前面曾写过一篇Selenimu做爬虫的文章,大概只说了些如何爬取信息,这篇文章主要接着来说下比较具体的用途。
假设你是某个财经网站的质量人员,上头很想知道自己网站的数据是否正确,(这里插一句,做财经的应该知道,例如国内股票的原始数据都是从上证或深证来的,之后有很多的数据提供商从2大交易所购买数据,这个不是一般公司可以做到的,看看level-2和超赢等卖得那么红火就知道了,国外的blomberg也类似。),那么就需要提供一个dashboard来展示自己的数据和其他同行(多数是竞争对手啦)的数据,这样直观且方便跟踪,同时对其他人也有说服力。
我了解下来,很多都是通过人工采样的方式来对比,比如建个excel表把自己和其他网站数据填充,这个做法费时又费力,其实selenium可以帮助我们提高效率。
大致的思路如下:
1. 获取交易所信息及股票代码
在Selenimu做爬虫已经介绍过,找某个网站股票综合页面,例如新浪就能获取到某交易所的股票代码,并抓取下来,当然,如果自己后台数据库有这个数据,那就更好了。
2. 创建一个CrawlSettings.py文件,用来存取比较网站的信息,如网站名称、URL、财经指标的xpath,示例如下,

 代码
代码 1 #!/usr/bin/python2.5.2
2 #-*- coding: utf8 -*-
3
4 import codecs
5
6 PageProfiles = (
7 {
8 "Name" : "sina",
9 "Link" : {
10 "sz" : "http://finance.sina.com.cn/realstock/company/sz%s/nc.shtml",
11 "sh" : "http://finance.sina.com.cn/realstock/company/sh%s/nc.shtml",
12 },
13 "Pattern" : {
14 "PriceClose" : "//span[@id='itemPrevious2']",
15 "QuoteLast" : "//h3[@id='itemCurrent']",
16 "BookValuePerShareYear":"//td[@id='cwjk_mgjzc']",
17 "EPS" : "//td[@id='cwjk_mgsy']",
18 "MarketCap" :"//span[@id='totalMart2']",
19 "PE" :"//td[@id='pe_ratio_lyr']",
20 "Float":"//div[@id='con04-0']/table/tbody/tr[4]/td[2]",
21 "CashPerShareYear" : "//div[@id='con04-0']/table/tbody/tr[2]/td[1]",
22 "Volume":"//span[@id='itemVolume2']",
23 },
24 "PostProcess" : {
25 "all" : {
26 "RemoveString" : [r",", r"%", r"元"]
27 },
28 },
29 ...
30 )
31
32 SiteProfiles = {
33 "sina" : {
34 "BaseLink" : "http://finance.sina.com.cn",
35 "PageProfileNames" : ["sina","sina_DPSRecentYear","sina_other"]
36 },
37 ...
38 }
39
40 CrawlProfiles = {
41 "test" : {
42 "Sites" : ["baidu","sina","yahoo"],
43 "Criteria" : ["Float", "PE", "MarketCap", "EPS", "PriceClose", "QuoteLast", "BookValuePerShareYear",
44 "CurrentRatioYear", "NetProfitMarginPercent", "GrossMargin", "CashPerShareYear",
45 "DPSRecentYear", "High52Week", "Low52Week","Volume"],
46 "TickerListFile" : "tickerList.txt",
47 "ResultFiles" : "result_%s.txt",
48 "NumTickerPerSite" : "20"
49 },
50 ...
51 }
52
53 ExchangesProfiles={
54 "HongKong":"HKG",
55 "UK":"LON",
56 "Canada":["CVE","TSE"],
57 "France":"EPA",
58 "Italy":["ISE","BIT"],
59 "TaiWan":"TPE",
60 # "China Mainland":["SHA","SHE"],
61 ...
62 }
63
64 class CrawlSettings:
65
66 def GetCrawlProfile(self, name):
67 if name in CrawlProfiles:
68 return CrawlProfiles[name]
69 return None
70
71 def GetSiteProfile(self, name):
72 if name in SiteProfiles:
73 return SiteProfiles[name]
74 return None
75
76 def GetPageProfile(self, name):
77 for prof in PageProfiles:
78 if prof["Name"] == name:
79 return prof
80 return None
81
82 def LoadTickerList(self, filename):
83 f = codecs.open(filename, 'r', 'utf-8')
84 list = []
85 for line in f:
86 list.append(line.strip())
87
88 f.close()
89 return list
90
91 def GetStockType(self, ticker):
92 if str(ticker)[0]=='0' or str(ticker)[0]=='2':
93 return "sz"
94 elif str(ticker)[0]=='6' or str(ticker)[0]=='9':
95 return "sh"
96 else:
97 return "all"
2 #-*- coding: utf8 -*-
3
4 import codecs
5
6 PageProfiles = (
7 {
8 "Name" : "sina",
9 "Link" : {
10 "sz" : "http://finance.sina.com.cn/realstock/company/sz%s/nc.shtml",
11 "sh" : "http://finance.sina.com.cn/realstock/company/sh%s/nc.shtml",
12 },
13 "Pattern" : {
14 "PriceClose" : "//span[@id='itemPrevious2']",
15 "QuoteLast" : "//h3[@id='itemCurrent']",
16 "BookValuePerShareYear":"//td[@id='cwjk_mgjzc']",
17 "EPS" : "//td[@id='cwjk_mgsy']",
18 "MarketCap" :"//span[@id='totalMart2']",
19 "PE" :"//td[@id='pe_ratio_lyr']",
20 "Float":"//div[@id='con04-0']/table/tbody/tr[4]/td[2]",
21 "CashPerShareYear" : "//div[@id='con04-0']/table/tbody/tr[2]/td[1]",
22 "Volume":"//span[@id='itemVolume2']",
23 },
24 "PostProcess" : {
25 "all" : {
26 "RemoveString" : [r",", r"%", r"元"]
27 },
28 },
29 ...
30 )
31
32 SiteProfiles = {
33 "sina" : {
34 "BaseLink" : "http://finance.sina.com.cn",
35 "PageProfileNames" : ["sina","sina_DPSRecentYear","sina_other"]
36 },
37 ...
38 }
39
40 CrawlProfiles = {
41 "test" : {
42 "Sites" : ["baidu","sina","yahoo"],
43 "Criteria" : ["Float", "PE", "MarketCap", "EPS", "PriceClose", "QuoteLast", "BookValuePerShareYear",
44 "CurrentRatioYear", "NetProfitMarginPercent", "GrossMargin", "CashPerShareYear",
45 "DPSRecentYear", "High52Week", "Low52Week","Volume"],
46 "TickerListFile" : "tickerList.txt",
47 "ResultFiles" : "result_%s.txt",
48 "NumTickerPerSite" : "20"
49 },
50 ...
51 }
52
53 ExchangesProfiles={
54 "HongKong":"HKG",
55 "UK":"LON",
56 "Canada":["CVE","TSE"],
57 "France":"EPA",
58 "Italy":["ISE","BIT"],
59 "TaiWan":"TPE",
60 # "China Mainland":["SHA","SHE"],
61 ...
62 }
63
64 class CrawlSettings:
65
66 def GetCrawlProfile(self, name):
67 if name in CrawlProfiles:
68 return CrawlProfiles[name]
69 return None
70
71 def GetSiteProfile(self, name):
72 if name in SiteProfiles:
73 return SiteProfiles[name]
74 return None
75
76 def GetPageProfile(self, name):
77 for prof in PageProfiles:
78 if prof["Name"] == name:
79 return prof
80 return None
81
82 def LoadTickerList(self, filename):
83 f = codecs.open(filename, 'r', 'utf-8')
84 list = []
85 for line in f:
86 list.append(line.strip())
87
88 f.close()
89 return list
90
91 def GetStockType(self, ticker):
92 if str(ticker)[0]=='0' or str(ticker)[0]=='2':
93 return "sz"
94 elif str(ticker)[0]=='6' or str(ticker)[0]=='9':
95 return "sh"
96 else:
97 return "all"
3. 爬取页面数据,FinanceAutomationCrawler.py;参考Selenimu做爬虫
4. 比较和保存数据,FinanceAutomationResult.py
代码 1 #!/usr/bin/python2.5.2
2 #-*- coding: utf8 -*-
3
4 import sys
5 import codecs
6
7
8 class FinanceAutomationResult:
9 ### Save / Load / Generate the result comparison ###
10
11 def SaveAsSiteResults(self, results, siteList, criteriaList, tickerList, fileName):
12 ### results[site][criteria][ticker]
13 ### Save as "result_site.txt":
14 ### ticker criteria1 criteria2 ..
15 ### ticker1 1 2
16 ### ticker2 1 2
17 ###
18 for site in siteList:
19 ...
20
21 def SaveAsCriteriaResults(self, results, siteList, criteriaList, tickerList, fileName):
22 ### results[site][criteria][ticker]
23 ### Save as "result_criteria.txt":
24 ### ticker site1 site2 ..
25 ### ticker1 1 2
26 ### ticker2 1 2
27 ###
28 for criteria in criteriaList:
29 ...
30
31 def CompareResult(self, results, siteList,criteriaList, tickerList):
32
33 for criteria in criteriaList:
34 ...
2 #-*- coding: utf8 -*-
3
4 import sys
5 import codecs
6
7
8 class FinanceAutomationResult:
9 ### Save / Load / Generate the result comparison ###
10
11 def SaveAsSiteResults(self, results, siteList, criteriaList, tickerList, fileName):
12 ### results[site][criteria][ticker]
13 ### Save as "result_site.txt":
14 ### ticker criteria1 criteria2 ..
15 ### ticker1 1 2
16 ### ticker2 1 2
17 ###
18 for site in siteList:
19 ...
20
21 def SaveAsCriteriaResults(self, results, siteList, criteriaList, tickerList, fileName):
22 ### results[site][criteria][ticker]
23 ### Save as "result_criteria.txt":
24 ### ticker site1 site2 ..
25 ### ticker1 1 2
26 ### ticker2 1 2
27 ###
28 for criteria in criteriaList:
29 ...
30
31 def CompareResult(self, results, siteList,criteriaList, tickerList):
32
33 for criteria in criteriaList:
34 ...
好了,废话不多说,大概的思路如下图:
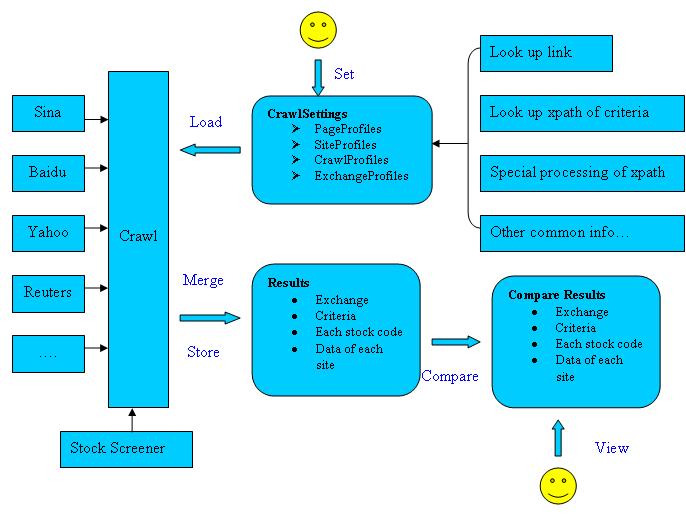
最后祝大家清明节快乐!