1 数组、字符串【Array、String】
1.1 字符串转化
数组和字符串是最基本的数据结构,在很多编程语言中都有着十分相似的性质,而围绕着它们的算法面试题也是最多的。
很多时候,在分析字符串相关面试题的过程中,我们往往要针对字符串当中的每一个字符进行分析和处理,甚至有时候我们得先把给定的字符串转换成字符数组之后再进行分析和处理。
举例:翻转字符串“algorithm”。
解法:用两个指针,一个指向字符串的第一个字符a,一个指向它的最后一个字符m,然后互相交换。交换之后,两个指针向中央一步步地靠拢并相互交换字符,直到两个指针相遇。这是一种比较快速和直观的方法。...
//翻转字符串“algorithm” int main() { char temp,a[] = "algorithm"; int i,j,length = strlen(a); temp = NULL; i = 0; j = length - 1; while(i != j) { temp = a[i]; a[i] = a[j]; a[j] = temp; i++; j--; } for(i = 0;i < length;i++) { printf("%c ",a[i]); } return 0; }1.2数组的优缺点
数组的优点在于:
构建非常简单
能在O(1)的时间里根据数组的下标(index)查询某个元素
而数组的缺点在于:
构建时必须分配一段连续的空间
查询某个元素是否存在时需要遍历整个数组,耗费 O(n) 的时间(其中,n 是元素的个数)
删除和添加某个元素时,同样需要耗费 O(n) 的时间
1.3【242】有效的字母异位词
2 链表(LinkedList)
单链表:链表中的每个元素实际上是一个单独的对象,而所有对象都通过每个元素中的引用字段链接在一起。
双链表:与单链表不同的是,双链表的每个结点中都含有两个引用字段。
2.1链表的优缺点
链表的优点如下:
链表能灵活地分配内存空间;
能在O(1)时间内删除或者添加元素,前提是该元素的前一个元素已知,当然也取决于是单链表还是双链表,在双链表中,如果已知该元素的后一个元素,同样可以在 O(1) 时间内删除或者添加该元素。
链表的缺点是:
不像数组能通过下标迅速读取元素,每次都要从链表头开始一个一个读取;
查询第 k 个元素需要 O(k) 时间。
2.2 应用场景
如果要解决的问题里面需要很多快速查询,链表可能并不适合;如果遇到的问题中,数据的元素个数不确定,而且需要经常进行数据的添加和删除,那么链表会比较合适。而如果数据元素大小确定,删除插入的操作并
不多,那么数组可能更适合。
2.3 经典解法
2.3.1 利用快慢指针(有时候需要用到三个指针)
典型题目例如:链表的翻转,寻找倒数第k个元素,寻找链表中间位置的元素,判断链表是否有环等等。
2.3.2 .构建一个虚假的链表头
一般用在要返回新的链表的题目中,比如,给定两个排好序的链表,要求将它们整合在一起并排好序。又比如,将一个链表中的奇数和偶数按照原定的顺序分开后重新组合成一个新的链表,链表的头一半是奇数,后一半是偶数。
在这类问题里,如果不用一个虚假的链表头,那么在创建新链表的第一个元素时,我们都得要判断一下链表的头指针是否为空,也就是要多写一条ifelse语句。比较简洁的写法是创建一个空的链表头,直接往其后面
添加元素即可,最后返回这个空的链表头的下一个节点即可。
建议:在解决链表的题目时,可以在纸上或者白板上画出节点之间的相互关系,然后画出修改的方法
2.4 【25】K个一组翻转链表
3 栈(Stack)
3.1 特点
栈的最大特点就是后进先出(LIFO)。对于栈中的数据来说,所有操作都是在栈的顶部完成的,只可以查看栈顶部的元素,只能够向栈的顶部压⼊数据,也只能从栈的顶部弹出数据。
3.2 实现
利用一个单链表来实现栈的数据结构。而且,因为我们都只针对栈顶元素进行操作,所以借用单链表的头就能让所有栈的操作在O(1)的时间内完成。
3.3 应用场景
在解决某个问题的时候,只要求关心最近一次的操作,并且在操作完成了之后,需要向前查找到更前一次的操作。
如果打算用一个数组外加一个指针来实现相似的效果,那么,一旦数组的长度发生了改变,哪怕只是在最后添加一个新的元素,时间复杂度都不再是 O(1),而且,空间复杂度也得不到优化。
3.4【20】有效的括号
3.5【739】每日温度
方法一:从左到右依次遍历 O(n^2)
针对每个温度值 向后进行依次搜索 ,找到比当前温度更高的值,这是最容易想到的办法。
其原理:从左到右除了最后一个数其他所有的数都遍历一次,最后一个数据对应的结果肯定是 0,就不需要计算。
遍历的时候,每个数都去向后数,直到找到比它大的数,数的次数就是对应输出的值。
#include <stdio.h> #include <stdlib.h> void dailyTemperatures(int* T, int TSize){ int i,j,result[TSize]; for(i = 0;i < TSize;i++) { int cur = T[i]; if(cur < 100) { for(j = i+1;j < TSize;j++) { if(T[j] > cur) { result[i] = j - i; break; } } if(j == TSize) result[i] = 0; } } for(i = 0;i < TSize;i++) { printf("%d ",result[i]); } } int main() { int length,T[] = {73, 65, 85, 71, 69, 72, 76, 79}; length = sizeof(T) / sizeof(T[0]); dailyTemperatures(T,length); return 0; }//LeetCode可以通过,但超时,因为时间复杂度为O(2^2) int* dailyTemperatures(int* T, int TSize,int* returnSize){ int i,j; int *result = malloc(sizeof(int)*TSize); //动态数组 *returnSize = TSize; for(i = 0;i < TSize;i++) { int cur = T[i]; if(cur <= 100) { for(j = i+1;j < TSize;j++) { if(T[j] > cur) { result[i] = j - i; break; } } //若之后不再升高,则为0 if(j == TSize) result[i] = 0; } } return result; }方法二:从右到左依次遍历
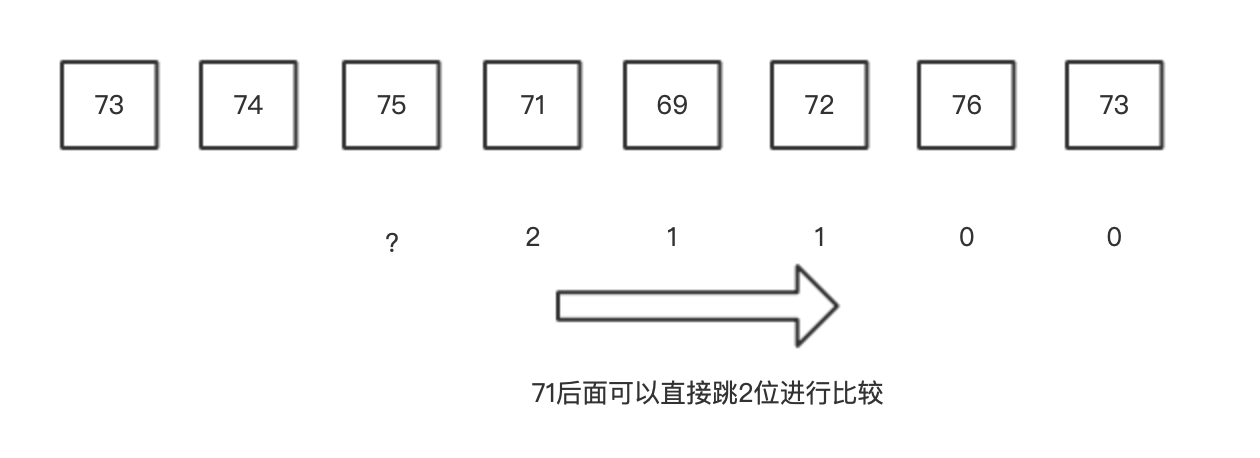
关键是要减少为每个数寻找值遍历次数。如下图所示,绿色部分区域会给多次遍历,如果我们能减少这部分区域的遍历次数,就能整体提高运算效率。
如果我们先从计算右边,那么我们计算过的位置就不需要重复计算,如图所示:
当前我们需要计算 7575 位置,然后向右遍历到 7171,因为我们已经计算好了 7171 位置对应的值为 22,那么我们就可以直接跳 22 为在进行比较,利用了已经有的结果,减少了遍历的次数。
#include <stdio.h> #include <stdlib.h> void dailyTemperatures(int* T, int TSize) { int i,j; int *result = malloc(sizeof(int)*TSize); //动态数组 //从右向左遍历 result[TSize - 1] = 0; //最后一个一定为0 for(i = TSize - 2; i >= 0; i--) { // j+= result[j]是利用已经有的结果进行跳跃 for(j = i+1; j < TSize; j+=result[j]) { if(T[j] > T[i]) { result[i] = j - i; break; } //遇到0表示后面不会有更大的值,那当然当前值就应该也为0 else if(result[j] == 0) { result[i] = 0; break; } } } for(i = 0; i < TSize; i++) { printf("%d ",result[i]); } } int main() { int length,T[] = {73, 65, 85, 71, 69, 72, 76, 79}; length = sizeof(T) / sizeof(T[0]); dailyTemperatures(T,length); return 0; }
方法三:堆栈 O(n)
可以运用一个堆栈 stack 来快速地知道需要经过多少天就能等到温度升高。从头到尾扫描一遍给定的数组 T,如果当天的温度比堆栈 stack 顶端所记录的那天温度还要高,那么就能得到结果。
正序遍历版本
- 对第一个温度23度,堆栈为空,把它的下标压入堆栈;
- 下一个温度24度,高于23度高,因此23度温度升高只需1天时间,把23度下标从堆栈里弹出,把24度下标压入;
- 同样,从24度只需要1天时间升高到25度;
- 21度低于25度,直接把21度下标压入堆栈;
- 19度低于21度,压入堆栈;
- 22度高于19度,从19度升温只需1天从 21 度升温需要 2 天;
- 由于堆栈里保存的是下标,能很快计算天数;
- 22 度低于 25 度,意味着尚未找到 25 度之后的升温,直接把 22 度下标压入堆栈顶端;
- 后面的温度与此同理。
该方法只需要对数组进行一次遍历,每个元素最多被压入和弹出堆栈一次,算法复杂度是 O(n)。
#include <stdio.h> #include <stdlib.h> int dailyTemperatures(int* T, int TSize) { int *result = (int *)malloc(sizeof(int)*TSize); //动态数组 int stack[TSize]; //数组模拟堆栈 int i,top = -1; //top为 栈顶指针 // result数组赋初值 for(i = 0;i < TSize;i++) { result[i] = 0; } //正序遍历 for (i = 0; i < TSize; ++i) { if (top > -1 && T[i] > T[stack[top]]) { while (top > -1 && T[i] > T[stack[top]]) { result[stack[top]] = i - stack[top]; top--; } } stack[++top] = i; } //打印数组 for(i = 0; i < TSize; i++) { printf("%d ",result[i]); } } int main() { int length,T[] = {73, 74, 75, 71, 69, 72, 76, 73}; length = sizeof(T) / sizeof(T[0]); dailyTemperatures(T,length); return 0; }倒序遍历版本
#include <stdio.h> #include <stdlib.h> void dailyTemperatures(int* T, int TSize) { int *result = (int *)malloc(sizeof(int)*TSize); //动态数组 int stack[TSize]; //数组模拟堆栈 int i,top = -1; //top为 栈顶指针 // result数组赋初值 for(i = 0;i < TSize;i++) { result[i] = 0; } //倒序遍历 for (i = TSize - 1; i > -1; --i) { while (top > -1 && T[i] >= T[stack[top]]) { top--; } if (top > -1) { result[i] = stack[top] - i; } stack[++top] = i; } //打印数组 for(i = 0; i < TSize; i++) { printf("%d ",result[i]); } } int main() { int length,T[] = {73, 65, 85, 71, 69, 72, 76, 79}; length = sizeof(T) / sizeof(T[0]); dailyTemperatures(T,length); return 0; }利用堆栈,还可以解决如下常见问题:
- 求解算术表达式的结果(LeetCode 224、227、772、770)
- 求解直方图里最大的矩形区域(LeetCode 84)
4 队列(Queue)
4.1 特点
和栈不同,队列的最大特点是先进先出(FIFO),就好像按顺序排队一样。对于队列的数据来说,我们只允许在队尾查看和添加数据,在队头查看和删除数据。
4.2 实现
可以借助双链表来实现队列。双链表的头指针允许在队头查看和删除数据,而双链表的尾指针允许我们在队尾查看和添加数据。
4.3 应用场景
直观来看,当我们需要按照一定的顺序来处理数据,而该数据的数据量在不断地变化的时候,则需要队列来帮助解题。在算法面试题当中,广度优先搜索(Breadth-First Search)是运用队列最多的地方
5 双端队列(Deque)
5.1特点
双端队列和普通队列最大的不同在于,它允许我们在队列的头尾两端都能在O(1)的时间内进行数据的查看、添加和删除。
5.2实现
与队列相似,我们可以利用一个双链表实现双端队列。
5.3 应用场景
双端队列最常用的地方就是实现一个长度动态变化的窗口或者连续区间,而动态窗口这种数据结构在很多题目里都有运用。
5.4 【239】 滑动窗口最大值
方法一:暴力法
直觉:
最简单直接的方法是遍历每个滑动窗口,找到每个窗口的最大值。一共有 N - k + 1 个滑动窗口,每个有 k 个元素,于是算法的时间复杂度为 {O}(N k)O(Nk),表现较差。
复杂度分析:
时间复杂度:{O}(N k)O(Nk)。其中
N为数组中元素个数。空间复杂度:{O}(N - k + 1)O(N−k+1),用于输出数组。
实现:
//LeetCode int* maxSlidingWindow(int* nums, int numsSize, int k, int* returnSize) { int *result = (int*)malloc(sizeof(nums[0])*(numsSize-k+1)); //动态数组 int i,j; //如果长度小于1,或者k值小于0,或者数组为空,返回NULL if (!nums || numsSize < 1 || k <= 0) { *returnSize = 0; return NULL; } //一共有 N - k + 1 个滑动窗口,每个有 k 个元素 for(i = 0; i < numsSize-k+1; i++) { // max记录最大值 int max =nums[i]; for(j = i; j < i+k; j++) { if(max < nums[j]) { max = nums[j]; } result[i] = max; } } *returnSize = numsSize-k+1; return result; }#include <stdio.h> #include <stdlib.h> int maxSlidingWindow(int* nums, int numsSize, int k) { int *result = (int*)malloc(sizeof(nums[0])*(numsSize-k+1)); int i,j; //如果长度小于1,或者k值小于0,或者数组为空,返回NULL if (!nums || numsSize < 1 || k <= 0) { return NULL; } for(i = 0; i < numsSize-k+1; i++) { int max =nums[i]; for(j = i+1; j < i+k; j++) { if(max < nums[j]) { max = nums[j]; } result[i] = max; } } for(i = 0; i < numsSize-k+1; i++) { printf("%d ",result[i]); } return 0; } int main() { int k,length,nums[] = {1, 3, -1, -3, 5, 3, 6, 7}; length = sizeof(nums) / sizeof(nums[0]); printf("请输入K值:"); scanf("%d",&k); maxSlidingWindow(nums,length,k); return 0; }
方法二:双向队列
直觉:
如何优化时间复杂度呢?首先想到的是使用堆,因为在最大堆中 heap[0] 永远是最大的元素。在大小为 k 的堆中插入一个元素消耗 log(k) 时间,因此算法的时间复杂度为 O(Nlog(k))。
能否得到只要 O(N) 的算法?
双向队列
该数据结构可以从两端以常数时间压入/弹出元素。
双端队列和普通队列最大的不同在于,它允许我们在队列的头尾两端都能在 O(1) 的时间内进行数据的查看、添加和删除。
与队列相似,我们可以利用一个双链表实现双端队列。双端队列最常用的地方就是实现一个长度动态变化的窗口或者连续区间,而动态窗口这种数据结构在很多题目里都有运用。
算法:
- 处理前 k 个元素,初始化双向队列。
- 遍历整个数组。在每一步 :
清理双向队列 :
- - 只保留当前滑动窗口中有的元素的索引
- - 移除比当前元素小的所有元素,它们不可能是最大的。
- 将当前元素添加到双向队列中。
- 将 deque[0] 添加到输出中。
- 返回输出数组。

这道题而言,既然每次都要在一个移动的窗口中找到最大值,那很简单,我们就移动这个窗口,然后扫描一遍窗口获得最大值。假设数组里有 nn 个元素,这样的算法复杂度就是 O(n∗k)。
那么我们能不能在移动窗口的过程中,更快地获得最大值呢?
可以利用一个双端队列来表示这个窗口。这个双端队列保存当前窗口中最大那个数的下标,双端队列新的头总是当前窗口中最大的那个数。
同时,有了这个下标,我们可以很快地知道新的窗口是否已经不再包含原来那个最大的数,如果不再包含,我们就把旧的数从双端队列的头删除。按照这样的操作,不管窗口的长度是多长,因为数组里的每个数都分别被压入和弹出双端队列一次,所以我们可以在 O(n) 的时间里完成任务。//LeetCode int* maxSlidingWindow(int* nums, int numsSize, int k, int* returnSize) { int *result = (int*)malloc(sizeof(nums[0])*(numsSize-k+1)); //动态数组 int i=0; //如果长度小于1,或者k值小于0,或者数组为空,返回NULL if (!nums || numsSize < 1 || k <= 0) { *returnSize = 0; return NULL; } // 队列 int *queue = (int*)malloc(sizeof(int) * numsSize); int front, rear; front = rear = 0; // 模拟双端队列 while(i < numsSize) { // 队尾元素 < 未入队元素 , 弹出队尾元素 while (front != rear && nums[queue[rear - 1]] < nums[i]) --rear; // 新元素入队 queue[rear++] = i; // 开始滑动窗口 if(i >= k - 1){ // 当前窗口最大值加入结果 result[i - k + 1] = nums[queue[front]]; // 队头元素出窗(出队) if(front != rear && queue[front] <= i - k + 1) ++front; } ++i; } free(queue); *returnSize = numsSize-k+1; return result; }#include <stdio.h> #include <stdlib.h> int maxSlidingWindow(int* nums, int numsSize, int k) { int *result = (int*)malloc(sizeof(nums[0])*(numsSize-k+1)); int i=0; //如果长度小于1,或者k值小于0,或者数组为空,返回NULL if (!nums || numsSize < 1 || k <= 0) { return NULL; } // 队列 int *queue = (int*)malloc(sizeof(int) * numsSize); int front, rear; front = rear = 0; // 模拟双端队列 while(i < numsSize) { // 队尾元素 < 未入队元素 , 弹出队尾元素 while (front != rear && nums[queue[rear - 1]] < nums[i]) --rear; // 新元素入队 queue[rear++] = i; // 开始滑动窗口 if(i >= k - 1){ // 当前窗口最大值加入结果 result[i - k + 1] = nums[queue[front]]; // 队头元素出窗(出队) if(front != rear && queue[front] <= i - k + 1) ++front; } ++i; } free(queue); for(i = 0; i < numsSize-k+1; i++) { printf("%d ",result[i]); } return 0; } int main() { int k,length,nums[] = {1, 3, -1, -3, 5, 3, 6, 7}; length = sizeof(nums) / sizeof(nums[0]); printf("请输入K值:"); scanf("%d",&k); maxSlidingWindow(nums,length,k); return 0; }6 树(Tree)
6.1树的概念
定义都有一个相同的特点:递归,也就是说,一棵树要满足某种性质,往往要求每个节点都必须满足。例如,在定义一棵二叉搜索树时,每个节点也都必须是一棵二叉搜索树。
正因为树有这样的性质,大部分关于树的面试题都与递归有关,换句话说,面试官希望通过一道关于树的问题来考察你对于递归算法掌握的熟练程度。树的形状在面试中常考的树的形状有:
普通二叉树、
平衡二叉树、
完全二叉树、
二叉搜索树、
四叉树(Quadtree)、
多叉树(N-aryTree)。
对于一些特殊的树,例如红黑树(Red-BlackTree)、自平衡二叉搜索树(AVLTree),一般在面试中不会被问到,除非你所涉及的研究领域跟它们相关或者你十分感兴趣,否则不需要特别着重准备。
6.2树的遍历
6.2.1.前序遍历(PreorderTraversal)
方法:先访问根节点,然后访问左子树,最后访问右子树。在访问左、右子树的时候,同样,先访问子树的根节点,再访问子树根节点的左子树和右子
树,这是一个不断递归的过程。
应用场景:运用最多的场合包括在树里进行搜索以及创建一棵新的树。
6.2.2. 中序遍历(Inorder Traversal)
方法:先访问左子树,然后访问根节点,最后访问右子树,在访问左、右子树的时候,同样,先访问子树的左边,再访问子树的根节点,最后再访问子树的右边。
应用场景:最常见的是二叉搜素树,由于二叉搜索树的性质就是左孩子小于根节点,根节点小于右孩子,对二叉搜索树进行中序遍历的时候,被访问到的节点大小是按顺序进行的。
6.2.3. 后序遍历(Postorder Traversal)
方法:先访问左子树,然后访问右子树,最后访问根节点。
应用场景:在对某个节点进行分析的时候,需要来自左子树和右子树的信息。收集信息的操作是从树的底部不断地往上进行,好比你在修剪一棵树的叶子,修剪的方法是从外面不断地往根部将叶子一片片地修剪掉。
6.3 【230】二叉搜索树中第K小的元素
解题思路:
这道题考察了两个知识点:
二叉搜索树的性质
二叉搜索树的遍历
二叉搜索树的性质:对于每个节点来说,该节点的值比左孩子大,比右孩子小,而且一般来说,二叉搜索树里不出现重复的值。
二叉搜索树的中序遍历是高频考察点,节点被遍历到的顺序是按照节点数值大小的顺序排列好的。即,中序遍历当中遇到的元素都是按照从小到大的顺序出现。
因此,我们只需要对这棵树进行中序遍历的操作,当访问到第 k 个元素的时候返回结果就好。
参考:二叉排序树的建立
方法一:中序遍历
我们只需要增加两个变量 num 和 res。num 记录中序遍历已经输出的元素个数,当 num == k 的时候,我们只需要将当前元素保存到 res 中,然后返回即可。
//中序遍历 void inorder(struct TreeNode *root,int *num,int m,int *res) { if(root == NULL) { return; } inorder(root ->left,num,m,res); (*num)++; if(*num == m) { *res = root ->val; return; } if(*num > m) { return; } inorder(root ->right,num,m,res); } int kthSmallest(struct TreeNode* root, int k){ int num = 0,res = 0; inorder(root,&num,k,&res); return res; }