一、activemq
虽然是java写的消息队列,但是提供Java, C, C++, C#, Ruby, Perl, Python, PHP各种客户端,所以语言上是没什么问题的。配置和使用,基本上是java xml这一套。同时对jms、spring之类的支持很友好。
而且因为是Java写的,所以可以作为一个jar包,放到java项目里,用代码启动和配置,这个对于java开发者而言是不是相当爽?毕竟还是有些场景,需要我们把队列放到自己项目内部,随项目启动而启动的。而且,还可以类似拓展tomcat一样,自己写java的plugin来拓展activemq。比如说,我有10万硬件连到mq上,这10万设备每个都有用户名密码,这个时候我们可以用java写个权限验证,从数据库里查这10万用户名密码。
activemq支持主从复制、集群。但是集群功能看起来很弱,只有failover功能,即我连一个失败了,可以切换到其他的broker上。这一点貌似不太科学。假设有三个broker,其中一个上面没有consumer,但另外两个挂了,消息会转到这个上面来,堆积起来。看样子activemq还在升级中。
activemq工作模型比较简单。只有两种模式 queue,topics 。
queue就多对一,producer往queue里发送消息,消费者从queue里取,消费一条,就从queue里移除一条。如果一个消费者消费速度不够快怎么办呢?在activemq里,提供messageGroup的概念,一个queue可以有多个消费者,但是他们得标记自己是一个messageGroup里的。这样,消息会轮训发送给每个消费者,也就是说消费者不会重复消费同一条消息。但是每条消息只被消费一次。
topics就是广播。producer往broker发消息,每个消息包含topic。消费者订阅感兴趣的topic,所有订阅了topic的消费者都会收到消息。当然订阅分持久不持久。持久订阅,当消费者断开一会,再连上来,仍然会把没收到的消费发过来。不持久的订阅,断开这段时间的消息就收不到了。
activemq支持mqtt、ssl。
二、rabbitmq
rabbitmq用erlang写的。安装完才10m不到,在windows上使用也非常方便,在这点上完爆了activemq,java又臭又长没办法啊。rabbitmq给我感觉更像oracle,功能非常强大。安装完,也有实例的概念,可以像建数据库一样,建实例,建用户划权限。同时监控系统也很好用。这些都是好处,同时也是累赘,整体上来说rabbitmq比activemq复杂太多了。
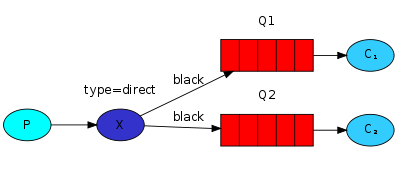
从机制上来讲,rabbitmq也有queue和topic的概念,发消息的时候还要指定消息的key,这个key之后会做路由键用。但是,多了一个概念叫做交换器exchange。exchange有四种,direct、fanout、topic、header。也就是说,发消息给rabbitmq时,消息要有一个key,并告诉他发给哪个exchange。exchange收到之后,根据key分发或者广播给queue。消费者是从queue里拿消息的,并接触不到交换机。
在rabbitmq里,有各种默认行为,如果我们不指定exchange,会有个默认的direct类型的exchange,如果不指定队列和交换器的绑定关系,默认就按消息的key绑定对应的queue。此时发一个消息,消息的key是什么,就会被默认交换器送给对应的queue。
此时,其实等同于activemq的queue模式。
在rabbitmq里,一个queue可以有多个消费者

通过设置prefetch的值为1,可以让多个消费者每次都取到一条记录,消费完再取下一条。这两种都是使用direct交换器,即消息的key是多少,就把消息放到key对应的queue中。
fanout交换器。实际上就是广播,发送到fanout交换器的消息,会被转发给所有和这个交换器绑定的队列。通常我们把队列搞成临时的,这样就解耦了。例如用户登录,发送一个登陆消息到fanout交换器,同时有一个smsQueue和交换器绑定,一个消费者从这个smsQueue里取出谁登陆了,并发送一条短信。过了几天,我们希望用户登陆可以获得积分。那么我再声明一个scoreQueue绑定到这个fanout交换器,实现积分更改逻辑。下图是fanout(X为交换器)

总体说来fanout其实就是direct交换器实现的。把两个队列都绑定到direct,绑定的时候指定同一个key,就变成fanout交换器了,如下图
queue和exchange绑定的时候,也可以指定多个绑定key,这时候就实现了简单版的订阅。如下图

当然这样不够灵活,我想要靠通配符绑定如何呢,这时候就不用direct交换器了,用topic交换器
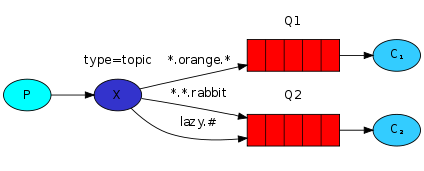
“#”通配剩余字符,"*"通配部分字符。 如果绑定的时候key为“#”,那么其实就是fanout交换器。如果一个通配符都没有,其实就是direct交换器。
head交换器貌似是通过消息附带的头信息来路由的,不过官方对这个介绍的少之又少,平时也应该没什么人用,死信队列貌似依赖于这个。
通过交换器的概念,rabbitmq在机制上要比activemq灵活不少。对于activemq来说,你要么是个queue的消费者,要么是个topic的订阅者。你要同时订阅多个topic,要自己在消费者端写代码来实现。在rabbitmq中,你只是queue的消费者,至于你这个queue的消息是从哪个topic来,或者从哪里直接发过来,这个和消费者没有关系,而且queue里的消息从哪来可以在rabbitmq里动态配置。所以灵活度得到了提升。
rabbitmq同样也支持主从复制和集群。但是rabbitmq的集群非常多样化,而且需要至少一台机器做为磁盘节点,可以持久化queue和exchange的信息,其他的可以为内存节点。普通集群中,只有exchange,queue这些定义是分布在所有机器上的,而queue中的数据不是冗余的,比如有三台rabbitmq组成了集群,他们共享同样的exchange,queue,但是一条消息数据落到了第一台机器上,另外两台实际上没有这条数据的。 对于整个集群的使用,这样其实没有任何问题。 但出于高可用的角度来想,还是需要完完全全的分布式集群的,万一中间有数据这台机器挂了? rabbitmq对此也有支持,把队列数据也冗余存到三台机器上,称之为镜像队列,但性能要比普通集群低,毕竟一条消息被复制到其他机器上是耗时的事情。
rabbitmq以plugin的形式支持mqtt,和spring整合也非常简单。
三、kafka
kafka号称为分布式而生。和activemq以及rabbitmq这些企业级队列而言确实更有分布式系统的优势。

kafka中,只有topic,但是每个topic可以有很多partition分区。上图中kafka集群由两台机器组成。topic被分成四个分区,server1维护p0,p3。 在kafka中,每个消费者都要指出自己属于哪个consumerGroup,每个consumer可以读取多个partition。但是一个partition在同一个consumerGroup中,只会被一个consumer消费。以此保证不会重复消费。而且在一个partition中,消息被消费的顺序是可保障的。上图中,consumer group A 由两个consumer组成,因此一个consumer可以消费两个partition。如果要保证严格的顺序性,那么就要像consumer group B一样,每个consumer只消费一个partition。kafka和rabbitmq及activemq机制上略有区别。rabbitmq和activemq都是消费后就删除消息,没有重复消费的功能,而kafka 队列中的内容按策略存储一定时间,消费者通过指定偏移量来读取数据。如果使用基础api可以从任意位置读取。kafka同时提供高级api,即kafka来维护每个消费者当前读到什么位置了,下次再来,可以接着读。

kafka中partition是冗余存储的。如果一个partition不幸挂了,通过选主,马上可以切换到另外一台机器上继续使用。这一点上,是当之无愧的分布式队列。相比之下,rabbitmq需要配置镜像队列,操作太麻烦。kafka搭建集群也是非常简单。
kafka的优势在于: 传统的消息队列只有两种模式,要么是queue,要么是publish-subscribe发布订阅。在queue模式中,一组消费者消费一个队列,每条消息被发给其中一个消费者。在publish-subscribe模式中,消费被广播给所有消费者。queue模式的好处在于,他可以把消费分发给一组消费者,从而实现消费者的规模化(scale);问题在于,这样一个消息只能被一组消费者消费,一旦消费,消息就没有了。publish-subscribe的好处在于,一个消息可以被多组消费者消费;问题在于,你的消费者没法规模化,即不可能出现多个消费者订阅同一个topic,但每个消费者只处理一部分消息(虽然这个可以通过设计topic来解决)。
kafka的设计意义在于,大家都publish-subscribe,因为我的队列数据是不删除的,多个subscriber可以订阅同一个topic,但是各自想从哪读,从哪读,互不干扰。同时提出了consumer group的概念。每个subscriber可以是多个consumer组成的,在consumer group内部,你们自己分配,不要两个人消费同一条数据。为了达到这种目的,一个topic里的消息,被分成多个partition,既实现了上面的想法,同时又冗余(一个partition可以冗余存储在多台机器上),达到分布式系统的高可用效果。
kafka也支持mqtt,需要写一个connecter。kafka还提供流式计算的功能,做数据的初步清理还是很方便的。
总体而言。我感觉kafka安装使用最简单,同时,如果有集群要求,那么kafka是当仁不让的首选。尤其在海量数据,以及数据有倾斜问题的场景里,因为partition的缘故,数据倾斜问题自动解决。比如个别Topic的消息量非常大,在kafka里,调整partition数就好了。反而在rabbitmq或者activemq里,这个不好解决。
rabbitmq是功能最丰富,最完善的企业级队列。基本没有做不了的,就算是做类似kafka的高可用集群,也是没问题的,不过安装部署麻烦了点。
activemq相对来说,显的老套了一些。不过毕竟是java写的,在内嵌到项目中的情况下,或者是简单场景下,还是不错的选择。
补充一下。在kafka中,创建一个topic是一个比较重的操作,因为是分布式的,topic要同步到其他的broker,中间还要经过zookeeper。所以kafka仅仅做mqtt的输入是ok的,但是你需要给每个硬件推送消息,实际上不太好。这方面反倒是rabbitmq比较好,因为在rabbitmq中创建几万的topic是很容易的,所以是可以做到每个硬件订阅不同的topic。