1、知识点
1.1、标签:
我们要预测的真实事物:y 即线性回归中的变量y值
特征:指用于描述数据的输入变量:x 即线性回归中的{x1,x2,。。。,xn}变量
样本:指诗句的特定实例:x
有标签样本:{特征,标签}:{x,y} 用于训练模型
无标签样本: {特征,?}:{x,?} 用于对新数据做出预测
模型:可将样本映射到预测标签:y' 由模型的内部参数定义,这些内部参数值是通过学习得到的
1.2、训练:
表示通过“有标签样本”来学习(确定)所有权重和偏差的理想值 【y = k*x+b】 ,确定k和b的值
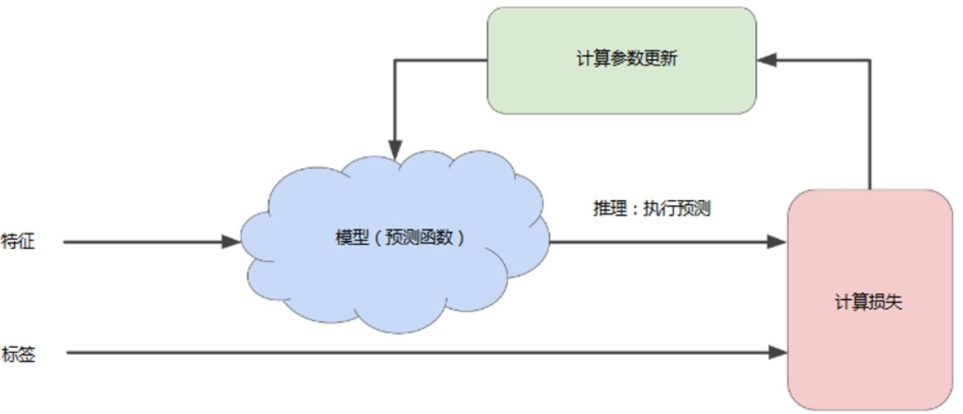
在监督式学习中,机器学习算法通过以下方式构建模型:
检查多个样本并尝试找出可最大限度地减少损失的模型,这一过程叫做“经验风险最小化”
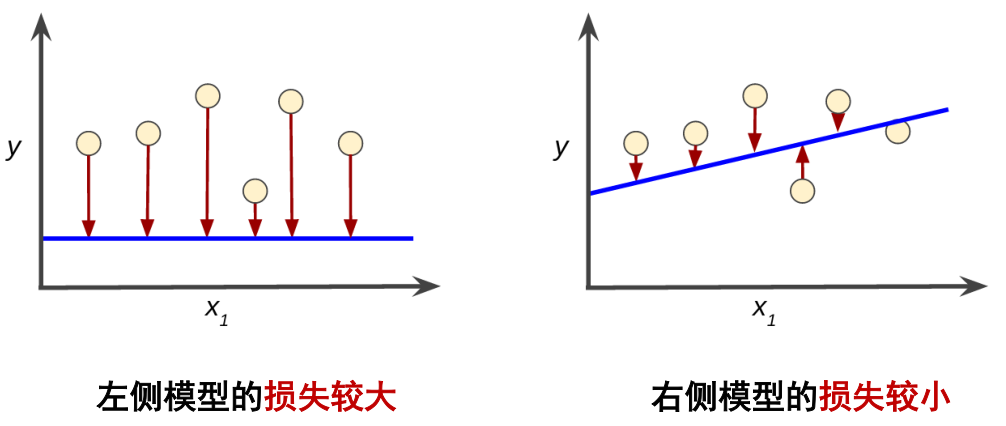
损失:是对糟糕预测的惩罚,损失是一个数值,表示对于单个样本而言模型预测的准确程度
如果模型的预测完全准确,则损失为零,否则损失会比较大
训练模型的目标是从所有样本中找到一组“平均损失”较小的权重和偏差
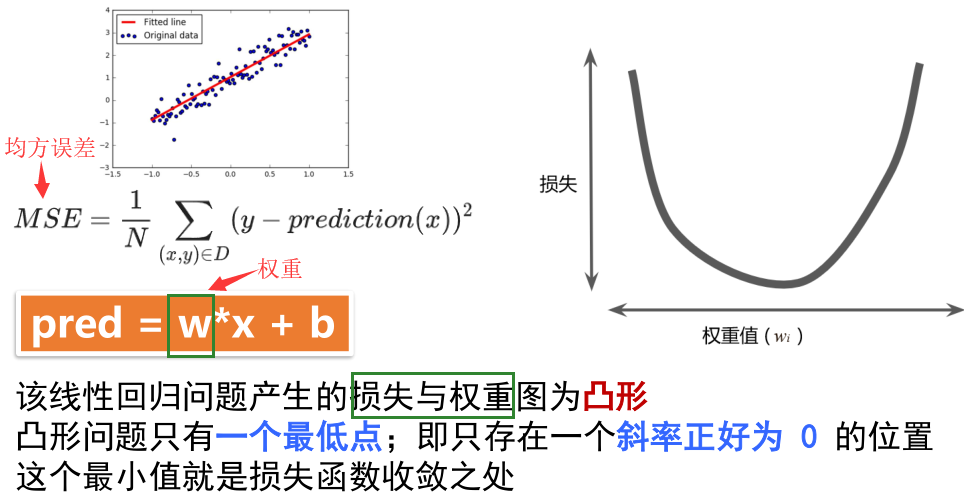
定义损失函数:
1.3、模型训练:
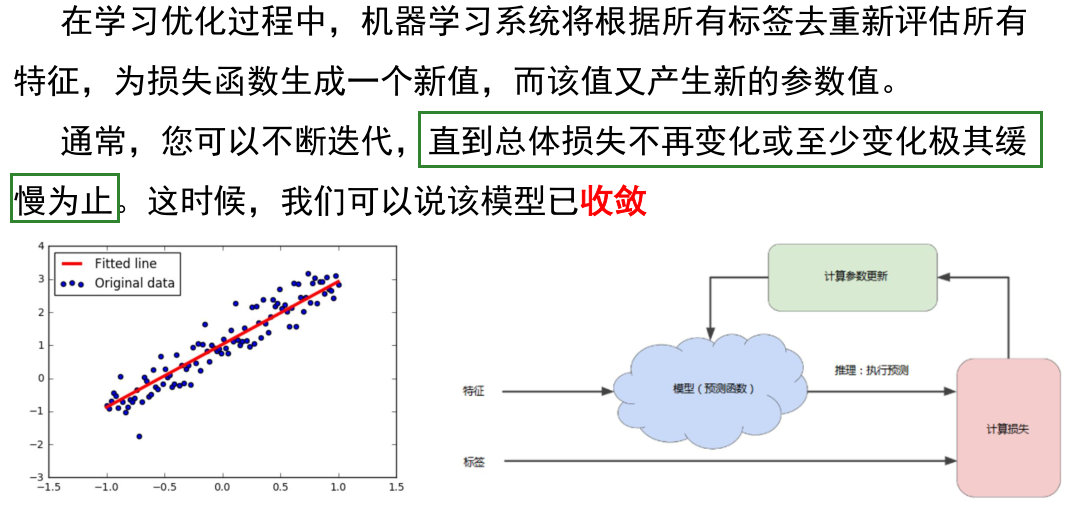
首先对权重w和偏差b进行初始猜测,然后反复调整这些猜测,直到获得损失可能最低的权重和偏差为止
收敛:机器训练的程度
计算损失:
1.4、梯度下降法:
梯度:一个向量(矢量),表示某一函数在该点处的方向沿着该方向取得最大值,即函数在该点处沿着该方向(梯度的方向)变化最快,变化率最大
方向:
沿着 负梯度方向进行下一步探索
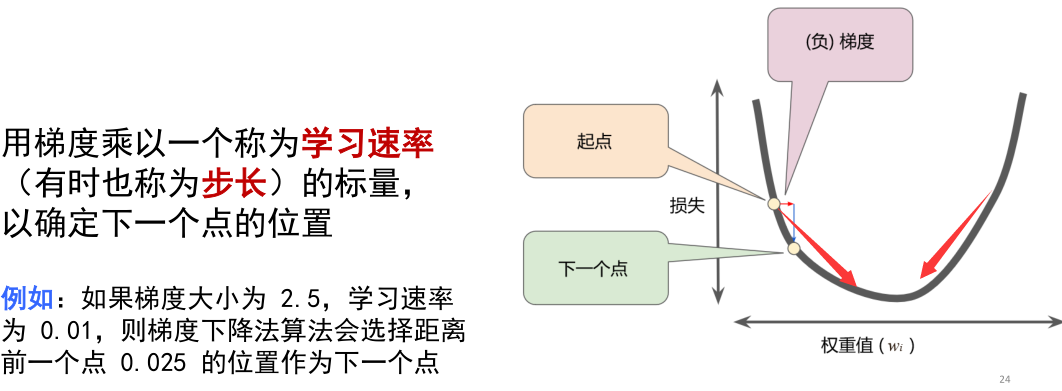
1.5、学习率 :
应适当(不应过大或过小)
沿着“负梯度”方向的下一步:
1.6、 超参数:
是在开始学习之前设置的参数,而不是通过训练得到的参数数据
【超参数】是编程人员在机器学习算法中用于调整的旋钮 例如:学习率,神经网络的隐含层数量等