这篇才是原文: https://www.cnblogs.com/hiit/p/11192384.html
原文: https://www.sohu.com/a/327057430_120129354
大厂面试题:今天复试百度PHP工程师
————————————————————————————————————
面试官问了很多问题,我大概整理回忆下:
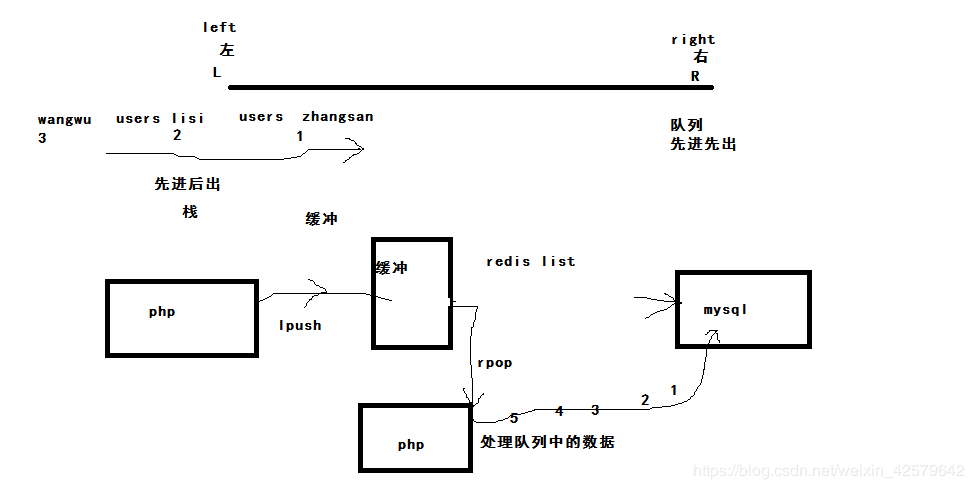
1.Redis秒杀实现?
redis队列解决抢购高并发的原理:在程序跟数据库之前呢我们可以利用redis队列做一个缓冲机制,让所有用户的请求进行排队,禀行先进先出的原则(redis中的lpush和rpop),lpush程序是把用户的请求压入redis队列,然后用rpop做一个守护进程来取队列中的数据,按规定的抢购名额写好,把所有抢购成功的用户写入redis并且生成订单,在lpush程序中查看中奖的用户并且给用户及时提醒抢购结果!
2.服务器定时器实现,crontab 、crontab -e区别,死循环如何结束?

第一种:在/etc/crontab下设置,指定用户名的1、vim命令进入/etc/crontab2、在最后一行加上59 23 * * * root /root/catina/rm_8080lina.sh3、重启crontab,使配置生效第二种:直接用crontab -e,不需要指定用户1、crontab -e进入2、:wq退出保存3、查看上面那个脚本是否有执行权限4、还要看脚本里面的涉及的操作文件是否有权限5、重启crontab,使配置生效 1.使用ctrl-c跳出死循环2.ps -ef|grep 名称 查询进程号3.kill 进程号
3.PHP如何运行shell脚本,配置文件在哪开启
php给我们提供了system(),exec(),passthru()这三个函数来调用外部的命令.虽然这三个命令都能执行linux系统的shell命令,但是其实他们是有区别的:system() 输出并返回最后一行shell结果。exec() 不输出结果,返回最后一行shell结果,所有结果可以保存到一个返回的数组里面。passthru() 只调用命令,把命令的运行结果原样地直接输出到标准输出设备上。相同点:都可以获得命令执行的状态码例子:system("/usr/a.sh"); 首先是 要关掉 安全模式 safe_mode = off然后在看看 禁用函数列表disable_functions = proc_open, popen, exec, system, shell_exec, passthru这里要把 exec 去掉重启 服务器 就OK了
4.获取HTTP头文件
1获取全部(客户端)HTTP请求头信息 #1 array apache_request_headers(void) #2:通过$_SERVER获取,每个http请求头信息都以"HTTP_"开头,在$_SERVER键中获取if_modified_since的请求信息 $_SERVER['HTTP_IF_MODIFIED_SINCE']2获取服务器响应一个HTTP请求所发送的所有标头array get_headers(string $url [, int $format = 0 ] ) # url 请求的服务器的URL地址 # format 0:返回的头部信息以索引数字形式,1:返回头部信息以关联数组形式 $head_arr = get_headers("xwww.baidu.com"); $head_arr_index = get_headers("xwww.baidu.com",1);
5.Nginx负载均衡实现,有几种方式?
1、轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。upstream backserver { server 192.168.0.14; server 192.168.0.15;}2、weight指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的 情况。upstream backserver { server 192.168.0.14 weight=3; server 192.168.0.15 weight=7;}权重越高,在被访问的概率越大,如上例,分别是30%,70%。3、ip_hash上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。upstream backserver { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80;}4、fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。5、url_hash(第三方)按访问url的hash结果来分配请求,使每个url定向到同一个(对应的)后端服务器,后端服务器为缓存时比较有效。
6.Nginx.conf rewrite里末尾符号问题 /path/to/photos /path/to/photos/区别?
当Web服务器接收到对某个末尾不含斜杠的url请求时,例如:xx.com/product,这时服务器会搜索网站根目录下有没有名为“product”的文件,如果没有就把product当做目录处理,然后返回abc目录下的默认首页。当Web服务器接收到的是末尾带斜杠的请求时就会直接当做目录处理。为了语义明确。当然现在很多应用程序是路由重写路径的。
7.cookie会话攻击防护?
什么样的Cookie信息可以被攻击者利用1. Cookie中包含了不应该让除开发者之外的其他人看到的其他信息,如USERID=1000,USERSTATUS=ONLINE,ACCOUNT_ID=xxx等等这些信息。2. Cookie信息进行了加密,但是很容易被攻击者进行解密3. 在对Cookie信息的时候没有进行输入验证如何防范利用Cookie进行的攻击1. 不要在Cookie中保存敏感信息2. 不要在Cookie中保存没有经过加密的或者容易被解密的敏感信息3. 对从客户端取得的Cookie信息进行严格校验4. 记录非法的Cookie信息进行分析,并根据这些信息对系统进行改进。5. 使用SSL/TLS来传递Cookie信息
8.PHP常用函数并说明?
9.PHP扩展文件安装过程?
phpize安装//下载libevent扩展文件压缩包(在当前系统哪个目录下载随意)~# wget xxxx/get/libevent-0.1.0.tgz//解压文件~# tar -zxvf libevent-0.1.0.tgz//进入源码目录~# cd libevent-0.1.0/如 /usr/local/php7/bin/phpize //运行phpize命令,写全phpize的路径~# ./configure --with-php-config=/usr/local/php/bin/php-config//运行configure命令,配置时 要将php-config的路径附上~# make~# make test~# sudo make install//修改php.ini,结尾加入:extension=libevent.so//重启对应的php-fpm
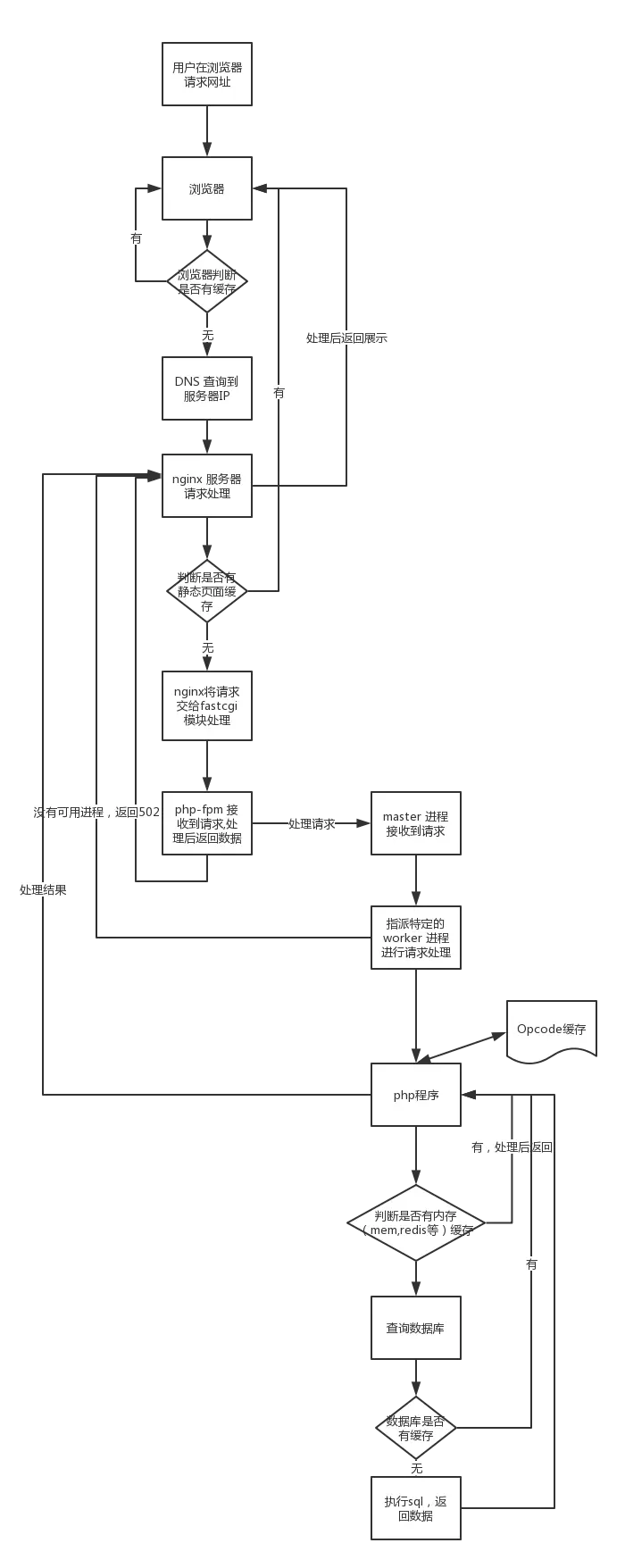
10.一个客户端http请求从服务器server到nginx到php响应返回整个流程?
HTTP 事务执行过程客户端(浏览器)做出请求操作(输入网址、点击链接、提交表单)。客户端对域名进行解析,向设定的 DNS 服务器请求 IP 地址。客户端根据 DNS 服务器返回 IP 地址采用三次握手与服务端建立 TCP/IP 连接。TCP/IP 连接成功后,客户端向服务端发送 HTTP 请求。服务端的 Web Server 会判断 HTTP 请求的资源类型,进行内容分发处理;如果请求的资源为 PHP 文件,服务端软件会启动对应的 CGI 程序进行处理,并返回处理结果。服务端将 Web Server 的处理结果响应给客户端客户端接收服务端的响应,并渲染处理结果,如果响应内容需要请求其他静态资源,通过 CDN 加速访问所需资源。客户端将渲染好的视图呈现出来并断开 TCP/IP 连接
11. CGI、FastCGI、PHP-CGI和PHP-FPM原理区别?
CGI:是公共网关接口 Web Server 与 Web Application 之间数据交换的一种协议。FastCGI:FastCGI就像是一个常驻(long-live)型的CGI程序,它可以一直运行着。同 CGI,是一种通信协议,但比 CGI 在效率上做了一些优化。同样,SCGI 协议与 FastCGI 类似。 PHP-CGI:是 PHP (Web Application)对 Web Server 提供的 CGI 协议的接口程序。 PHP-FPM:是 PHP(Web Application)对 Web Server 提供的 FastCGI 协议的接口程序,额外还提供了相对智能一些任务管理。

12.服务器状态码200 300 400 500各代表的什么?
1.200-成功2.300-307表示要完成请求,需要进一步操作,代码状态通常为重定向3.400-417表示请求可能出错了,妨碍服务器处理400-服务器不理解的请求语法401-身份验证错误403-服务器拒绝请求404-未找到网页(最常见的了服务器状态)405-方法禁用406-不接受(无法使用请求的内容特性响应请求的网页)407-需要代理授权408-请求超时(服务器等待请求超时)4.500-505表示:服务器在尝试请求处理时发生内部错误,是服务器的错,不是请求的错500-服务器内部错误(例如测试环境的服务器挂了)501-服务器不具备完成请求的功能502-错误网管503-服务器不可用(超载或者停机维护,暂停的状态)504-网关超时505-http版本不受支持(请求使用的http协议版本服务器不支持)
13.linux中把.c .h的文件编译成.so文件,gcc了解吗?
以下以编译mylib.c为例讲如何编译.so文件。首先,编译mylib.c:$gcc -c -fPIC -o mylib.o mylib.c-c表示只编译(compile),而不连接。-o选项用于说明输出(output)文件名。gcc将生成一个目标(object)文件mylib.o。注意-fPIC选项。PIC指Position Independent Code。共享库要求有此选项,以便实现动态连接(dynamic linking)。生成共享库:$gcc -shared -o mylib.so mylib.o库文件以lib开始。共享库文件以.so为后缀。-shared表示生成一个共享库。
14.Redis内存回收机制?
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据
Redis 在默认情况下会采用 noeviction 策略。换句话说,如果内存己满 , 则不再提供写入操作 , 而只提供读取操作 。 显然这往往并不能满足我们的要求,因为对于互联网系统而言 , 常常会涉及数以百万甚至更多的用户 , 所以往往需要设置回收策略。 需要指出的是 : LRU 算法或者 TTL 算法都是不是很精确算法,而是一个近似的算法。 Redis 不会通过对全部的键值对进行比较来确定最精确的时间值,从而确定删除哪个键值对 , 因为这将消耗太多的时间 , 导致回收垃圾执行的时间太长 , 造成服务停顿。15.爬虫模拟登陆,如何跳过验证码?
1、爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的url库,想做到这个并不难。2、首先得明白cookie的作用,cookie是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。因此我们需要用Cookielib模块来保持网站的cookie。3、这个是要登陆的地址 1 和验证码地址 24、可以发现这个验证码是动态更新的每次打开都不一样,一般这种验证码和cookie是同步的。其次想识别验证码肯定是吃力不讨好的事,因此我们的思路是首先访问验证码页面,保存验证码、获取cookie用于登录,然后再直接向登录地址post数据。5、首先通过抓包工具或者火狐或者谷歌浏览器分析登录页面需要post的request和header信息。模拟登录验证码地址和post地址将cookies绑定自动管理使用用户名和密码用代码访问验证码地址,获取cookie保存验证码到本地打开保存的验证码图片输入根据抓包信息 构造表单根据抓包信息 构造headers生成post数据 ?key1=value1&key2=value2的形式构造request请求打印登录后的页面登录成功后便可以利用该cookie访问其他需要登录才能访问的页面。
________________________________________________________________
面试官问了很多问题,我大概整理回忆下:
1.Redis秒杀实现?
|
1
2
3
4
5
|
redis队列解决抢购高并发的原理:在程序跟数据库之前呢我们可以利用redis队列做一个缓冲机制,让所有用户的请求进行排队,禀行先进先出的原则(redis中的lpush和rpop),lpush程序是把用户的请求压入redis队列,然后用rpop做一个守护进程来取队列中的数据,按规定的抢购名额写好,把所有抢购成功的用户写入redis并且生成订单,在lpush程序中查看中奖的用户并且给用户及时提醒抢购结果! |

2.服务器定时器实现,crontab 、crontab -e区别,死循环如何结束?

|
1
2
3
4
5
6
7
8
9
10
11
|
第一种:在/etc/crontab下设置,指定用户名的1、vim命令进入/etc/crontab2、在最后一行加上59 23 * * * root /root/catina/rm_8080lina.sh3、重启crontab,使配置生效第二种:直接用crontab -e,不需要指定用户1、crontab -e进入2、:wq退出保存3、查看上面那个脚本是否有执行权限4、还要看脚本里面的涉及的操作文件是否有权限5、重启crontab,使配置生效 |
|
1
2
3
|
1.使用ctrl-c跳出死循环2.ps -ef|grep 名称 查询进程号3.kill 进程号 |
3.PHP如何运行shell脚本,配置文件在哪开启
|
1
2
3
4
5
6
7
|
php给我们提供了system(),exec(),passthru()这三个函数来调用外部的命令.虽然这三个命令都能执行linux系统的shell命令,但是其实他们是有区别的:system() 输出并返回最后一行shell结果。exec() 不输出结果,返回最后一行shell结果,所有结果可以保存到一个返回的数组里面。passthru() 只调用命令,把命令的运行结果原样地直接输出到标准输出设备上。相同点:都可以获得命令执行的状态码例子:system("/usr/a.sh"); |
|
1
2
3
4
5
|
首先是 要关掉 安全模式 safe_mode = off然后在看看 禁用函数列表disable_functions = proc_open, popen, exec, system, shell_exec, passthru这里要把 exec 去掉重启 服务器 就OK了 |
4.获取HTTP头文件
|
1
2
3
4
5
6
|
1获取全部(客户端)HTTP请求头信息 #1 array apache_request_headers(void) #2:通过$_SERVER获取,每个http请求头信息都以"HTTP_"开头,在$_SERVER键中获取if_modified_since的请求信息 $_SERVER['HTTP_IF_MODIFIED_SINCE']2获取服务器响应一个HTTP请求所发送的所有标头array get_headers(string $url [, int $format = 0 ] ) |
|
1
|
# url 请求的服务器的URL地址 # format 0:返回的头部信息以索引数字形式,1:返回头部信息以关联数组形式 <br> $head_arr = get_headers("https://www.baidu.com"); <br> $head_arr_index = get_headers("https://www.baidu.com",1); |
5.Nginx负载均衡实现,有几种方式?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
1、轮询(默认)每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器down掉,能自动剔除。upstream backserver { server 192.168.0.14; server 192.168.0.15;}2、weight指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。upstream backserver { server 192.168.0.14 weight=3; server 192.168.0.15 weight=7;}权重越高,在被访问的概率越大,如上例,分别是30%,70%。3、ip_hash上述方式存在一个问题就是说,在负载均衡系统中,假如用户在某台服务器上登录了,那么该用户第二次请求的时候,因为我们是负载均衡系统,每次请求都会重新定位到服务器集群中的某一个,那么已经登录某一个服务器的用户再重新定位到另一个服务器,其登录信息将会丢失,这样显然是不妥的。我们可以采用ip_hash指令解决这个问题,如果客户已经访问了某个服务器,当用户再次访问时,会将该请求通过哈希算法,自动定位到该服务器。每个请求按访问ip的hash结果分配,这样每个访客固定访问一个后端服务器,可以解决session的问题。upstream backserver { ip_hash; server 192.168.0.14:88; server 192.168.0.15:80;}4、fair(第三方)按后端服务器的响应时间来分配请求,响应时间短的优先分配。5、url_hash(第三方)按访问url的hash结果来分配请求,使每个url定向到同一个(对应的)后端服务器,后端服务器为缓存时比较有效。 |
6.Nginx.conf rewrite里末尾符号问题 /path/to/photos /path/to/photos/区别?
|
1
2
3
|
当Web服务器接收到对某个末尾不含斜杠的url请求时,例如:xx.com/product,这时服务器会搜索网站根目录下有没有名为“product”的文件,如果没有就把product当做目录处理,然后返回abc目录下的默认首页。当Web服务器接收到的是末尾带斜杠的请求时就会直接当做目录处理。为了语义明确。当然现在很多应用程序是路由重写路径的。<em id="__mceDel" style=" font-family: "PingFang SC", "Helvetica Neue", Helvetica, Arial, sans-serif; font-size: 14px"> </em> |
7.cookie会话攻击防护?
|
1
2
3
4
5
6
7
8
9
10
|
什么样的Cookie信息可以被攻击者利用1. Cookie中包含了不应该让除开发者之外的其他人看到的其他信息,如USERID=1000,USERSTATUS=ONLINE,ACCOUNT_ID=xxx等等这些信息。2. Cookie信息进行了加密,但是很容易被攻击者进行解密3. 在对Cookie信息的时候没有进行输入验证如何防范利用Cookie进行的攻击1. 不要在Cookie中保存敏感信息2. 不要在Cookie中保存没有经过加密的或者容易被解密的敏感信息3. 对从客户端取得的Cookie信息进行严格校验4. 记录非法的Cookie信息进行分析,并根据这些信息对系统进行改进。5. 使用SSL/TLS来传递Cookie信息 |
8.PHP常用函数并说明?
9.PHP扩展文件安装过程?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
phpize安装//下载libevent扩展文件压缩包(在当前系统哪个目录下载随意)~# wget http://pecl.php.net/get/libevent-0.1.0.tgz//解压文件~# tar -zxvf libevent-0.1.0.tgz//进入源码目录~# cd libevent-0.1.0/如 /usr/local/php7/bin/phpize //运行phpize命令,写全phpize的路径~# ./configure --with-php-config=/usr/local/php/bin/php-config//运行configure命令,配置时 要将php-config的路径附上~# make~# make test~# sudo make install//修改php.ini,结尾加入:extension=libevent.so//重启对应的php-fpm |
10.一个客户端http请求从服务器server到nginx到php响应返回整个流程?
|
1
2
3
4
5
6
7
8
9
10
|
HTTP 事务执行过程客户端(浏览器)做出请求操作(输入网址、点击链接、提交表单)。客户端对域名进行解析,向设定的 DNS 服务器请求 IP 地址。客户端根据 DNS 服务器返回 IP 地址采用三次握手与服务端建立 TCP/IP 连接。TCP/IP 连接成功后,客户端向服务端发送 HTTP 请求。服务端的 Web Server 会判断 HTTP 请求的资源类型,进行内容分发处理;如果请求的资源为 PHP 文件,服务端软件会启动对应的 CGI 程序进行处理,并返回处理结果。服务端将 Web Server 的处理结果响应给客户端客户端接收服务端的响应,并渲染处理结果,如果响应内容需要请求其他静态资源,通过 CDN 加速访问所需资源。客户端将渲染好的视图呈现出来并断开 TCP/IP 连接 |

11. CGI、FastCGI、PHP-CGI和PHP-FPM原理区别?
|
1
2
3
4
|
CGI:是公共网关接口 Web Server 与 Web Application 之间数据交换的一种协议。FastCGI:FastCGI就像是一个常驻(long-live)型的CGI程序,它可以一直运行着。同 CGI,是一种通信协议,但比 CGI 在效率上做了一些优化。同样,SCGI 协议与 FastCGI 类似。PHP-CGI:是 PHP (Web Application)对 Web Server 提供的 CGI 协议的接口程序。PHP-FPM:是 PHP(Web Application)对 Web Server 提供的 FastCGI 协议的接口程序,额外还提供了相对智能一些任务管理。 |

12.服务器状态码200 300 400 500各代表的什么?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
1.200-成功2.300-307表示要完成请求,需要进一步操作,代码状态通常为重定向3.400-417表示请求可能出错了,妨碍服务器处理400-服务器不理解的请求语法401-身份验证错误403-服务器拒绝请求404-未找到网页(最常见的了服务器状态)405-方法禁用406-不接受(无法使用请求的内容特性响应请求的网页)407-需要代理授权408-请求超时(服务器等待请求超时)4.500-505表示:服务器在尝试请求处理时发生内部错误,是服务器的错,不是请求的错500-服务器内部错误(例如测试环境的服务器挂了)501-服务器不具备完成请求的功能502-错误网管503-服务器不可用(超载或者停机维护,暂停的状态)504-网关超时505-http版本不受支持(请求使用的http协议版本服务器不支持) |
13.linux中把.c .h的文件编译成.so文件,gcc了解吗?
|
1
2
3
4
5
6
7
8
|
以下以编译mylib.c为例讲如何编译.so文件。首先,编译mylib.c:$gcc -c -fPIC -o mylib.o mylib.c-c表示只编译(compile),而不连接。-o选项用于说明输出(output)文件名。gcc将生成一个目标(object)文件mylib.o。注意-fPIC选项。PIC指Position Independent Code。共享库要求有此选项,以便实现动态连接(dynamic linking)。生成共享库:$gcc -shared -o mylib.so mylib.o库文件以lib开始。共享库文件以.so为后缀。-shared表示生成一个共享库。 |
https://blog.csdn.net/ngvjai/article/details/8520840
14.Redis内存回收机制?
|
1
2
3
4
5
6
|
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据 |
Redis 在默认情况下会采用 noeviction 策略。换句话说,如果内存己满 , 则不再提供写入操作 , 而只提供读取操作 。 显然这往往并不能满足我们的要求,因为对于互联网系统而言 , 常常会涉及数以百万甚至更多的用户 , 所以往往需要设置回收策略。 需要指出的是 : LRU 算法或者 TTL 算法都是不是很精确算法,而是一个近似的算法。 Redis 不会通过对全部的键值对进行比较来确定最精确的时间值,从而确定删除哪个键值对 , 因为这将消耗太多的时间 , 导致回收垃圾执行的时间太长 , 造成服务停顿。
15.爬虫模拟登陆,如何跳过验证码?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
1、爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法。python提供了强大的url库,想做到这个并不难。2、首先得明白cookie的作用,cookie是某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。因此我们需要用Cookielib模块来保持网站的cookie。3、这个是要登陆的地址 1 和验证码地址 24、可以发现这个验证码是动态更新的每次打开都不一样,一般这种验证码和cookie是同步的。其次想识别验证码肯定是吃力不讨好的事,因此我们的思路是首先访问验证码页面,保存验证码、获取cookie用于登录,然后再直接向登录地址post数据。5、首先通过抓包工具或者火狐或者谷歌浏览器分析登录页面需要post的request和header信息。模拟登录验证码地址和post地址将cookies绑定自动管理使用用户名和密码用代码访问验证码地址,获取cookie保存验证码到本地打开保存的验证码图片输入根据抓包信息 构造表单根据抓包信息 构造headers生成post数据 ?key1=value1&key2=value2的形式构造request请求打印登录后的页面登录成功后便可以利用该cookie访问其他需要登录才能访问的页面。 |