人工智能的一个基本问题是它无法像人类一样高效地学习。许多深度学习分类器显示了超人的表现,但需要数百万个训练样本。知识不共享,并且每个任务都独立于其他任务进行训练。在本文中,我们将该研究问题,然后检查一些建议的解决方案。
问题
与人类相比,大多数最先进的深度学习方法都有两个关键的弱点:
- 样本效率:深度学习的样本效率很差。例如,为了识别数字,我们通常每个数字需要6000个样本。
- 可移植性差。我们不会从以前的经验或学到的知识中学习。
元学习
那么什么是元学习?我们试图将其定义为“学习如何学习”。但是实际上,我们还不知道确切的定义或解决方案。因此,它仍然是一个宽松的术语,指的是不同的方法。在本文中,我们将重点关注以下领域:
- 循环模型
- 元优化
- 度量学习
少量学习(Few-Shot)
但让我们先定义一些基本概念。在CIFAR-10,我们有10个不同类别的60000张图片。换句话说,我们有10个分类任务,每个分类任务有6000个训练样本。在少样本学习中,我们训练的模型包含大量的任务,但每个任务只有一个或几个样本。我们的最终目标是将知识一般化,并将其应用到我们从未训练过的新任务中。
例如,在任务1中,我们被要求学习3个表情符号。然后,用一个新的表情符号,我们通过训练模型把它和之前的一个样本联系起来。

在我们的第二个任务中,我们用字母训练它。

我们用不同的任务重复这个过程很多次。一旦训练完成,我们通过测试一个我们以前没有执行过的任务来测量模型的通用性,识别汉字。该模型可以正确地将测试样本与输入关联起来。

我们可能想知道Few-Shot训练和使用大数据集的传统DL之间的区别。在DL中,我们使用正则化来确保我们没有用一个小数据集过拟合我们的模型。但是通过使用这么多的样本和迭代来训练模型,我们在我们的任务过拟合了。我们所学到的东西不能推广到其他任务上。
让我来演示一下DL中的一些问题。当我们测试数据集中不常见的样本时,我们经常会陷入困境。例如,在玩具分类中,如下图所示,黄色的玩具鸭分类很差。在Few-Shot训练中,关键的目标是处理我们以前没有训练过的数据。

在One-Shot训练中,我们只会为每个类别提供一个训练样本。在下面的示例中,训练包含多个数据集。每个数据集包含一个1-shot-5类的分类任务,即来自5个不同类的5个样本。

在这种One-Shot训练中,我们经常训练一个RNN来学习训练数据和标签。当我们用一个测试输入表示时,我们应该正确地预测它的标签。

在元测试中,我们再次使用以前从未训练过的类来提供数据集。在这个例子中,元学习的重点是学习对象分类的秘密。一旦我们学习了上百个任务,我们就不应该只关注单个的类。相反,我们应该发现对象分类的一般模式。因此,即使我们面对的是从未见过的类,我们也应该设法解决这个问题。
如果我们更聪明地收集任务,我们会学得更好。
Omniglot
在我们讨论细节之前。让我们介绍Omniglot。它是一个流行的Few-Shot学习数据集。以下是来自Omniglot的20幅代表不同的20个类的画。

循环模型
第一种元学习方法是循环模型。我们将数据输入到一个类似于rnn的模型中,以记住我们目前看到的情况。当我们面对一个测试输入时,我们从记忆中回忆它是什么。然而,我们没有足够的内存来容纳我们所看到的一切。循环模型存储特征,我们使用类似于word-embedding来关联信息。

让我们先回顾一下内存网络(MN)。MN使用一个控制器从输入中提取特征。然后我们使用这些特征来访问内存。

例如,你接了一个电话,但你不能立即识别声音。这个声音听起来很像你的堂兄(概率0.7),但也很像你哥哥(概率0.3)的声音。在上图中,每一行代表一个对象。我们计算每一行的权值w来衡量它与输入的相关性。然后,我们计算所有行的加权和,以回忆与该输入相关的内存。在我们的例子中,这个权重和指的是一个同学。

记忆增强神经网络是利用RNN作为外部记忆网络的元学习方法之一。在监督学习中,我们在同一时间步t中提供输入和标签。但是,在这个模型中,标签直到下一次时间戳t 1才被提供(如下图所示)。这是一种阻止RNN单元将输入直接映射到类标签的技术。我们希望我们的模型记住经验。

训练记忆增强神经网络

在记忆增强神经网络中,我们使用外部存储器来存储样本表示和类标签信息。通常作为LSTM实现的控制器从输入中生成一个键,该键要么存储在外部内存中,要么用于检索特定的内存。然后用反向传播对整个系统进行训练。具体建议读者阅读原始论文。

如果我们能从经验中学习,我们会学得更好。
学习优化器
在第二种元学习方法中,我们试图更有效地优化模型。在每个任务的训练之后,我们可以使用这些信息来更新模型。
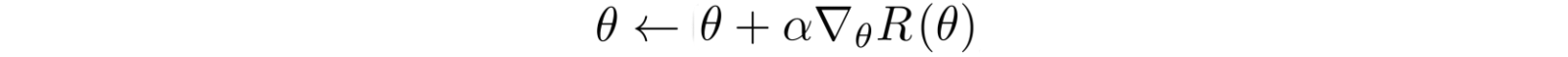
然而,我们正在学习一个特定的任务,而不是找到所有学习任务背后的基础知识。因此,我们不是立即更新模型,而是等待一批任务完成。稍后,我们将从这些任务中学到的所有知识合并到一个更新中。这种方法实现了“学我们所学(learn what we learn)”的概念。

模型无关元学习(MAML)利用上面的概念来更新模型。它是简单的,它几乎是相同的,我们的传统DL梯度下降与增加一行代码如下。在这里,我们不会在每个任务之后立即更新模型参数。相反,我们一直等到一批任务完成


对于每个任务,我们使用反向传播来计算建议的模型。

然后合并训练任务的损耗,并将损耗进行反向传播,进行下一次模型更新:

从概念上讲,我们正在寻找一个最小化任务损失的模型。

从图形上看,每个任务可以将模型参数驱动到不同的方向。通过引入元学习步骤和少样本数据集,我们学习了一个只处理任务而不处理样本的模型。
还有其他一些优化器的目标是更有效地学习。例如,OpenAI提出了另一个名为Reptile的优化器。在随机梯度下降法中,我们计算一个梯度下降并更新模型。然后我们为下一次迭代获取下一批数据。在Reptile中,它对每个任务执行多步梯度下降,并使用最后一步的结果更新模型,使用与运行平均值类似的概念。

在OpenAI的论文中,它从数学上论证了为什么MAML和Reptile的行为相似。
我们建议你们阅读原始的论文。
如果我们优化得更好,我们就学得更好。
度量学习
我们将讨论的第三种元学习方法是度量学习。你还记得逐像素的图片吗?不。为了学习,我们需要用最少的内存获取最多的信息。因此,第三种元学习方法关注的是我们如何提取特征,但不要过度提取。在Siamese神经网络中(如下图所示),我们使用两个具有相同模型参数值的相同网络来提取两个样本的特征。然后将提取出的特征输入鉴别器,判断两个样本是否属于同一类对象。例如,我们可以计算其特征向量的余弦相似度§。如果它们相似,p应该接近1。否则,它们应该接近0。根据样本的标签和p,我们对网络进行相应的训练。简而言之,我们希望找到使样例属于同一类或将它们区分开来的特性。

还有一种方法叫做Matching网络,它与Siamese神经网络非常相似。

g和f是特征提取器,使用深度来提取特征,用于我们的输入和测试样本。通常,g和f是相同的,共享相同的深度网络。然后我们比较它们的相似度,并使用一个softmax函数来计算它们是否相似。同样,我们从预测中计算一个成本函数来训练我们的特征提取器。以下是数学公式:
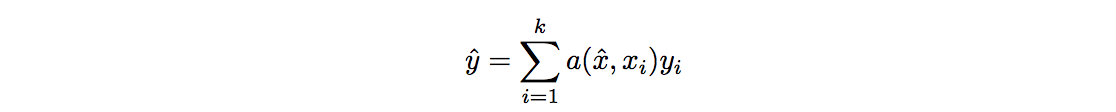
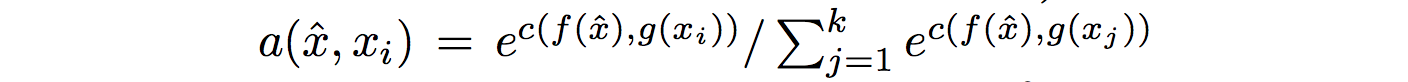

如果我们知道如何更好地表示数据,我们就学得更好。
其他方法
还有其他元学习方法关注于如何使用更好的超参数优化模型。例如,学习如何巧妙地调整超参数。或者,我们可以结合DL层来动态地形成一个新的模型。

这些方法使模型更准确,但不一定更有效的学习较少的样本。所以我们不会在元学习的讨论中进一步讨论。
想法
学习如何更好地学习不仅是对机器的挑战,也是对人类的挑战。元学习已经被研究了几十年,但是我们还没有完全理解它是如何实现的。为了结束我们的思想,这里是目前提高学习效率相关的研究领域。
- 收集更好的信息来学习。
- 更好地从过去的经验中学习。
- 更好地知道如何表示信息。
- 如何更好地优化模型。
- 探索更好的方法。
- 将联系变得更好。
- 将泛化变得更好。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/
OpenCV中文官方文档:
http://woshicver.com/