一、概述
1、介绍
在使用线程时,需要new一个,用完了又要销毁,这样频繁的创建和销毁很耗资源,所以就提供了线程池。道理和连接池差不多,连接池是为了避免频繁的创建和释放连接,所以在连
接池中就有一定数量的连接,要用时从连接池拿出,用完归还给连接池,线程池也一样。
线程池:一种线程使用模式。线程过多会带来调度开销,进而影响缓存局部性和整体性能。而线程池维护着多个线程,等待着监督管理者分配可并发执行的任务。这避免了在处理短时间任务时创建与销毁线程的代价。线程池不仅能够保证内核的充分利用,还能防止过分调度。
脑图:https://www.processon.com/view/link/61849ba4f346fb2ecc4546e5
2、简单使用
线程池用法很简单, 分为三步。首先用工具类Executors创建线程池,然后给线程池分配任务,最后关闭线程池就行了。
1 public class ThreadPoolTest { 2 public static void main(String[] args) throws Exception { 3 4 // 1.创建一个 10 个线程数的线程池 5 ExecutorService service = Executors.newFixedThreadPool(10); 6 7 // 2.执行一个Runnable 8 service.execute(new Number1()); 9 10 // 2.提交一个Callable 11 Future<Integer> future = service.submit(new Number2()); 12 Integer integer = future.get(); 13 System.out.println("result = " + integer); 14 15 // 关闭线程池 16 service.shutdown(); 17 } 18 } 19 20 class Number1 implements Runnable { 21 22 @Override 23 public void run() { 24 System.out.println("----打印Runnable----"); 25 } 26 } 27 28 // 10以内数求和 29 class Number2 implements Callable<Integer> { 30 private int sum = 0; 31 32 @Override 33 public Integer call() { 34 for (int i = 0; i <= 10; i++) { 35 if (i % 2 == 0) { 36 sum += i; 37 } 38 } 39 return sum; 40 } 41 }
注意:线程用完,要关闭线程池,否则程序依然在运行中。
3、相关API
JDK 5.0 起提供了线程池相关API:顶级接口Executor,及子接口 ExecutorService 和工具类Executors。

JUC包描述:图片来源API文档
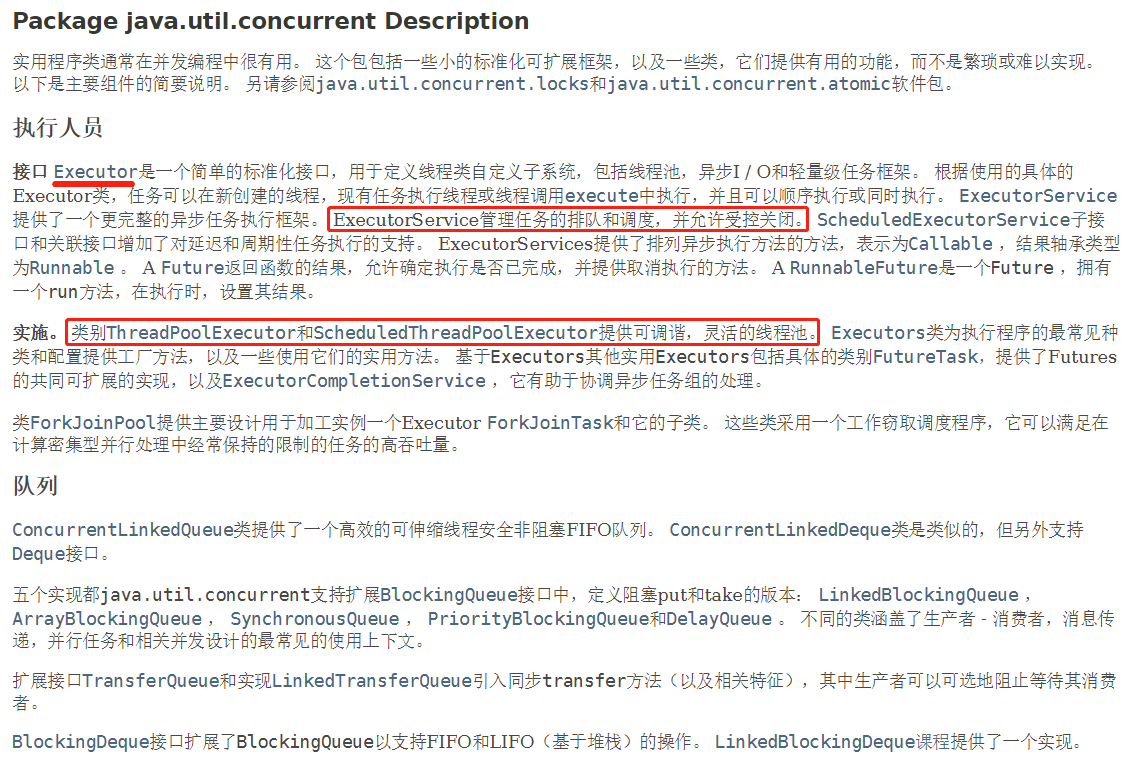
Executors:工具类,线程池的工厂类,用于创建并返回不同类型的线程池。
1 // 一池N线程:创建一个固定(可重用)线程数的线程池。 2 ExecutorService Executors.newFixedThreadPool(int nThreads) 3 4 // 一池一线程:创建一个只有一个线程的线程池。 5 ExecutorService Executors.newSingleThreadExecutor() 6 7 // 可扩容:创建一个可根据需要线程数,创建新的线程的线程池。 8 ExecutorService Executors.newCachedThreadPool() 9 10 // 可用于调度:创建一个线程池,它可安排在给定延迟后运行命令或者定期的执行。 11 ScheduledExecutorService Executors.newScheduledThreadPool(int corePoolSize)
ExecutorService:
1 // 执行任务/命令,没有返回值,一般用来执行Runnable 2 void execute(Runnable command) 3 4 // 可用于提交一个Runnable,但没有返回值 5 Future<?> submit(Runnable task) 6 7 // 执行任务,有返回值,一般用来执行Callable 8 <T> Future<T> submit(Callable<T> task) 9 10 // 关闭连接池 11 void shutdown()
4、使用举例
代码示例:创建固定 5 个线程的线程池为 10 个任务服务。
1 public class ThreadPoolTest { 2 public static void main(String[] args) { 3 // 1.创建一个 10 个线程数的线程池 4 ExecutorService service = Executors.newFixedThreadPool(5); 5 6 try { 7 for (int i = 0; i < 10; i++) { 8 int finalI = i; 9 service.execute(() -> { 10 11 System.out.println(Thread.currentThread().getName() + " 为客户 " + finalI + " 办理业务~"); 12 13 // try { 14 // Thread.sleep(1000_000); 15 // } catch (InterruptedException e) { 16 // e.printStackTrace(); 17 // } 18 19 }); 20 } 21 } finally { 22 service.shutdown(); 23 } 24 } 25 } 26 27 // 可能的一种结果 28 pool-1-thread-1 为客户 0 办理业务~ 29 pool-1-thread-2 为客户 1 办理业务~ 30 pool-1-thread-2 为客户 6 办理业务~ 31 pool-1-thread-2 为客户 7 办理业务~ 32 pool-1-thread-2 为客户 8 办理业务~ 33 pool-1-thread-1 为客户 5 办理业务~ 34 pool-1-thread-2 为客户 9 办理业务~ 35 pool-1-thread-3 为客户 2 办理业务~ 36 pool-1-thread-4 为客户 3 办理业务~ 37 pool-1-thread-5 为客户 4 办理业务~
可以看到,银行 5 个窗口为 10 个客户相继服务。若前面服务时间长(打开注释),线程池便没有新的线程来执行任务了。程序会陷入等待中。
代码示例:创建单个线程的线程池为 10 个线程服务。代码同上,只修改:
1 ExecutorService service = Executors.newSingleThreadExecutor();
代码示例:创建可扩容线程的线程池为 10 个线程服务。代码同上,只修改:
1 ExecutorService service = Executors.newCachedThreadPool();
5、线程池好处
为什么要用线程池管理线程呢?当然是为了线程复用。
背景:经常创建和销毁、使用量特别大的资源,比如并发情况下的线程,对性能影响很大。
思路:提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁的创建和销毁,实现重复利用。类似生活中的公共交通工具。
好处:提高响应速度(减少了创建新线程的时间);降低资源消耗(重复利用线程池中线程,不需要每次都创建);便于线程管理。
二、线程池设计与实现
1、介绍
前面介绍了三种(固定数、单一的、可变的)创建线程池的方式,实际工作用哪一个呢?都不使用!为什么呢?
《阿里巴巴Java开发手册》明确规定:线程池不允许使用Executors创建,而是通过ThreadPoolExecutor的方式,规避资源耗尽风险。

查看源码,可以看到,用Executors创建线程池的三种方式中,都 new 了一个 ThreadPoolExecutor。所以,实际生产一般通过 ThreadPoolExecutor 的 7 个参数,自定义线程池。
源码示例:7 个参数的构造器。
1 public ThreadPoolExecutor(int corePoolSize, 2 int maximumPoolSize, 3 long keepAliveTime, 4 TimeUnit unit, 5 BlockingQueue<Runnable> workQueue, 6 ThreadFactory threadFactory, 7 RejectedExecutionHandler handler) { 8 if (corePoolSize < 0 || 9 maximumPoolSize <= 0 || 10 maximumPoolSize < corePoolSize || 11 keepAliveTime < 0) 12 throw new IllegalArgumentException(); 13 if (workQueue == null || threadFactory == null || handler == null) 14 throw new NullPointerException(); 15 this.corePoolSize = corePoolSize; 16 this.maximumPoolSize = maximumPoolSize; 17 this.workQueue = workQueue; 18 this.keepAliveTime = unit.toNanos(keepAliveTime); 19 this.threadFactory = threadFactory; 20 this.handler = handler; 21 }
2、银行服务
介绍线程池之前,先来看一个生活中的案例。银行业务办理流程,如图:
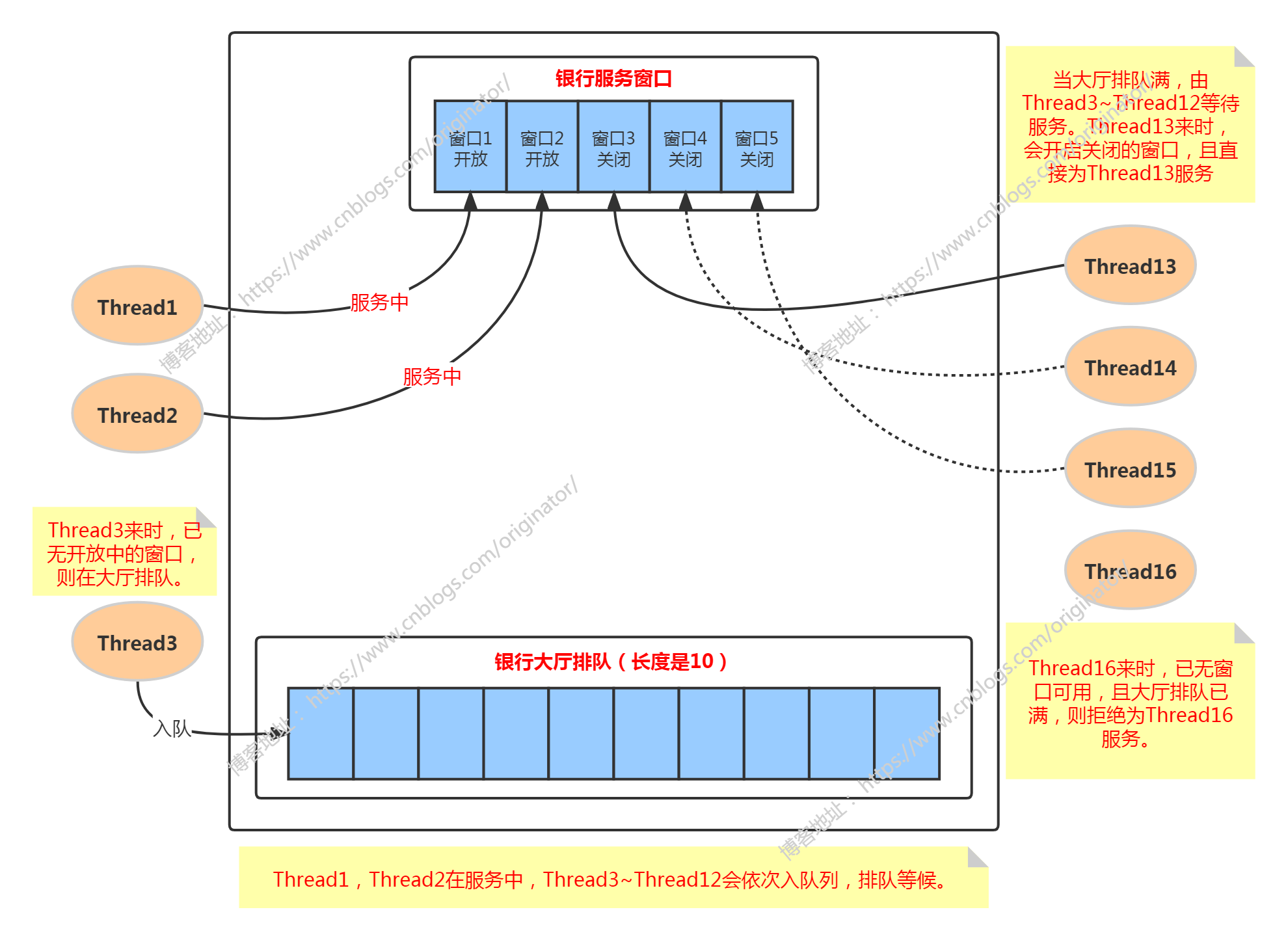
某银行一共有 5 个服务窗口,但平时一般只开放两个,另外三个不开放。大厅中还有 10 个等待服务的座位。某天:
(1)客人1(用Thread1表示)来办理业务,他就直接去开放的窗口1办理(假设他需要服务的时间很长,一直在服务中,后面的也一样)。
(2)Thread2来办理业务,由于窗口1在服务中,所以他去了开放的窗口2办理。
(3)Thread3来办理业务,由于窗口1和窗口2都在服务中,所以他去了大厅的等待服务座位上排队等待。
(4)Thread4~Thread12 同理Thread3。
(5)Thread13来办理业务,由于窗口1和窗口2都在服务中,且此时大厅的等待座位上也已满。银行经理便将关闭的窗口3打开来为Thread13服务。注意:这里并不是Thread13去大厅排队,然后队列中队头元素Thread3出队接受服务。而是直接为Thread13服务。
(6)Thread14,Thread15来办理业务,会开放窗口4为Thread14服务,开放窗口5为Thread15服务。
(7)Thread16来办理业务,此时,已无可用窗口,且大厅的等待座位上也已满。银行便拒绝再为 Thread16 服务。
说明:若 Thread13、Thread14、Thread15 业务办理完毕后,没有新的客人来银行办理业务。那么窗口3、窗口4、窗口5会在一定时间后又关闭起来。
3、核心参数(重要)
下面介绍 ThreadPoolExecutor 构造器中的 7 个核心参数。
corePoolSize:线程池的核心线程数。
maximumPoolSize:线程池的最大线程数,要大于corePoolSize。
keepAliveTime:非核心线程闲置下来最多存活的时间。
unit:线程池中非核心线程保持存活的时间单位,与keepAliveTime一起使用。
workQueue:用来保存提交后,等待执行任务的阻塞队列。
threadFactory:创建线程的工厂类。
handler:拒绝策略。
在理解上一节"银行服务"的过程后,就不难理解上面 7 个参数的含义。
corePoolSize = 2:窗口1 + 窗口2。
maximumPoolSize = 5:窗口1 + 窗口2 + 窗口3 + 窗口4 + 窗口5。
workQueue = 10:银行大厅排队队列的大小。关于阻塞队列 BlockingQueue<Runnable> workQueue 请看这篇。
keepAliveTime + unit:"窗口3、窗口4、窗口5会在一定时间后又关闭起来"的时间。
handler:"银行便拒绝再为 Thread16 服务"的拒绝方式。
在了解 ThreadPoolExecutor 7个核心参数的作用后,再看Executors创建的三种线程池的源码,就不难理解他们的作用。也就明白为什么《阿里巴巴Java开发手册》中禁止使用Executors创建,而要使用ThreadPoolExecutor自定义线程池。
源码示例:
一池N线程:创建一个固定(可重用)线程数的线程池。
1 ExecutorService Executors.newFixedThreadPool(int nThreads); 2 3 public static ExecutorService newFixedThreadPool(int nThreads) { 4 return new ThreadPoolExecutor(nThreads, nThreads, 5 0L, TimeUnit.MILLISECONDS, 6 new LinkedBlockingQueue<Runnable>()); 7 } 8 9 public LinkedBlockingQueue() { 10 this(Integer.MAX_VALUE); 11 }
一池一线程:创建一个只有一个线程的线程池。
1 ExecutorService Executors.newSingleThreadExecutor(); 2 3 public static ExecutorService newSingleThreadExecutor() { 4 return new FinalizableDelegatedExecutorService 5 (new ThreadPoolExecutor(1, 1, 6 0L, TimeUnit.MILLISECONDS, 7 new LinkedBlockingQueue<Runnable>())); 8 } 9 10 public LinkedBlockingQueue() { 11 this(Integer.MAX_VALUE); 12 }
可扩容:创建一个可根据需要线程数,创建新的线程的线程池。
1 ExecutorService Executors.newCachedThreadPool(); 2 3 public static ExecutorService newCachedThreadPool() { 4 return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 5 60L, TimeUnit.SECONDS, 6 new SynchronousQueue<Runnable>()); 7 }
4、工作流程(重要)
在理解"银行服务"的过程后,其实也就说清楚了线程池的工作流程。只是一些细节没有说,比如:
(1)窗口3为Thread13服务完成后,Thread14才来,情况如何?
(2)……
代码示例:银行 2+3 个窗口为陆续来的 16 个客户服务。
1 public class ThreadPoolDemo { 2 public static void main(String[] args) throws Exception { 3 // 模拟上图中 2 + 3 + 10(大厅排队长度) 的线程池 4 ThreadPoolExecutor executor = new ThreadPoolExecutor( 5 2, 5 6 , 6, TimeUnit.SECONDS 7 , new ArrayBlockingQueue<>(10) 8 , Executors.defaultThreadFactory() 9 , new ThreadPoolExecutor.AbortPolicy()); 10 11 // 创建16个线程模拟16个客户 12 final int num = 16; 13 for (int i = 1; i <= num; i++) { 14 int finalI = i; 15 16 // 这里主要为了给线程起名字. 17 Thread thread = new Thread(() -> { 18 System.out.println(Thread.currentThread().getName() + "=====" + finalI + " 号客人开始服务"); 19 20 // 假设 13 和 16 服务很快. 21 if (finalI != 16 && finalI != 13) { 22 try { 23 // 正在为 finalI 号客户服务中 24 Thread.sleep(1000_000); 25 } catch (InterruptedException e) { 26 e.printStackTrace(); 27 } 28 } 29 30 System.out.println(Thread.currentThread().getName() + "=====" + finalI + " 号客人服务结束"); 31 }, "------" + i); 32 33 System.out.println(thread.getName() + " 号客人来了"); 34 executor.execute(thread); 35 36 // 让主线程休息一下,保证上面开启的线程先执行. 37 Thread.sleep(200); 38 } 39 40 // 保证上面的线程执行完 41 Thread.sleep(1_000); 42 43 System.out.println("===核心线程数===" + executor.getCorePoolSize()); 44 System.out.println("===总任务数=====" + executor.getTaskCount()); 45 46 final BlockingQueue<Runnable> queue = executor.getQueue(); 47 System.out.println("===正在排队====" + queue.size()); 48 49 System.out.println("===最大线程数===" + executor.getMaximumPoolSize()); 50 System.out.println("==============" + executor.getPoolSize()); 51 System.out.println("===完成任务数===" + executor.getCompletedTaskCount()); 52 System.out.println("==============" + executor.getLargestPoolSize()); 53 54 executor.shutdown(); 55 } 56 } 57 58 // 结果(程序未停止) 59 ------1 号客人来了 60 pool-1-thread-1=====1 号客人开始服务 61 ------2 号客人来了 62 pool-1-thread-2=====2 号客人开始服务 63 ------3 号客人来了 64 ------4 号客人来了 65 ------5 号客人来了 66 ------6 号客人来了 67 ------7 号客人来了 68 ------8 号客人来了 69 ------9 号客人来了 70 ------10 号客人来了 71 ------11 号客人来了 72 ------12 号客人来了 // 到这里都不难理解 73 ------13 号客人来了 74 pool-1-thread-3=====13 号客人开始服务 75 pool-1-thread-3=====13 号客人服务结束 // 开放窗口3为客户13立刻服务完毕. 76 pool-1-thread-3=====3 号客人开始服务 // 阻塞队列,队头 客户3 出队接受窗口3的服务 77 ------14 号客人来了 // 加入阻塞队列队尾 78 ------15 号客人来了 79 pool-1-thread-4=====15 号客人开始服务 80 ------16 号客人来了 81 pool-1-thread-5=====16 号客人开始服务 82 pool-1-thread-5=====16 号客人服务结束 83 pool-1-thread-5=====4 号客人开始服务 84 ===核心线程数===2 85 ===总任务数=====16 86 ===正在排队====9 87 ===最大线程数===5 88 ==============5 89 ===完成任务数===2 90 ==============5
其他的情况,可通过修改代码示例中相关参数进行测试,自然就理解。
5、如何配置线程数
线程在Java中属于稀缺资源,线程池不是越大越好,也不是越小越好。那么,线程池的参数要如何设置才合理呢?
任务分为CPU密集型、IO密集型、混合型。
CPU密集型:大部分都在用CPU跟内存,加密,逻辑操作,业务处理等。
IO密集型:数据库链接,网络通讯传输等。
CPU密集型:一般推荐线程池不要过大,一般是CPU数 + 1,+1是因为可能存在页缺失(就是可能存在有些数据在硬盘中需要多来一个线程将数据读入内存)。如果线程池数太大,可能会频繁的进行线程上下文切换跟任务调度。
获得当前CPU核心数代码如下:
1 Runtime.getRuntime().availableProcessors();
IO密集型:线程数适当大一点,机器的CPU核心数*2。
混合型:可以考虑根绝情况将它拆分成CPU密集型和IO密集型任务,如果执行时间相差不大,拆分可以提升吞吐量,反之没有必要。
三、拒绝策略
1、介绍
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略,就会调用这个接口里的这个方法。也就是"银行便拒绝再为 Thread16 服务"的拒绝方式。
1 public interface RejectedExecutionHandler { 2 void rejectedExecution(Runnable r, ThreadPoolExecutor executor); 3 }
2、4种拒绝策略
ThreadPoolExecutor 提供了四种拒绝策略,分别是
AbortPolicy:直接抛出异常,这也是默认策略。
CallerRunsPolicy:返回给调用者处理。用调用者所在线程来运行任务。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入队列中尝试再次提交当前任务。
DiscardPolicy:不处理,直接丢弃当前任务。
代码示例:4种拒绝策略,代码同上,只需修改:
1 // 1.去掉这个if条件 2 if (finalI != 16 && finalI != 13) {} 3 4 5 6 // 2.1 线程池创建时拒绝策略为: 7 new ThreadPoolExecutor.AbortPolicy() 8 // 2.1 结果,直接抛出了异常.(只截取了最后一点) 9 ------16 号客人来了 10 Exception in thread "main" java.util.concurrent.RejectedExecutionException 11 12 13 14 // 2.2 线程池创建时拒绝策略为: 15 new ThreadPoolExecutor.CallerRunsPolicy() 16 // 2.2 结果,返回给调用者main处理了.(只截取了最后一点) 17 ------16 号客人来了 18 main=====16 号客人开始服务 19 20 21 22 // 2.3 线程池创建时拒绝策略为: 23 new ThreadPoolExecutor.DiscardOldestPolicy() 24 // 2.3 结果,见下图 25 26 27 28 // 2.4 线程池创建时拒绝策略为: 29 new ThreadPoolExecutor.DiscardPolicy() 30 // 2.4 结果(丢弃了任务,没有任何处理)
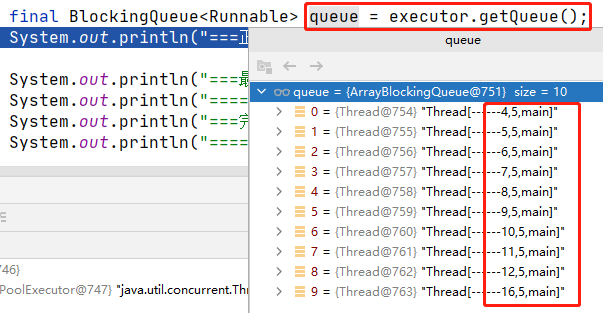
通过debug断点的方式,可以查看到:DiscardOldestPolicy策略中,此时阻塞队列中是客户4~客户16。也就是客户3 出队,被抛弃,客户16入队等待。
3、自定义拒绝策略
如果不使用线程池提供的4种拒绝策略,也可以自己实现拒绝策略的接口,实现对这些超出数量的任务的处理。比如:为被拒绝的任务开启一个新的线程执行,如下。
1 // 线程池创建时拒绝策略为: 2 new MyRejectedExecutionHandler() 3 // 结果 4 ------16 号客人来了 5 ---开启新线程处理任务---=====16 号客人开始服务 6 7 8 // 自定义的策略拒绝 9 class MyRejectedExecutionHandler implements RejectedExecutionHandler { 10 11 @Override 12 public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) { 13 new Thread(r, "---开启新线程处理任务---").start(); 14 } 15 }
参考文档:https://www.matools.com/api/java8
《阿里巴巴Java开发手册》百度网盘:https://pan.baidu.com/s/1aWT3v7Efq6wU3GgHOqm-CA 密码: uxm8