欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
Revolver
本文提及的主要内容有:- 什么是文本摘要生成
- 如何从网页上提取数据
- 如何清洗数据
- 如何构建直方图
- 如何计算句子分数
- 如何提取分数最高的句子/摘要
在继续往下阅读之前,我假设你已经了解下面几个方面的基础知识:
- 正则表达式
- 自然语言处理
- 网页爬虫
一、什么是文本摘要生成
生成文本摘要的过程其实就是总结文本文档中心意思的过程,目的是创建包含原始文档主要内容的摘要。
生成摘要的主要思想是找到包含整个数据集“信息”的数据子集。这种技术在当今行业内被广泛使用。搜索引擎就是一个例子; 其他还包括文档摘要生成,图像收集和视频处理。文档摘要生成算法试图通过查找信息量最大的句子来创建整个文档的代表性摘要,而在图像摘要中,计算机则试图找到最具代表性的显著的图像。对于监控视频,人们可能希望从平静的环境影像中提取出重要事件。
自动摘要有两种通用方法:提取和抽象。
二、如何从网页上提取数据?
第1步:导入库/包
- Beautiful Soup(bs)是一个Python库,用于从HTML和XML文件中提取数据。你可以把它和你最喜欢的解析器一起搭配使用,它们一起提供了一种符合我们习惯的导航,搜索和修改解析树的方法。这通常可以节省程序员数小时或数天的工作量。
- Urllib是一个集合多个URL处理模块的软件包:
urllib.request 用于打开url链接并读取内容
urllib.error 包含由urllib.request抛出的异常值
urllib.parse 用于解析URL
urllib.robotparser用于解析 robots.txt 文件
- re模块提供了类似于在Perl语言里的正则表达式匹配操作功能。
- nltk是一个帮助构建处理人类语言数据的Python程序的强大平台。它为 50多种语料库和词法资源提供了易于使用的接口(如WordNet),还提供了一套用于分类,分词,词干提取,标注,解析和语义推理的文本处理工具库。
- heapq这个模块提供了一个堆队列算法的实现,也称为优先队列算法。
import bs4 as bs
import urllib.request
import re
import nltk
import heapq
接下来检查一下数据包中的stopwords包(停用词)和punkt包是否更新到最新。
nltk.download(‘stopwords’)
nltk.download(‘punkt’)
这里选用了维基上的 Artificial Neural Network 这个页面为例子来说明。你可以根据需要选择其他任何文章。
page = urllib.request.urlopen(“https://en.wikipedia.org/wiki/Artificial_neural_network”).read()
soup = bs.BeautifulSoup(page,‘lxml’)
print(page) #print the page
现在你可以看到我们提取出来的内容,但它看起来有点丑。我们使用BeautifulSoup来解析文档, 并以漂亮的方式来呈现文本。我还使用了prettify函数来使html语法看起来更美观。
print(soup.prettify)
注意:维基百科中的大多数文章都是在<p>标签下编写的,但不同的网站可能采取不同的方式。例如,一些网站会把文字内容写在<div>标签下。
text = “”
for paragraph in soup.find_all(‘p’):
text += paragraph.text
print(text)

三、如何清洗数据
数据清洗指的是对数据集,数据表或数据库中的所有数据,检测并纠正(或删除)损坏的或不准确的记录的过程,也即识别数据中不完整,不正确,不准确或不相关的部分,然后替换,修改,或删除这部分脏数据。
text = re.sub(r’[[0-9]*]’,’ ',text)
text = re.sub(r’s+’,’ ',text)
clean_text = text.lower()
clean_text = re.sub(r’W’,’ ',clean_text)
clean_text = re.sub(r’d’,’ ',clean_text)
clean_text = re.sub(r’s+’,’ ',clean_text)
sentences = nltk.sent_tokenize(text)
stop_words = nltk.corpus.stopwords.words(‘english’)
print(sentences)
第1行:删除文本中由类似[1],[2]表示的所有引用(参见上面的输出文本段)
第2行:用单个空格替换了所有额外的空格
第3行:转换成小写
第4,5,6行:移除所有额外的标点符号,数字,额外空格等。
第7行:使用sent_tokenize()函数将大段的文本分解为句子

stop_words #list

四、如何构建直方图
构建一个直方图可以帮助你直观地发现文章中比较特别的单词。例如“Geoffrey Hinton is the god father of deep learning. And I love deep learning“这一句,需要计算每个不同的单词出现在句子中的次数,例如”deep“和”learning“都出现两次,其余的单词在一个句子中只出现一次。但在现实世界中,你有成千上万条句子,要具体找出每个单词出现多少次就需要构建直方图来表现。
word2count = {} #line 1
for word in nltk.word_tokenize(clean_text): #line 2
if word not in stop_words: #line 3
if word not in word2count.keys():
word2count[word]=1
else:
word2count[word]+=1
for key in word2count.keys(): #line 4
word2count[key]=word2count[key]/max(word2count.values())
第1行:创建一个空字典
第2行:使用word_tokenize分词clean _text分词,对每个单词循环
第3行:检查单词是否在stop_words中,然后再次检查单词是否在word2count的键集中,不在则把word2count [word]置为1,否则word2count [word] 加1。
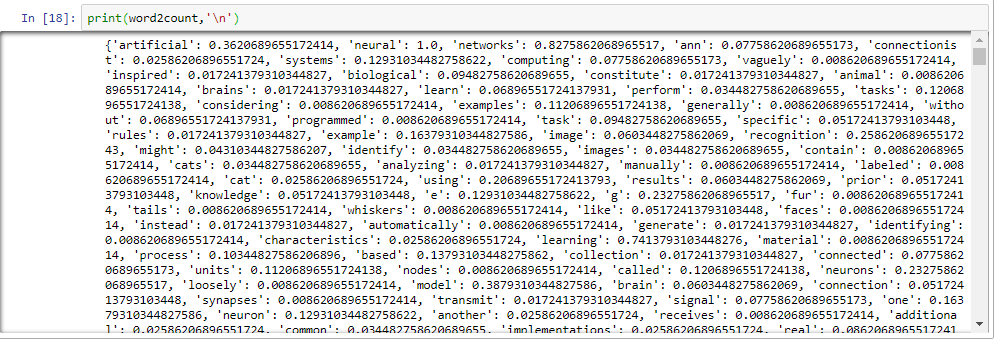
第4行:计算加权直方图(参见下面的输出,你可以看到对每个单词计算了权重而不是计数。 例如有 ‘artificial’:0.3620689等)
五、如何计算句子分数
第1行:创建一个空字典
第2行:对sentences中每个sentence进行循环
第3行:将sentence转换成小写并分词,对每个word循环
第4行:使用if检查word2count.keys()中是否存在该单词
第5行:这里我指定计算句子长度小于30的那部分,你可以根据需要更改
第6行:再次使用if-else条件,判断如果句子不存在于sentence2keys()中,则执行 sent2score [sentence] = word2count [word],否则执行 sent2score [sentence] + = word2count [word]
计算句子分数
sent2score = {}
for sentence in sentences:
for word in nltk.word_tokenize(sentence.lower()):
if word in word2count.keys():
if len(sentence.split(’ '))<30:
if sentence not in sent2score.keys():
sent2score[sentence]=word2count[word]
else:
sent2score[sentence]+=word2count[word]
六、查看句子得分
七、如何提取分数最高的句子作为简短摘要
使用heapq从文章中找到得分最高的七个句子。
best_sentences = heapq.nlargest(7,sent2score,key=sent2score.get)
for sentences in best_sentences:
print(sentences,’ ’)
关于Artificial Neural Network这篇文章七条概括得最好的句子

原文链接
https://towardsdatascience.com/text-summarization-96079bf23e83
Github源码链接
https://github.com/mohitsharma44official/Text--Summarization