 25 }
3、LinkedHashSet<E>
作为HashSet的子类,LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置(依然是无序的), 但它同时使用双向链表维护元素的添加次序,这使得元素看起来是以插入顺序保存的。也可以按照添加的顺序遍历。
对于频繁的遍历操作,LinkedHashSet效率高于HashSet。LinkedHashSet插入性能略低于 HashSet。
代码示例:
1 public class Main { 2 public static void main(String[] args) { 3 Set set = new LinkedHashSet(); 4 set.add("AA"); 5 set.add(456); 6 set.add(456); 7 8 set.add(new User("刘德华", 60)); 9 10 Iterator iterator = set.iterator(); 11 while (iterator.hasNext()) { 12 System.out.println(iterator.next()); 13 } 14 } 15 } 16 17 // 结果:按照添加的顺序遍历. 18 AA 19 456 20 User{name='刘德华', age=60} 21 22 // 若Set set = new HashSet();则遍历不按照添加的顺序
底层结构:
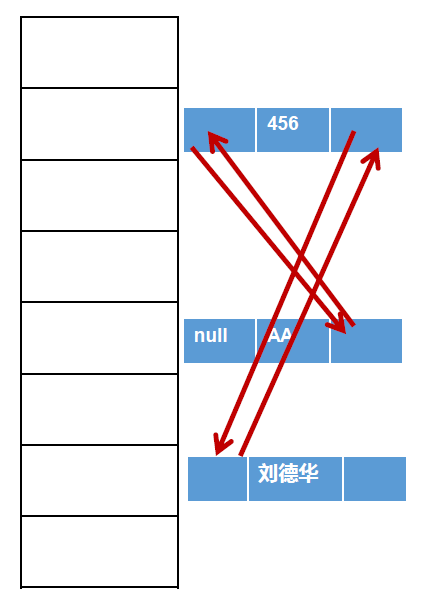
4、TreeSet<E>
底层是排序二叉树,所以①必须是相同类型的对象。②必须可排序。自然排序(实现Comparable接口)和定制排序(Comparator)。
自然排序中,判断两个对象是否相同的标准为:compareTo()返回0,不是equals()。
定制排序中,判断两个对象是否相同的标准为:compare()返回0。不是equals()。
若compareTo始终返回0,则add始终只有一个元素。因为后面的都认为与前面的相同,因此没有加入进来。判断两个对象是否相等的标准是compareTo返回值相同。
底层数据结构:看JDK8的源码,TreeSet底层是一个TreeMap。采用红黑树的存储结构。有序的。查询速度比List快。
元素添加过程:
代码示例:让User具有可比性,自然排序:Comparable
1 public class User implements Comparable<User> { 2 private String name; 3 private int age; 4 5 // 无参构造器 6 // 有参构造器 7 // getter & setter 8 // toString() 9 // 可以不复写equals、hashCode 10 11 @Override 12 public int compareTo(User user) { 13 System.out.println(this.name + "-------------" + user.getName()); 14 15 if (this.age > user.age) { 16 return 1; 17 } 18 if (this.age < user.age) { 19 return -1; 20 } 21 return 0; 22 } 23 } 24 25 // 测试类 26 public static void main(String[] args) { 27 TreeSet<User> treeSet = new TreeSet<>(); 28 29 treeSet.add(new User("java1", 30)); 30 treeSet.add(new User("java2", 20)); 31 treeSet.add(new User("java3", 31)); 32 treeSet.add(new User("java4", 60)); 33 34 final Iterator<User> iterator = treeSet.iterator(); 35 while (iterator.hasNext()) { 36 final User user = iterator.next(); 37 System.out.println(user.getName() + "---------" + user.getAge()); 38 } 39 } 40 41 // 结果 42 java1-------------java1 // 第一次 43 java2-------------java1 // 2和1比,2在左边 44 java3-------------java1 // 3和1比,3在右边 45 java4-------------java1 // 4和1比,4在右边 46 java4-------------java3 // 4和3比,4在右边 47 java2---------20 48 java1---------30 49 java3---------31 50 java4---------60
结果分析:不难理解打印结果的比较次数。

代码示例:指定比较器,定制排序:Comparator
1 // 比较器 2 public static void main(String[] args) { 3 final Comparator<User> comparator = new Comparator<User>() { 4 // 按照年龄从小到大排列 5 @Override 6 public int compare(User o1, User o2) { 7 return Integer.compare(o1.getAge(), o2.getAge()); 8 } 9 }; 10 11 TreeSet<User> treeSet = new TreeSet<>(comparator); 12 13 treeSet.add(new User("java1", 30)); 14 treeSet.add(new User("java2", 20)); 15 treeSet.add(new User("java3", 31)); 16 treeSet.add(new User("java4", 60)); 17 treeSet.add(new User("java5", 60)); 18 19 final Iterator<User> iterator = treeSet.iterator(); 20 while (iterator.hasNext()) { 21 final User user = iterator.next(); 22 System.out.println(user.getName() + "---------" + user.getAge()); 23 } 24 } 25 26 // 结果 27 java2---------20 28 java1---------30 29 java3---------31 30 java4---------60
六、Map<K,V>
1、介绍(重点)
双列数据,存储key-value对的数据。用作键的对象必须实现hashCode方法和equals方法。实现类:
HashMap:底层使用的(数组+链表7+红黑树8)数据结构。特点:可以存入null键null值。线程不同步,效率高。jdk1.2
Hashtable:底层使用的(数组+链表)数据结构。特点:不可以存入null键null值。线程同步,效率低。jdk1.0
TreeMap:底层使用的(排序二叉树,红黑树)数据结构。实现了SortedMap有序序列接口,特点:可以用于给map集合中的键按指定属性进行排序。线程不同步。
WeakHashMap:底层使用的(数组+链表)数据结构。特点:键是"弱键"。
2、HashMap<K,V>
HashMap中的Entry对象是无序排列的。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
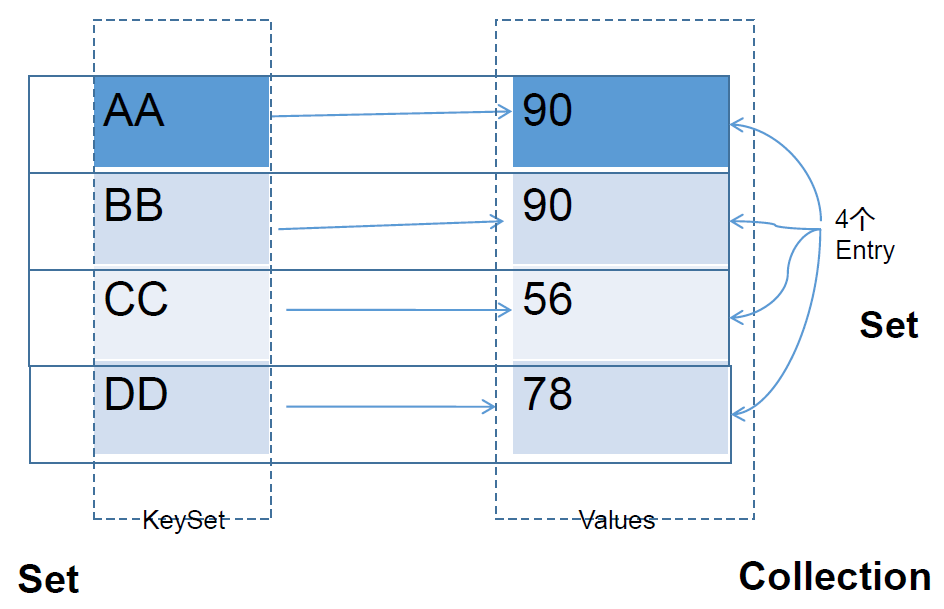
代码示例:三种遍历方式
1 public class Main { 2 public static void main(String[] args) { 3 Map<String, String> map = new HashMap<>(); 4 map.put("A", "1"); 5 map.put("B", "2"); 6 map.put("c", "3"); 7 8 // 1.获取键集:keySet() 9 final Set<String> keySet = map.keySet(); 10 for (String key : keySet) { 11 System.out.println("keySet()----" + key + "----" + map.get(key)); 12 } 13 14 // 2.获取值集:values() 15 final Collection<String> values = map.values(); 16 for (String value : values) { 17 System.out.println("values()----" + value); 18 } 19 20 // 3.获取entry集:entrySet() 21 final Set<Map.Entry<String, String>> entries = map.entrySet(); 22 for (Map.Entry<String, String> entry : entries) { 23 System.out.println("entrySet()----" + entry.getKey() + "----" + entry.getValue()); 24 } 25 } 26 }
3、Hashtable<K,V>
4、TreeMap<K,V>
向TreeMap中添加key-value,要求key①必须是相同类型的对象。②必须可排序。用于给map集合中的键按指定属性进行排序。
代码示例:让User具有可比性,自然排序:Comparable
1 public class User implements Comparable<User> { 2 private String name; 3 private int age; 4 5 // 无参构造器 6 // 有参构造器 7 // getter & setter 8 // toString() 9 // 可以不复写equals、hashCode 10 11 // 年龄从小到大排列 12 @Override 13 public int compareTo(User user) { 14 System.out.println(this.name + "---------" + user.getName()); 15 return Integer.compare(this.age, user.age); 16 } 17 } 18 19 // 测试类 20 public static void main(String[] args) { 21 TreeMap<User, Integer> treeMap = new TreeMap<>(); 22 User u1 = new User("Tom", 23); 23 User u2 = new User("Jerry", 32); 24 User u3 = new User("Jack", 20); 25 User u4 = new User("Rose", 18); 26 27 treeMap.put(u1, 98); 28 treeMap.put(u2, 89); 29 treeMap.put(u3, 76); 30 treeMap.put(u4, 100); 31 32 for (Map.Entry<User, Integer> entry : treeMap.entrySet()) { 33 System.out.println(entry.getKey() + "---->" + entry.getValue()); 34 } 35 } 36 37 // 结果 38 Tom---------Tom 39 Jerry---------Tom 40 Jack---------Tom 41 Rose---------Tom 42 Rose---------Jack 43 User{name='Rose', age=18}---->100 44 User{name='Jack', age=20}---->76 45 User{name='Tom', age=23}---->98 46 User{name='Jerry', age=32}---->89
结果分析:按键 User 指定属性 age 排序,不难理解打印结果的比较次数。排序二叉树:
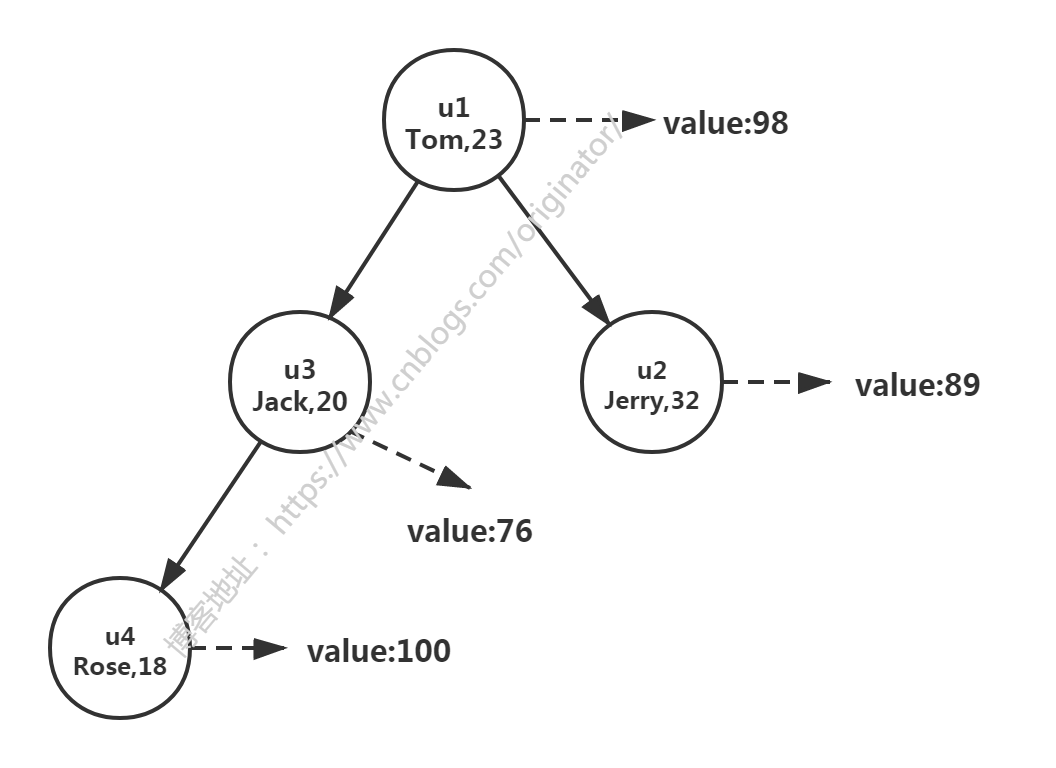
代码示例:指定比较器,定制排序:Comparator
1 // 比较器 2 public static void main(String[] args) { 3 TreeMap<User, Integer> treeMap = new TreeMap<>(new Comparator<User>() { 4 @Override 5 public int compare(User u1, User u2) { 6 return Integer.compare(u1.getAge(), u2.getAge()); 7 } 8 }); 9 10 User u1 = new User("Tom", 23); 11 User u2 = new User("Jerry", 32); 12 User u3 = new User("Jack", 20); 13 User u4 = new User("Rose", 18); 14 15 treeMap.put(u1, 98); 16 treeMap.put(u2, 89); 17 treeMap.put(u3, 76); 18 treeMap.put(u4, 100); 19 20 for (Map.Entry<User, Integer> entry : treeMap.entrySet()) { 21 System.out.println(entry.getKey() + "---->" + entry.getValue()); 22 } 23 } 24 25 // 结果.和自然排序的结果一致. 26 User{name='Rose', age=18}---->100 27 User{name='Jack', age=20}---->76 28 User{name='Tom', age=23}---->98 29 User{name='Jerry', age=32}---->89
5、Properties
常用来处理配置文件。key和value都是String类型。
代码示例:读取属性文件
1 // jdbc.properties 2 name=Tom 3 password=abc123 4 5 // 未关闭资源 6 public static void main(String[] args) throws Exception { 7 Properties pros = new Properties(); 8 9 FileInputStream fis = new FileInputStream("jdbc.properties"); 10 pros.load(fis); 11 12 String name = pros.getProperty("name"); 13 String password = pros.getProperty("password"); 14 15 System.out.println("name = " + name + ", password = " + password); 16 } 17 18 // 结果 19 name = Tom, password = abc123
6、ConcurrentHashMap<K,V>
请查看标签:JDK源码。