在这篇客座文章中,可口可乐公司的 Patrick Brandt 将向我们介绍他们如何使用 AI 和 TensorFlow 实现无缝式购买凭证。
可口可乐的核心忠诚度计划于 2006 年以 MyCokeRewards.com 形式启动。“MCR.com”平台包含为每一瓶以 20 盎司规格销售的可口可乐、雪碧、芬达和动乐产品,以及可以在杂货店和其他零售商店购买的纸箱包装产品创建唯一的产品编码。用户可以在 MyCokeRewards.com 上输入这些产品编码来参加推广活动。

几年后的 2016 年:可口可乐的忠诚度计划仍然大受欢迎,用户已经输入了数以百万计的产品编码来参加促销和抽奖。不过,移动浏览在 2006 年还不存在,而到了 2016 年底已占据超过 50% 的份额。为了响应这些浏览行为变化,Coke.com 作为一项移动优先网络体验启动,替代了原来的 MCR.com。将 14 字符编码手动输入到移动设备中着实是一种非常糟糕的用户体验,会影响我们的计划取得成功。我们希望为移动受众提供尽可能最好的体验,人工智能的最新进展带来了全新的机遇。
实现无缝式购买凭证的任务
多年来,可口可乐一直尝试使用现成的光学字符识别 (OCR) 库和服务读取产品编码,但收效甚微。我们的印刷工艺一般使用低分辨率点阵字体,瓶盖或纸箱媒介在打印头下面以非常快的速度运转。这就产生了低保真字符串,让现成的 OCR 软件无法读取这些字符(有时人眼也很难阅读)。OCR 对简化移动用户的编码输入过程至关重要:用户应当能够为编码拍照,然后自动进行购买注册来参加促销。我们需要一个用途特定的 OCR 系统来识别我们的产品编码。

▲ 瓶盖和纸箱示例
我们的研究将我们引向了一种前景无限的解决方案:卷积神经网络。卷积神经网络是一系列“深度学习”神经网络中的一种,这些神经网络是现代人工智能产品的核心。Google 已使用卷积神经网络从街景图像中提取出街道地址门牌号。卷积神经网络在识别手写数字方面的表现也相当不错。这些数字识别用例完美代表了我们一直尝试解决的问题类型:从包含小字符集并且小字符集中所含字符的外观千差万别的图像中提取字符串。
通过 TensorFlow 实现的卷积神经网络
过去,由于可用的训练和推理库极其复杂,开发像卷积神经网络一样的深度神经网络一直都是一项巨大的挑战。TensorFlow(Google 于 2015 年开放源代码的一种机器学习框架)旨在简化深度神经网络的开发。

TensorFlow 为不同种类的神经元层和热门损失函数提供了高级接口,简化了实现不同卷积神经网络模型架构的工作。快速迭代不同模型架构的能力大大缩短了我们公司构建自定义 OCR 解决方案所需的时间,因为我们可以在短短几天的时间内开发、训练和测试不同的模型。TensorFlow 模型也非常便携:框架以原生方式支持在移动设备上(“边缘上的 AI”)或在远程托管于云端的服务器中执行模型。这就为许多不同平台(包括网络和移动设备)之间的模型执行带来了一种“一劳永逸”的方式。
机器学习:熟能生巧
任何神经网络的智慧都不会超过用于训练它的数据。我们知道自己需要大量带标签的产品编码图像来训练一个卷积神经网络,从而帮助我们实现性能目标。我们的训练集分三个阶段构建:
启动前模拟图像
启动前真实图像
我们的用户在生产中标记的图像
启动前训练阶段的第一项工作是以编程方式生成数以百万计的模拟产品编码图像。这些模拟图像包括倾斜、光照、阴影和模糊强度变化。在模型仅使用模拟图像进行训练时,它对真实图像的预测准确率(即,可信度最高的 10 个预测中准确预测全部 14 个字符的频率)为 50%。这为迁移学习提供了一个基线:最初使用模拟图像训练的模型是将要使用真实图像训练的更准确模型的基础。
挑战现在就成了使用充足的真实图像丰富模拟图像以实现我们的性能目标。我们为 iOS 和 Android 设备构建了一款用途特定的训练应用,“训练人员”可以使用这款应用为编码拍照并添加标签;这些带标签的图像随后迁移到云存储中进行训练。我们对瓶盖和纸箱上的数千个产品编码进行了生产测试,并将代码分配给多个供应商,他们使用这款应用创建初始的真实训练集。
即使是一个经过增强和丰富的训练集,也无法替代最终用户在各种环境条件下创建的图像。我们知道扫描可能导致编码预测不准确,因此我们需要提供一种能让用户迅速纠正这些预测的用户体验。两个组件对提供这种体验至关重要:产品编码验证服务,它从我们最初的忠诚度平台于 2006 年启动以来就一直在使用(用于验证预测的编码是否是真实编码);预测算法,用于执行回归来确定 14 个字符位置上每个字符的可信度。如果预测的编码无效,置信度最高的预测和每个字符的可信度水平将返回到界面。低置信度字符将突出显示,指导用户更新需要注意的字符。

▲ 错误纠正界面让用户可以纠正无效预测并生成有用的训练数据
这个界面创新实现了一个主动学习过程:反馈循环让模型可以将纠正的预测返回训练管道,逐步改进。我们的用户可以通过这种方式随着时间有组织地提高字符识别模型的准确率。
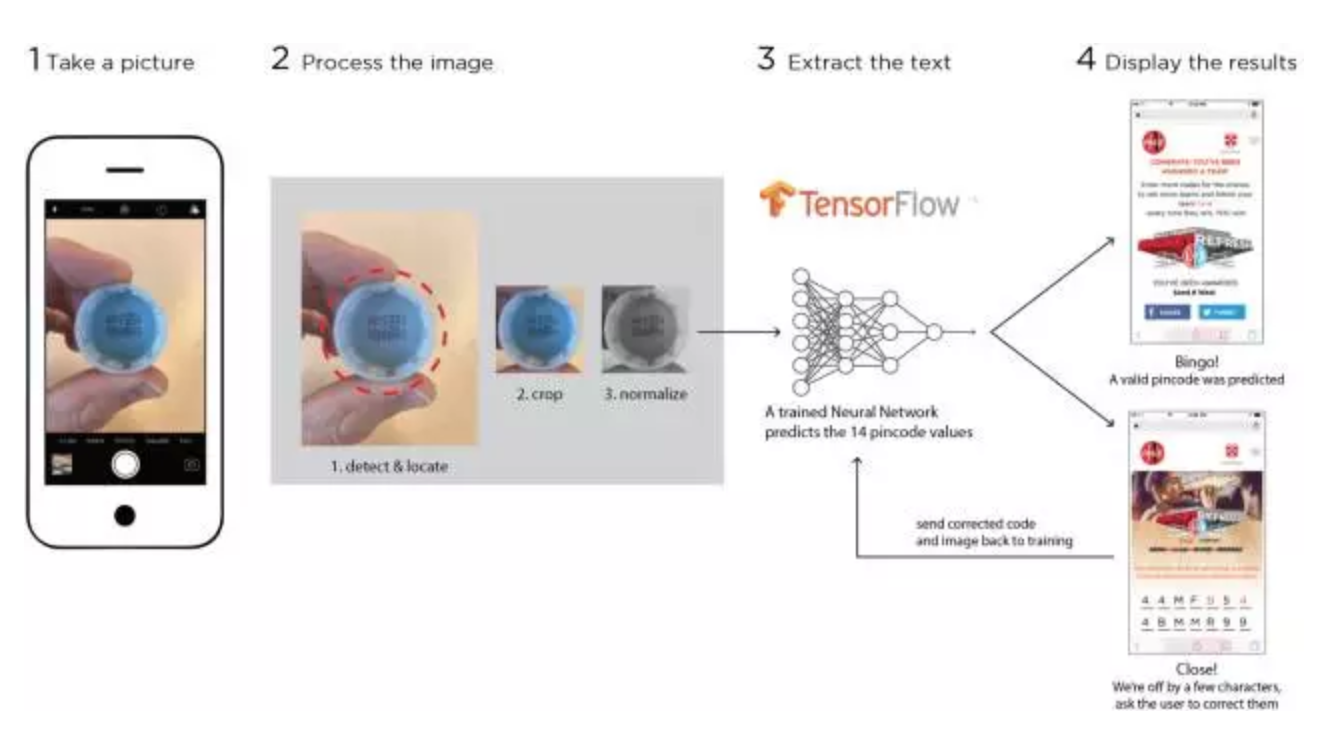
▲ 产品编码识别管道
针对实现最大性能进行优化
为了满足用户对性能的期望,我们为产品编码 OCR 管道建立了一些严格的要求:
快速:我们在产品编码图像发送到 OCR 管道后需要平均一秒的处理时间
准确:我们启动时的目标是实现 95% 的字符串识别准确率,并保证模型可以通过主动学习随着时间不断改进
小型:OCR 管道需要足够小,以便直接分发到移动应用上,并在模型随着时间不断改进时能够适应无线更新
OCR 管道需要处理不同的产品编码介质:数十种不同的字体类型、瓶盖与纸箱包装介质组合

最初,我们探索了一种为所有产品编码介质使用一个卷积神经网络的架构。这种方式创建的模型过大,无法分发至移动应用,并且执行时间也比所需的时间长。我们在 Quantiphi, Inc. 的应用 AI 合作伙伴开始迭代不同的模型架构,并最终确定了一种使用多个卷积神经网络的架构。
这种新架构在不牺牲准确率的前提下显著减小了模型大小,不过仍然无法满足我们为移动应用提供无线更新支持的需要。我们随后使用了 TensorFlow 的预构建量化模块,它可以通过减小相连神经元之间的权重保真度来减小模型大小。量化模块将模型大小减小了 4 系数,但是当 Quantiphi 使用一种名称为 SqueezeNet 的新方式取得突破后,模型大小显著减小。
SqueezeNet 模型由加州大学伯克利分校和斯坦福大学的一组研究人员于 2016 年 11 月发布。它采用小型但高度复杂的设计,根据 Imagenet 等热门基准的数据,它可以实现与大得多的模型相当的准确率水平。在重新设计我们的字符识别模型架构以使用 SqueezeNet 卷积神经网络后,Quantiphi 将特定介质类型的模型大小减小了 100 系数。由于 SqueezeNet 模型本质上就比较小,可以构建更丰富的功能检测架构,凭借比我们第一批并非使用 SqueezeNet 训练的模型显著减小的大小实现明显提高的准确率。我们现在拥有一个可以在远程设备上轻松更新的高度准确模型;我们在主动学习之前的最终模型的识别成功率接近 96%,可以带来 99.7% 的字符识别准确率(每 1000 个字符预测中仅有 3 个出错)。

▲ 具有不同类型遮挡、平移和照相机焦点问题的有效产品编码识别示例
通过 AI 跨越边界
人工智能的发展和 TensorFlow 的成熟让我们最终可以实现梦寐以求的购买凭证能力。自从 2017 年 2 月底启动以来,我们的产品编码识别平台已经为十多个促销活动提供帮助并生成了超过 18 万个扫描代码;它现在已成为可口可乐北美地区所有网络促销活动的核心组件。
迁移到由 AI 提供支撑的产品编码识别平台对我们非常有价值,两个主要原因包括:
及时实现无缝式购买凭证,与我们向移动优先营销平台的整体转变保持一致。
可口可乐避免了更新生产线中的印刷机以支持更高保真度字体(适合现有的现成 OCR 软件)的要求,节省了数百万美元的资金。
我们的产品编码识别平台是以 AI 为支撑的新能力在可口可乐公司内的首次大规模执行。我们目前正在多个业务领域探索 AI 应用,从产品开发到电子商务零售优化,不一而足。
原文链接:https://mp.weixin.qq.com/s/qEnVTpu50L0c7wp8VvJWOA
更多机器学习教程:http://www.tensorflownews.com/