1数据读取
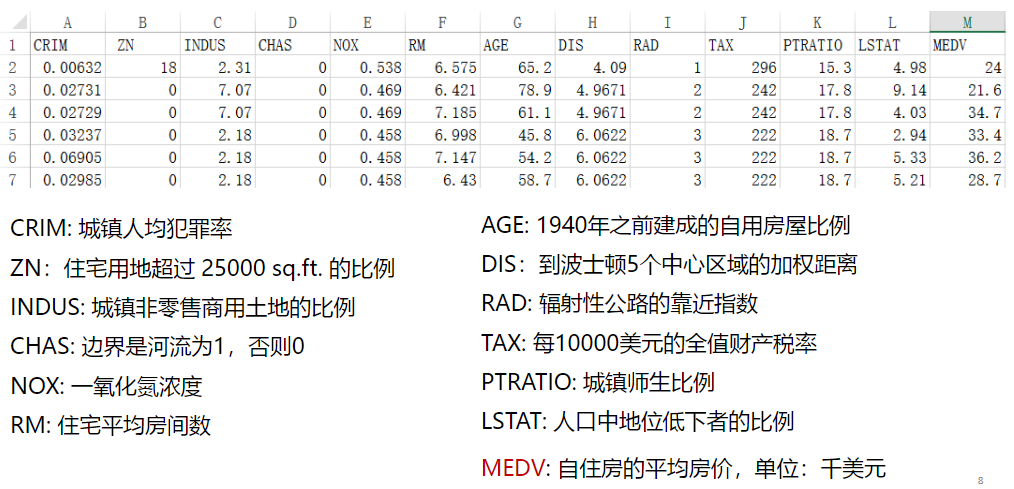
1.1数据集解读
1.2引入包
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle1.2.1pandas介绍
1.2.2TensorFlow下安装pandas
1、激活tensorflow: Activate tensorflow 2、安装Pandas: conda install pandas1.2.3出现“No module named 'sklearn'”错误
原因:未安装sklearn模块
方法:
在anaconda 中安装: conda install scikit-learn1.3显示数据
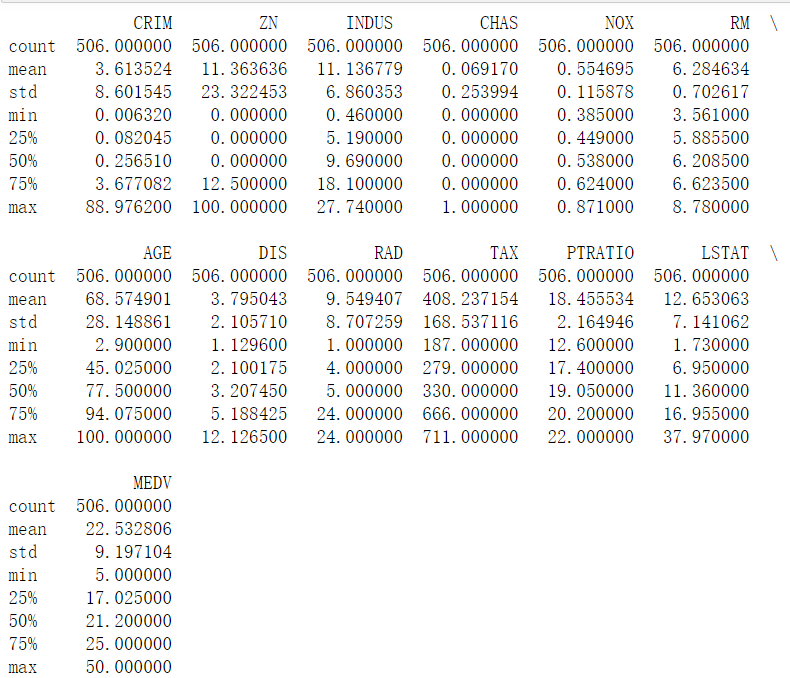
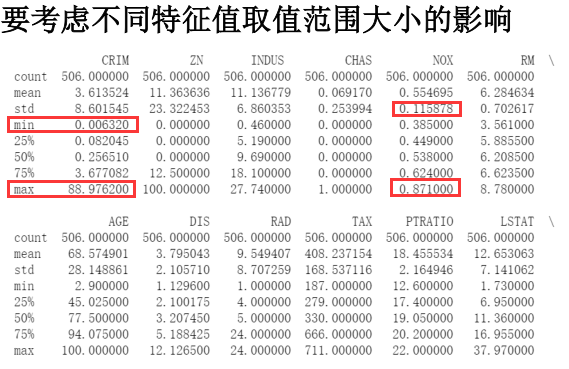
# 读取数据文件 boston.csv文件位置自填 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息 print(df.describe()
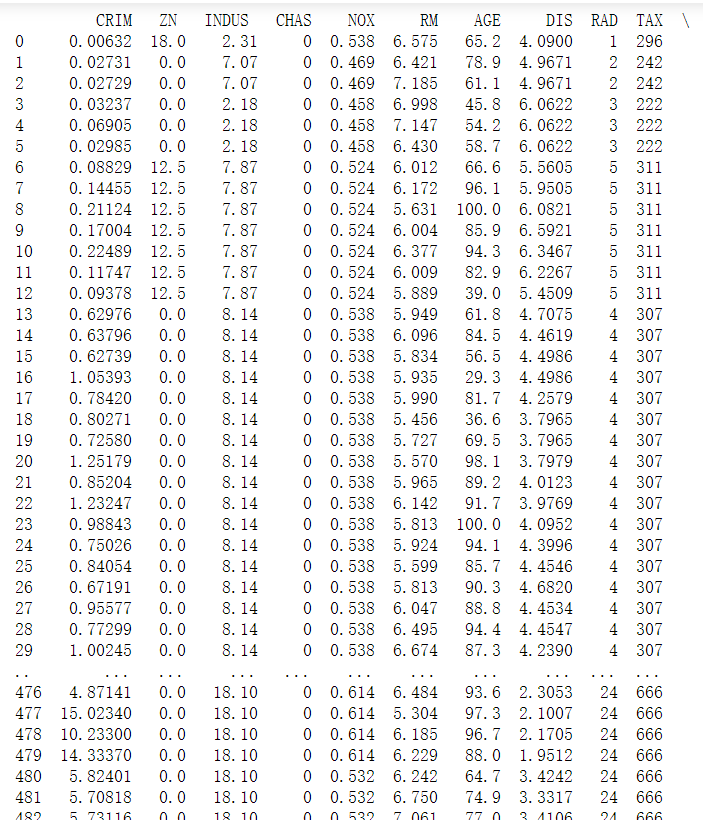
# 打印所有数据,只显示前30行和后三十行 print(df)
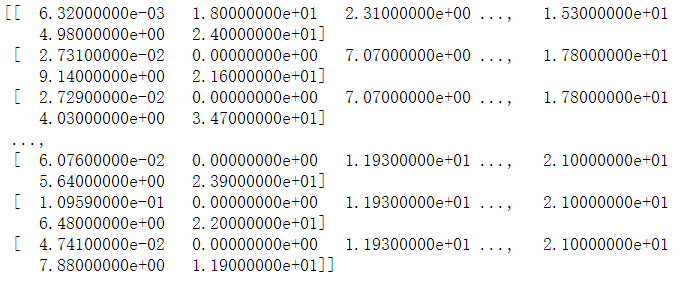
# 获取df的值 df = df.values print(df)
# 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df)
# x_data为前12列的数据,实际上是0 - 11列;y_data为最后一列的数据,即12列 x_data = df[:,:12] y_data = df[:,12] print(x_data," shape = ",x_data.shape) print(y_data," shape = ",y_data.shape)
2模型定义
2.1定义训练的占位符
#定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列)2.2定义模型结构
定义模型函数
# 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b)3模型训练
3.1设置训练超参数
# 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.013.2定义均方差损失函数
#定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2))3.3选择优化器
# 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)常用优化器包括:
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer3.4声明会话
#声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer() #启动会话 sess.run(init)3.5迭代训练
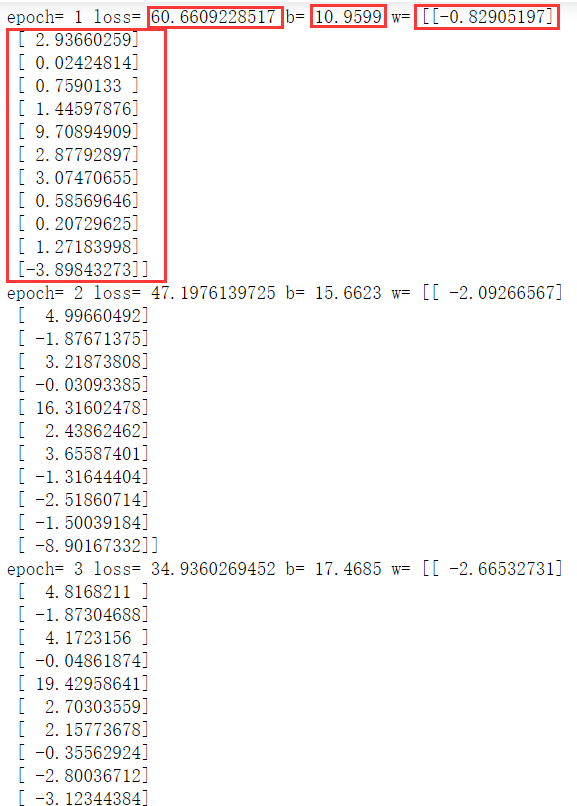
#迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:训练结果异常
3.6异常明示
3.6.1原因
3.6.2方法
4特征归一化版本
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle # 读取数据文件 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息 print(df.describe()) # 获取df的值 df = df.values print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df)特征归一化
# 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12): df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12] #y_data 为最后一列标签数据 y_data = df[:,12]#定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b) # 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.01 #定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer() #启动会话 sess.run(init) #迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:Done!
5模型应用
5.1做预测
# 指定一条数据 n = 345 x_test = x_data[n] x_test = x_test.reshape(1,12) predict = sess.run(pred,feed_dict={x:x_test}) print("预测值:%f" % predict) target = y_data[n] print("标签值:%f" % target
# 随机确定一条数据 n = np.random.randint(506) print(n) x_test = x_data[n] x_test = x_test.reshape(1,12) predict = sess.run(pred,feed_dict={x:x_test}) print("预测值:%f" % predict) target = y_data[n] print("标签值:%f" % target)

6可视化训练过程中的损失值
6.1每轮训练后添加一个这一轮的Loss值
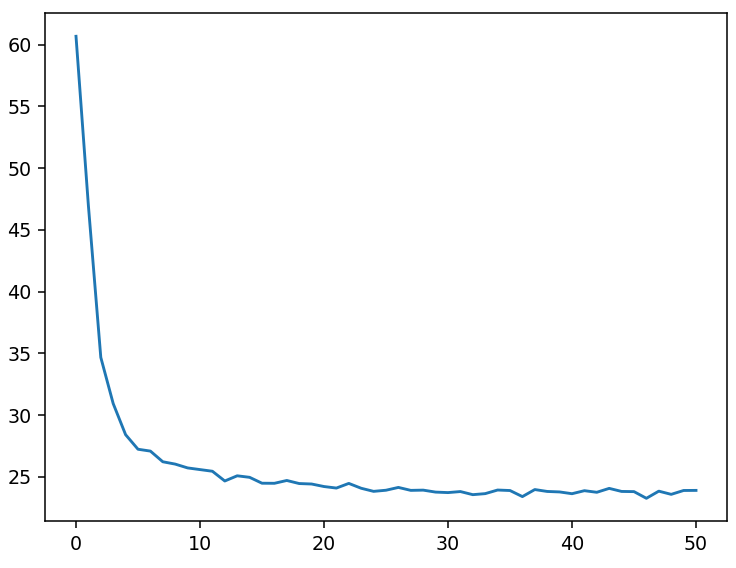
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle # 读取数据文件 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 获取df的值 df = df.values print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12): df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12] #y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b) # 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.01 #定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer() #启动会话 sess.run(init)# 用于保存 loss值得列表 loss_list = [] #迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.1.2可视化损失值
plt.figure() plt.plot(loss_list)
# 指定一条数据 n = 345 x_test = x_data[n] x_test = x_test.reshape(1,12) predict = sess.run(pred,feed_dict={x:x_test}) print("预测值:%f" % predict) target = y_data[n] print("标签值:%f" % target)
6.2每步(单个样本)训练后添加这个Loss值
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle # 读取数据文件 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 获取df的值 df = df.values print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12): df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12] #y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b) # 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.01 #定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer() #启动会话 sess.run(init) # 用于保存 loss值得列表 loss_list = [] #迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss loss_list.append(loss) # 每步添加一次 #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.2.2可视化损失值
plt.figure() plt.plot(loss_list)
# 指定一条数据 n = 345 x_test = x_data[n] x_test = x_test.reshape(1,12) predict = sess.run(pred,feed_dict={x:x_test}) print("预测值:%f" % predict) target = y_data[n] print("标签值:%f" % target)
7加上 TensorBoard 可视化代码
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle # 读取数据文件 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 获取df的值 df = df.values print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12): df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12] #y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b) # 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.01 #定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer() #启动会话 sess.run(init) # 用于保存 loss值得列表 loss_list = [] #迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8为TensorFlow可视化准备数据
8.1修改代码
%matplotlib notebook import tensorflow as tf import matplotlib.pyplot as plt import numpy as np import pandas as pd from sklearn.utils import shuffle # 读取数据文件 df = pd.read_csv("D:学习资料课程学习资料深度学习TensorFlow/boston.csv",header = 0) # 获取df的值 df = df.values print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能 df = np.array(df) print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12): df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12] #y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符 #shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一 #个样本的随机SDG到批量SDG都可以 x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列) y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间 with tf.name_scope("model"): # w 初始化值为shape = (12,1)的随机数 stddev为标准差 w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w") # b 初始化值为 1.0 b = tf.Variable(1.0,name = "b") #w和x是矩阵相乘,用matmul,不能用mutiply或* def model(x,w,b): return tf.matmul(x,w) + b #预测计算操作,前向计算节点 pred = model(x,w,b) # 迭代轮次 train_epochs = 50 # 学习率 learning_rate = 0.01 #定义均方差损失函数 with tf.name_scope("LossFunction"): loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话 sess = tf.Session() #定义初始化变量的操作 init = tf.global_variables_initializer()8.1.1设置日志存储目录
# 设置日志存储目录 logdir = 'd:/log'8.1.2创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见
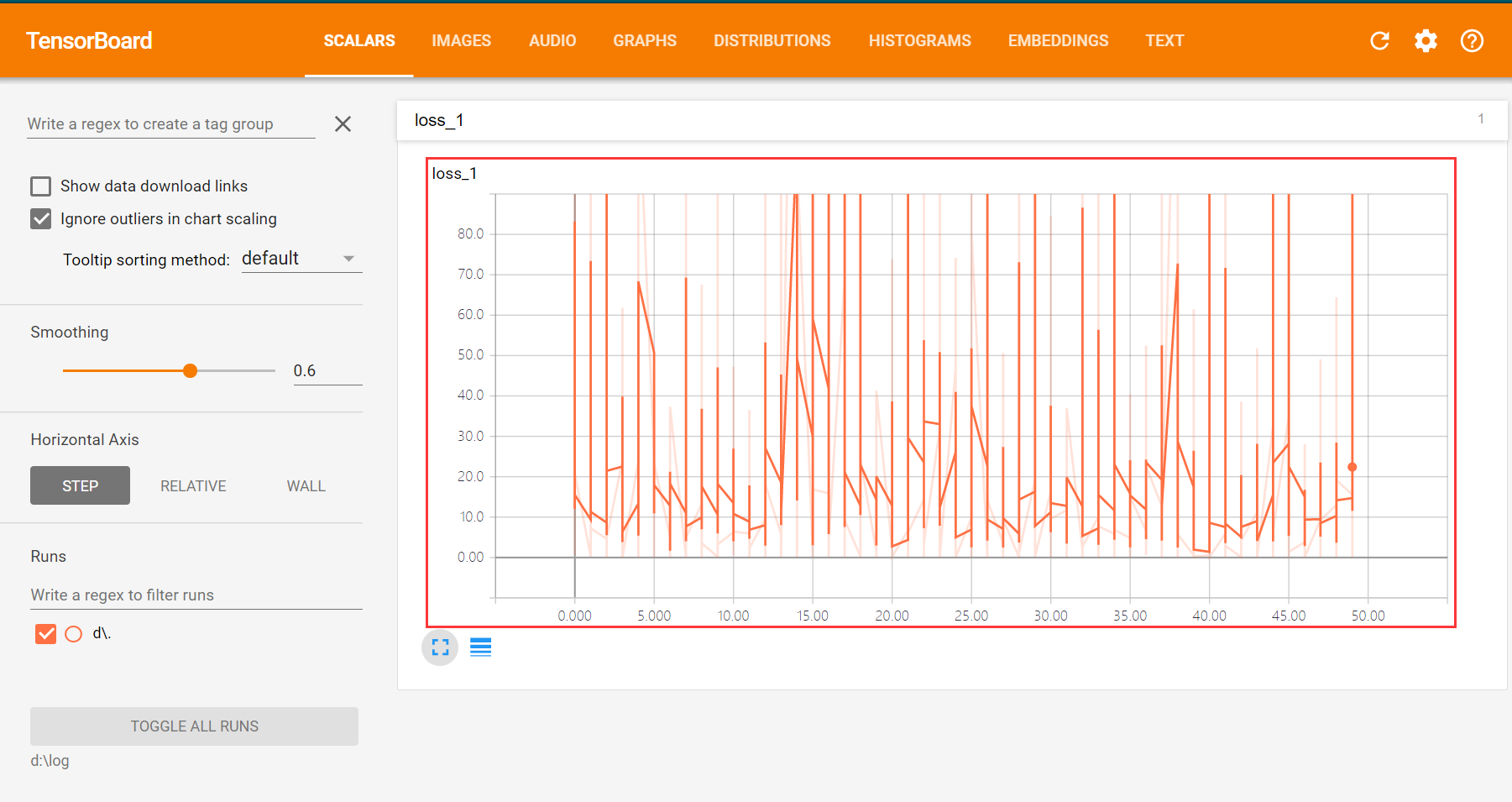
# 创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见 sum_loss_op = tf.summary.scalar("loss",loss_function)8.1.3把所有需要记录摘要日志文件得合并,方便一次性写入
#把所有需要记录摘要日志文件得合并,方便一次性写入 merged = tf.summary.merge_all()#启动会话 sess.run(init)8.1.4创建摘要得文件写入器(FileWriter)
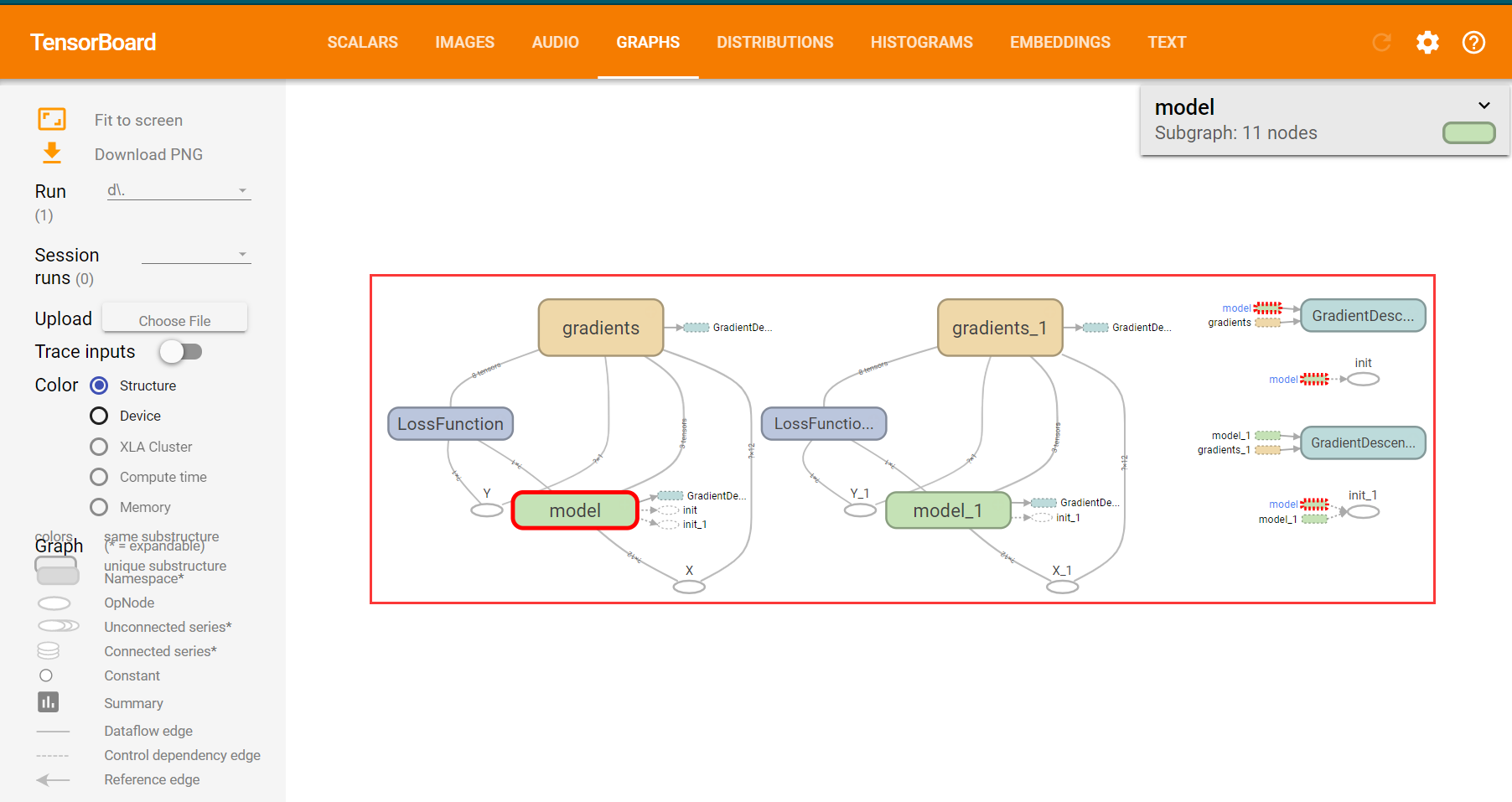
#创建摘要write,将计算图写入摘要,后面的在TensorBoard中GRAPHS可见 writer = tf.summary.FileWriter(logdir,sess.graph)8.1.5writer.add_summary(summary_str, epoch)
# 用于保存 loss值得列表 loss_list = [] #迭代训练 for epoch in range(train_epochs): loss_sum = 0.0 for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组 xs = xs.reshape(1,12) ys = ys.reshape(1,1) # Feed 数据必须和Placeholder 的shape 一致 _,summary_str,loss = sess.run([optimizer,sum_loss_op,loss_function],feed_dict={x:xs,y:ys}) writer.add_summary(summary_str,epoch) loss_sum = loss_sum + loss #打乱数据顺序 x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess) w0temp = w.eval(session=sess) loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8.2运行TensorBoard
8.2.1打开Anaconda Prompt
激活TensorFlow: Activate tensorflow 进入日志存储目录 : cd d:log 打开TensorBoard: tensorboard --logdir=d:log8.2.2TensorBoard 查看loss
8.2.3TensorBoard查看计算图