概述
- 数据正以前所未有的速度与日俱增
- 如何存储、处理和使用这些数据来进行机器学习?spark正可以应对这些问题
- 了解Spark是什么,它是如何工作的,以及涉及的不同组件是什么
简介
我们正在以前所未有的速度生成数据。老实说,我跟不上世界各地里产生的巨大数据量!我敢肯定你已经了解过当今时代数据的产量。McKinsey, Gartner, IBM,等公司都给出了他们公司的数据。
这里有一些令人难以置信的数字供你参考。有超过5亿条推文、900亿封电子邮件、6500万条WhatsApp消息,以上这些都是在一天之内发送的!Facebook在24小时内能生成4PB的数据。这是难以置信的!
当然,这也带来了挑战。一个数据科学团队如何捕获这么多的数据?你如何处理它并从中建立机器学习模型?如果你是一名数据科学家或数据工程师,这些都是令人兴奋的问题。
Spark正能应对这些问题。Spark是用Scala编写的,它提供了Scala、JAVA、Python和R的接口. PySpark一起工作的API。PySpark是用Python编写的Python API用来支持Spark的。

处理大数据的一种传统方式是使用像Hadoop这样的分布式框架,但这些框架需要在硬盘上执行大量的读写操作。事实上时间和速度都非常昂贵。计算能力同样是一个重要的障碍。
PySpark以一种高效且易于理解的方式处理这一问题。因此,在本文中,我们将开始学习有关它的所有内容。我们将了解什么是Spark,如何在你的机器上安装它,然后我们将深入研究不同的Spark组件。本文附有代码。
目录
- Spark是什么?
- 在你的计算机上安装Apache Spark
- 什么是Spark应用程序?
- 什么是Spark会话?
- Spark的分区
- 转换
- 惰性计算
- Spark中的数据类型
Spark是什么?
Apache Spark是一个开源的分布式集群计算框架,用于快速处理、查询和分析大数据。
它是当今企业中最有效的数据处理框架。使用Spark的成本很高,因为它需要大量的内存进行计算,但它仍然是数据科学家和大数据工程师的最爱。在本文中,你将看到为什么会出现这种情况。

通常依赖于Map-Reduce的框架的组织现在正在转向Apache Spark框架。Spark执行内存计算,比Hadoop等Map Reduce框架快100倍。Spark在数据科学家中很受欢迎,因为它将数据分布和缓存放入了内存中,并且帮助他们优化大数据上的机器学习算法。
我建议查看Spark的官方页面,了解更多细节。它有大量的文档,是Spark很好参考教程:https://spark.apache.org/
在你的计算机上安装Apache Spark
1. 下载Apache Spark
安装Spark的一个简单方法是通过pip。但是,根据Spark的官方文档,这不是推荐的方法,因为Spark的Python包并不打算取代所有其他情况。
在实现基本功能时,你很可能会遇到很多错误。它只适用于与现有集群(独立的Spark、YARN或Mesos)进行交互。
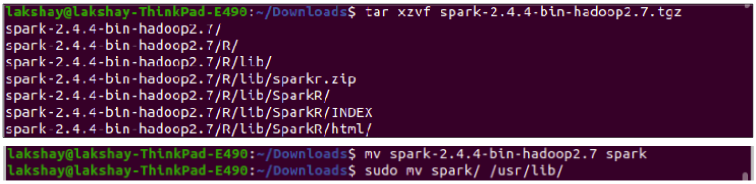
因此,第一步是从这里下载Apache Spark的最新版本。解压并移动压缩文件:
tar xzvf spark-2.4.4-bin-hadoop2.7.tgz
mv spark-2.4.4-bin-hadoop2.7 spark
sudo mv spark/ /usr/lib/
2. 安装JAVA
确保在系统中安装了JAVA。我强烈推荐JAVA 8,因为众所周知,Spark2在JAVA 9和其他方面存在问题:
sudo apt install default-jre
sudo apt install openjdk-8-jdk
3.安装Scala构建工具(SBT)
当你处理一个包含很少源代码文件的小型项目时,手动编译它们会更容易。但是,如果你正在处理一个包含数百个源代码文件的大型项目呢?在这种情况下,你需要使用构建工具。
SBT是Scala构建工具的缩写,它管理你的Spark项目以及你在代码中使用的库的依赖关系。
请记住,如果你使用的是PySpark,就不需要安装它。但是如果你使用JAVA或Scala构建Spark应用程序,那么你需要在你的机器上安装SBT。运行以下命令安装SBT:
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list
curl -sL "https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x2EE0EA64E40A89B84B2DF73499E82A75642AC823" | sudo apt-key add
sudo apt-get update
sudo apt-get install sbt
4. 配置SPARK
接下来,打开Spark的配置目录,复制默认的Spark环境模板。它已经以spark-env.sh.template的形式出现了。使用编辑器打开:
cd /usr/lib/spark/conf/
cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
现在,在文件spark-env.sh中。添加JAVA_HOME,并将内存限制SPARK_WORKER_MEMORY进行赋值。这里,我把它分配为4GB:
## 添加变量
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
SPARK_WORKER_MEMORY=4g
5. 设置Spark环境变量
使用下面的命令打开并编辑bashrc文件。这个bashrc文件是一个脚本,每当你开始一个新的终端会话就会执行:
## 打开bashrc
sudo gedit ~/bashrc
文件中添加以下环境变量:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SBT_HOME=/usr/share/sbt/bin/sbt-launch.jar
export SPARK_HOME=/usr/lib/spark
export PATH=$PATH:$JAVA_HOME/bin
export PATH=$PATH:$SBT_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
export PYSPARK_PYTHON=python3
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
现在,更新bashrc文件。这将在更新脚本的情况下重新启动终端会话:
source ~/.bashrc
现在,在终端中输入pyspark,它将在默认浏览器中打开Jupyter和一个自动初始化变量名为sc的Spark环境(它是Spark服务的入口点):

什么是Spark应用程序?
Spark应用程序是Spark上下文的一个实例。它由一个驱动进程和一组执行程序进程组成。
驱动进程负责维护关于Spark应用程序的信息、响应代码、分发和调度执行器中的工作。驱动进程是非常重要的,它是Spark应用程序的核心,并在应用程序的生命周期内维护所有相关信息。
执行器负责实际执行驱动程序分配给他们的工作。因此,每个执行器只负责两件事:
- 执行由驱动程序分配给它的任务
- 将执行程序上的计算状态报告回驱动程序节点

什么是Spark会话?
我们知道一个驱动进程控制着Spark应用程序。驱动程序进程将自己作为一个称为Spark会话的对象提供给用户。
Spark会话实例可以使用Spark在集群中执行用户自定义操作。在Scala和Python中,当你启动控制台时,Spark会话变量就是可用的:

Spark的分区
分区意味着完整的数据不会出现在一个地方。它被分成多个块,这些块被放置在不同的节点上。
如果只有一个分区,即使有数千个执行器,Spark的并行度也只有一个。另外,如果有多个分区,但只有一个执行器,Spark的并行度仍然只有一个,因为只有一个计算资源。
在Spark中,较低级别的api允许我们定义分区的数量。
让我们举一个简单的例子来理解分区是如何帮助我们获得更快的结果的。我们将在10到1000之间创建一个包含2000万个随机数的列表,并对大于200的数字进行计数。
让我们看看我们能多快做到这只一个分区:
from random import randint
# 创建一个随机数字的列表在10到1000之间
my_large_list = [randint(10,1000) for x in range(0,20000000)]
# 创建一个分区的列表
my_large_list_one_partition = sc.parallelize(my_large_list,numSlices=1)
# 检查分区数量
print(my_large_list_one_partition.getNumPartitions())
# >> 1
# 筛选数量大于等于200的数字
my_large_list_one_partition = my_large_list_one_partition.filter(lambda x : x >= 200)
# 在jupyter中运行代码
# 执行以下命令来计算时间
%%time
# 列表中元素的数量
print(my_large_list_one_partition.count())
# >> 16162207

使用一个分区时,花了34.5毫秒来筛选数字:

现在,让我们将分区的数量增加到5和检查执行时间:
# 创建五个分区
my_large_list_with_five_partition = sc.parallelize(my_large_list, numSlices=5)
# 筛选数量大于等于200的数字
my_large_list_with_five_partition = my_large_list_with_five_partition.filter(lambda x : x >= 200)
%%time
# 列表中元素的数量
print(my_large_list_with_five_partition.count())
# >> 16162207

使用5个分区时,花了11.1毫秒来筛选数字:

转换
在Spark中,数据结构是不可变的。这意味着一旦创建它们就不能更改。但是如果我们不能改变它,我们该如何使用它呢?
因此,为了进行更改,我们需要指示Spark如何修改数据。这些指令称为转换。
回想一下我们在上面看到的例子。我们要求Spark过滤大于200的数字——这本质上是一种转换。Spark有两种类型的转换:
- 窄转换:在窄转换中,计算单个分区结果所需的所有元素都位于父RDD的单个分区中。例如,如果希望过滤小于100的数字,可以在每个分区上分别执行此操作。转换后的新分区仅依赖于一个分区来计算结果

- 宽转换:在宽转换中,计算单个分区的结果所需的所有元素可能位于父RDD的多个分区中。例如,如果你想计算数字个数,那么你的转换依赖于所有的分区来计算最终的结果

惰性计算
假设你有一个包含数百万行的非常大的数据文件。你需要通过一些操作来进行分析,比如映射、过滤、随机分割,甚至是最基本的加减法。
现在,对于大型数据集,即使是一个基本的转换也需要执行数百万个操作。
在处理大数据时,优化这些操作至关重要,Spark以一种非常有创意的方式处理它。你所需要做的就是告诉Spark你想要对数据集进行哪些转换,Spark将维护一系列转换。当你向Spark请求结果时,它将找出最佳路径并执行所需的转换并给出结果。
现在,让我们举个例子。你有一个1gb的文本文件,并创建了10个分区。你还执行了一些转换,最后要求查看第一行。在这种情况下,Spark将只从第一个分区读取文件,在不需要读取整个文件的情况下提供结果。
让我们举几个实际的例子来看看Spark是如何执行惰性计算的。在第一步中,我们创建了一个包含1000万个数字的列表,并创建了一个包含3个分区的RDD:
# 创建一个样本列表
my_list = [i for i in range(1,10000000)]
# 并行处理数据
rdd_0 = sc.parallelize(my_list,3)
rdd_0

接下来,我们将执行一个非常基本的转换,比如每个数字加4。请注意,Spark此时还没有启动任何转换。它只记录了一系列RDD运算图形式的转换。你可以看到,使用函数toDebugString查看RDD运算图:
# 每个数增加4
rdd_1 = rdd_0.map(lambda x : x 4)
# RDD对象
print(rdd_1)
#获取RDD运算图
print(rdd_1.toDebugString())

我们可以看到,PythonRDD[1]与ParallelCollectionRDD[0]是连接的。现在,让我们继续添加转换,将列表的所有元素加20。
你可能会认为直接增加24会先增加4后增加20一步更好。但是在这一步之后检查RDD运算图:
# 每个数增加20
rdd_2 = rdd_1.map(lambda x : x 20)
# RDD 对象
print(rdd_2)
#获取RDD运算图
print(rdd_2.toDebugString())


我们可以看到,它自动跳过了冗余步骤,并将在单个步骤中添加24。因此,Spark会自动定义执行操作的最佳路径,并且只在需要时执行转换。
让我们再举一个例子来理解惰性计算过程。
假设我们有一个文本文件,并创建了一个包含4个分区的RDD。现在,我们定义一些转换,如将文本数据转换为小写、将单词分割、为单词添加一些前缀等。
但是,当我们执行一个动作,比如获取转换数据的第一个元素时,这种情况下不需要查看完整的数据来执行请求的结果,所以Spark只在第一个分区上执行转换
# 创建一个文本文件的RDD,分区数量= 4
my_text_file = sc.textFile('tokens_spark.txt',minPartitions=4)
# RDD对象
print(my_text_file)
# 转换小写
my_text_file = my_text_file.map(lambda x : x.lower())
# 更新RDD对象
print(my_text_file)
print(my_text_file.toDebugString())

在这里,我们把单词小写,取得每个单词的前两个字符。
# 分割单词
my_text_file = my_text_file.map(lambda x : x[:2])
# RDD对象
print(my_text_file)
print(my_text_file.toDebugString())
# 在所有的转换后得到第一个元素
print(my_text_file.first())


我们创建了4个分区的文本文件。但是根据我们需要的结果,不需要在所有分区上读取和执行转换,因此Spack只在第一个分区执行。
如果我们想计算出现了多少个单词呢?这种情况下我们需要读取所有的分区:
print(my_text_file.countApproxDistinct())


Spark MLlib的数据类型
MLlib是Spark的可扩展机器学习库。它包括一些常用的机器学习算法,如回归、分类、降维,以及一些对数据执行基本统计操作的工具。
在本文中,我们将详细讨论MLlib提供的一些数据类型。在以后的文章中,我们将讨论诸如特征提取和构建机器学习管道之类的主题。
局部向量
MLlib支持两种类型的本地向量:稠密和稀疏。当大多数数字为零时使用稀疏向量。要创建一个稀疏向量,你需要提供向量的长度——非零值的索引,这些值应该严格递增且非零值。
from pyspark.mllib.linalg import Vectors
## 稠密向量
print(Vectors.dense([1,2,3,4,5,6,0]))
# >> DenseVector([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 0.0])
### 稠密向量
### Vectors.sparse( length, index_of_non_zero_values, non_zero_values)
### 索引应该严格递增且非零值
print(Vectors.sparse(10, [0,1,2,4,5], [1.0,5.0,3.0,5.0,7]))
# >> SparseVector(10, {0: 1.0, 1: 5.0, 2: 3.0, 4: 5.0, 5: 7.0})
print(Vectors.sparse(10, [0,1,2,4,5], [1.0,5.0,3.0,5.0,7]).toArray())
# >> array([1., 5., 3., 0., 5., 7., 0., 0., 0., 0.])
标签点
标签点(Labeled Point)是一个局部向量,其中每个向量都有一个标签。这可以用在监督学习中,你有一些目标的特征与这些特征对应的标签。
from pyspark.mllib.regression import LabeledPoint
# 设置一个标签与一个稠密向量
point_1 = LabeledPoint(1,Vectors.dense([1,2,3,4,5]))
# 特征
print(point_1.features)
# 标签
print(point_1.label)
局部矩阵
局部矩阵存储在一台机器上。MLlib同时支持稠密矩阵和稀疏矩阵。在稀疏矩阵中,非零项值按列为主顺序存储在压缩的稀疏列格式(CSC格式)中。
# 导入矩阵
from pyspark.mllib.linalg import Matrices
# 创建一个3行2列的稠密矩阵
matrix_1 = Matrices.dense(3, 2, [1,2,3,4,5,6])
print(matrix_1)
# >> DenseMatrix(3, 2, [1.0, 2.0, 3.0, 4.0, 5.0, 6.0], False)
print(matrix_1.toArray())
"""
>> array([[1., 4.],
[2., 5.],
[3., 6.]])
"""
# 创建一个稀疏矩阵
matrix_2 = Matrices.sparse(3, 3, [0, 1, 2, 3], [0, 0, 2], [9, 6, 8])
print(matrix_2)
# SparseMatrix(3, 3, [0, 1, 2, 3], [0, 0, 2], [9.0, 6.0, 8.0], False)
print(matrix_2.toArray())
"""
>> array([[9., 6., 0.],
[0., 0., 0.],
[0., 0., 8.]])
"""
分布式矩阵
分布式矩阵存储在一个或多个rds中。选择合适的分布式矩阵格式是非常重要的。目前已经实现了四种类型的分布式矩阵:
- 行矩阵
- 每一行都是一个局部向量。可以在多个分区上存储行
- 像随机森林这样的算法可以使用行矩阵来实现,因为该算法将行划分为多个树。一棵树的结果不依赖于其他树。因此,我们可以利用分布式架构,对大数据的随机森林等算法进行并行处理
# 分布式数据类型——行矩阵
from pyspark.mllib.linalg.distributed import RowMatrix
# 创建RDD
rows = sc.parallelize([[1,2,3], [4,5,6], [7,8,9], [10,11,12]])
# 创建一个分布式行矩阵
row_matrix = RowMatrix(rows)
print(row_matrix)
# >> <pyspark.mllib.linalg.distributed.RowMatrix at 0x7f425884d7f0>
print(row_matrix.numRows())
# >> 4
print(row_matrix.numCols())
# >> 3
- 索引行矩阵
- 它类似于行矩阵,其中行以有序的方式存储在多个分区中。为每行分配一个索引值。它用于序列很重要的算法,比如时间序列数据
- 它可以从IndexedRow的RDD创建
# 索引行矩阵
from pyspark.mllib.linalg.distributed import IndexedRow, IndexedRowMatrix
#创建RDD
indexed_rows = sc.parallelize([
IndexedRow(0, [0,1,2]),
IndexedRow(1, [1,2,3]),
IndexedRow(2, [3,4,5]),
IndexedRow(3, [4,2,3]),
IndexedRow(4, [2,2,5]),
IndexedRow(5, [4,5,5])
])
# 创建IndexedRowMatrix
indexed_rows_matrix = IndexedRowMatrix(indexed_rows)
print(indexed_rows_matrix.numRows())
# >> 6
print(indexed_rows_matrix.numCols())
# >> 3
- 坐标矩阵
- 可以从MatrixEntry的RDD创建坐标矩阵
- 只有当矩阵的维数都很大时,我们才使用坐标矩阵
from pyspark.mllib.linalg.distributed import CoordinateMatrix, MatrixEntry
# 用MatrixEntry创建
matrix_entries = sc.parallelize([MatrixEntry(0, 5, 2), MatrixEntry(1, 1, 1), MatrixEntry(1, 5, 4)])
# 创建坐标矩阵
c_matrix = CoordinateMatrix(matrix_entries)
# 列数
print(c_matrix.numCols())
# >> 6
# 行数
print(c_matrix.numRows())
# >> 2
- 块矩阵
- 在一个块矩阵中,我们可以在不同的机器上存储一个大矩阵的不同子矩阵
- 我们需要指定块的尺寸。就像下面的例子,我们有3X3,对于每一个方块,我们可以通过提供坐标来指定一个矩阵
# 导入库
from pyspark.mllib.linalg import Matrices
from pyspark.mllib.linalg.distributed import BlockMatrix
# 创建子矩阵块的RDD
blocks = sc.parallelize([((0, 0), Matrices.dense(3, 3, [1, 2, 1, 2, 1, 2, 1, 2, 1])),
((1, 1), Matrices.dense(3, 3, [3, 4, 5, 3, 4, 5, 3, 4, 5])),
((2, 0), Matrices.dense(3, 3, [1, 1, 1, 1, 1, 1, 1, 1, 1]))])
# 从子矩阵块的RDD中创建矩阵块,大小为3X3
b_matrix = BlockMatrix(blocks, 3, 3)
#每一块的列数
print(b_matrix.colsPerBlock)
# >> 3
#每一块的行数
print(b_matrix.rowsPerBlock)
# >> 3
# 把块矩阵转换为局部矩阵
local_mat = b_matrix.toLocalMatrix()
# 打印局部矩阵
print(local_mat.toArray())
"""
>> array([[1., 2., 1., 0., 0., 0.],
[2., 1., 2., 0., 0., 0.],
[1., 2., 1., 0., 0., 0.],
[0., 0., 0., 3., 3., 3.],
[0., 0., 0., 4., 4., 4.],
[0., 0., 0., 5., 5., 5.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.],
[1., 1., 1., 0., 0., 0.]])
"""
结尾
今天我们已经讲了很多了。Spark是数据科学中最迷人的语言之一,我觉得至少应该熟悉它。
这只是我们PySpark学习旅程的开始!我计划在本系列中涵盖更多的内容,包括不同机器学习任务的多篇文章。
在即将发表的PySpark文章中,我们将看到如何进行特征提取、创建机器学习管道和构建模型。
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/