OS-lab6
管道
在lab5的时候我们实现了文件类设备的读写操作,而在fd.c中,我们定义了3种设备:文件类设备、管道、终端,其中终端已经被完成了,剩下的就是管道了。
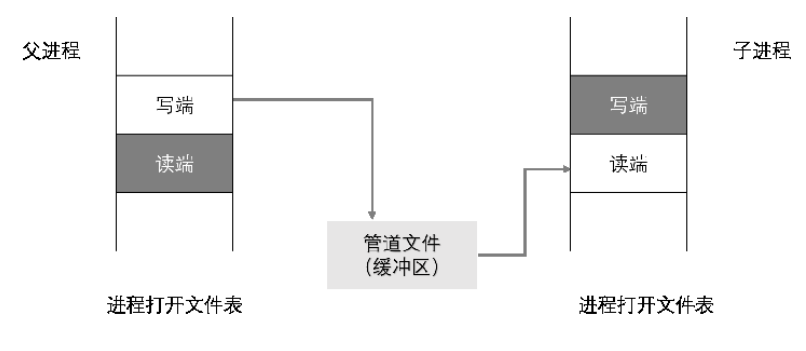
管道是一种父子进程间通信的设备,这样的通信是单向的。建立一个匿名管道的流程首先是建立一个缓冲文件,接着
-
user/pipe.c
首先我们来看看控制管道的结构体
Pipe。这个结构体很简单,由读取端位置、写入端位置、缓冲区组成,在这个实验中采用的是环形缓冲区。接着我们来创建一个管道。
pipe函数用于创建一个管道。在 pipe 中,首先分配两个文件描述符 fd0,fd1 并为其分配空间,然后给 fd0 对应的虚拟地址分配一页物理内存,再将 fd1 对应的虚拟地址映射到相同的物理内存。这一页上存的就是Pipe结构体,从而使得这两个文件描述符能够共享一个管道的数据缓冲区。
这个时候创建的管道结构是这样的
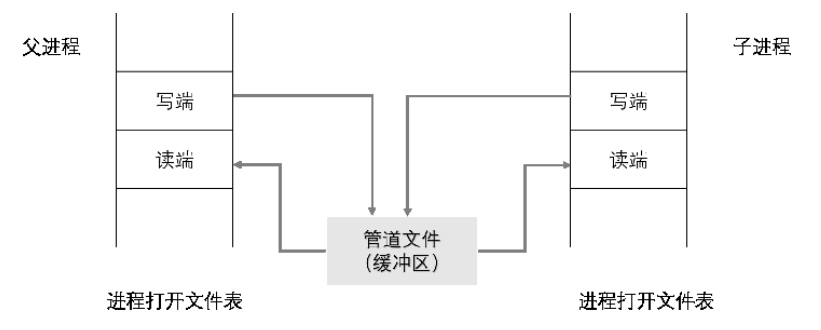
之后则需要根据具体情况关闭读端或写端,形成第一张图那样的单向流通的结构。
接下来我们开始完成管道的读写。
完成读写的功能思路很简单,也就是基本的生产者消费者模型。所以如果管道数据为空,即当
p_rpos >= p_wpos时,应该进程切换到写者运行;写者必须得在p_wpos - p_rpos < BY2PIPE时方可运行,也就是通过读写端的相对位置进行切换。
piperead函数先通过fd2data取得Pipe结构体,判断缓冲区是否为空,若为空则判断管道是否关闭,如果没关闭就进行调度;接着循环读取缓冲区,遇到缓冲区为空则需要判断管道是否关闭和进行调度,直到读取n字节。
pipewrite函数与piperead函数类似,不过这个函数每次必须写满缓冲区或写满n字节才会进行调度或退出。主体功能完成了,还有一些细节问题需要我们仔细思考,那就是读写结束应该如何判断,也就是判断管道另一端是否关闭。
假设这样的情景:管道写端已经全部关闭,读者读到缓冲区有效数据的末尾,此时有 p_rpos = p_wpos。按照上面的做法,我们这里应当切换到写者运行。但写者进程已经结束,进程切换就造成了死循环,这时候读者进程如何知道应当退出了呢?
在这里,我们利用页面的引用来完成这个功能。
第一张图上我们可以看到,管道文件所在的物理页被写端和读端同时引用,也就是说有这样的等式成立pageref(rfd) + pageref(wfd) = pageref(pipe)。对于每一个匿名管道而言,我们分配了三页空间:一页是读数据的文件描述符 rfd,一页是写数据的文件描述符 wfd,剩下一页是被两个文件描述符共享的管道数据缓冲区。
而如果写端关闭,则
pageref(wfd)=0,此时满足pageref(rfd)=pageref(pipe),因此可以使用这样的机制来判断某一端是否关闭。这个问题看上去确实解决了,不过还留有隐患。之前提到了进程需要关闭读端或写端才能进行通信,在这里调用了
close函数。int close(int fdnum) { int r; struct Dev *dev; struct Fd *fd; if ((r = fd_lookup(fdnum, &fd)) < 0 || (r = dev_lookup(fd->fd_dev_id, &dev)) < 0) { return r; } r = (*dev->dev_close)(fd); fd_close(fd); return r; }可以看到这个函数分为两步,首先是移除设备到
fd的引用,然后是移除进程对fd的引用。就有可能出现这种情况:pipe(p); if(fork() == 0){//子进程 close(p[1]); //中断1发生在close和read之间 read(p[0], buf, sizeof buf); }else{//父进程 close(p[0]);//中断2发生在dev_close和fd_close之间 write(p[1], "zzz", 3); }这个时候,父子进程都对
p[0]有引用,引用量为2,父进程对p[1]有引用,引用量为1,而pipe被父进程的p[1]和子进程的p[0]引用,引用量是2,这时子进程再执行read,比较pipe的引用和p[0]的引用发现一样,认为p[1]关闭,因此就退出了。不幸的是,fd.c中的
dup也出了类似的问题。在dup函数中发生了两次映射,首先是把oldfd映射到newfd中,然后再把oldfd的内容映射过去。比如dup(p[0], 10)这样的调用,会首先增加p[0]的引用,然后再增加pipe的引用,如果中断在这中间产生,那么pipe的引用是没有增加的,这时就出现了之前一样的问题,pipe的引用可能与p[0]或p[1]相等,造成误判。这两个函数最大的问题在于,建立映射和移除映射的顺序导致了
pipe的引用不能保证一直最大。在知道了这个问题的根源后,进行修复的操作也很容易了,就是调整顺序,保证pipe的引用最大即可。那现在就万无一失了吗?先别急,我们来看看判断管道关闭的函数
_pipeisclosed。根据我们的等式,当
p[0]或p[1]的引用与pipe相等时就判断为一端已经关闭,显然,我们需要先获得这两者的引用才行。pfd = pageref(fd); pfp = pageref(pipe); if (pfd == pfp){ return 1; } return 0;很显然,我们会想到这样写。
还是上面的例子,假如子进程执行完
close(p[1])后没有中断1,而是继续执行read,此时因为父进程未运行,缓冲区为空,就进入了_pipeisclosed函数判断是否一端已经关闭,在获得了pfd的引用量2后,中断1发生;父进程执行到wrtie中途中断2发生,这个时候已经关闭了p[0];子进程执行,获得的pipe的引用量为2,两者相等,发生误判。这个例子我们可以知道,我们获得的引用量也可能是错误的,原因在于我们没有得到最新的引用量,从而引起了误判。因此,我们需要一个循环来获得最新的引用,不过怎么知道循环可以退出呢?那就是得到的最新的引用,怎么知道这是最新的引用呢?那就是在执行过程中没有中断发生,怎么知道没有中断发生?在lab3中我们知道在时钟中断发生时,会进入调度函数
sched_yeild进行调度,在调度的最后会进入env_run切换运行,在这个函数中我们会增加env_runs代表运行的次数。也就是说,这个变量能够指示中断的发生。因此,我们在取得引用之前,先记录一下当时的env_runs,在取得引用之后再判断现在的env_runs是否一样,如果不一样则证明发生了中断,需要再次获得引用,一样则证明没有中断发生,可以退出循环。到这里,我们终于完成管道退出的判断函数
_pipeisclosed了。整个管道的读写我们就完成了。
shell
最后,我们还需要完成一个用户的交互界面,也就是shell。具体来说,我们需要能够读取用户输入的命令,并通过操作系统执行这些命令。那么命令在操作系统中是什么?在user文件夹下有ls.c、echo.c等几个文件,这几个文件就是命令的源码,最终会形成可执行文件,我们调用的命令,实际上就是运行这些可执行文件。而在此之前,我们还需要一个进程来解析这些命令,这就是sh.c。
-
user/sh.c
这就是shell进程。
_gettoken函数用于获得标识。
runcmd函数根据获得的标识运行指令。
readline函数用于读取一行指令。注意到在
runcmd中,在真正执行指令的时候实际是调用了spawn函数完成,这个函数就是具体的加载并运行一个命令文件的函数。 -
user/spawn.c
这个文件完成了加载命令文件并运行的功能。
init_stack函数用于初始化栈。
usr_is_elf_format函数用于判断文件是否为可执行文件。
usr_load_elf函数用于将可执行文件载入到内存中。我们在lab3中完成了这个任务,即load_icode_mapper函数,基本上就是照抄一遍。那为什么不能直接调用那个函数呢?首先,那个函数处于内核态,没有系统调用可以访问,此外,我们在lab3中最终是在init.c中利用ENV_CREATE手动创建进程,而对于输入不确定的shell来说,这显然做不到。
spawn函数用于载入命令文件。首先通过open打开文件,得到文件描述符;接着判断这个文件是否是可执行文件;接着使用syscall_env_alloc获得一个空闲的进程;通过init_stack初始化栈,接着利用usr_load_elf载入可执行文件,这里需要知道elf文件的格式,找到并载入所有的程序段;设置pc值和栈帧等;复制获得父进程的共享页表;最后设置进程状态。这个函数中出现的子进程也就是当前的shell进程的子进程,就是命令文件执行的进程。
到这里,我们就能够通过命令行与操作系统进行交互了。