作者|Muktha Sai Ajay
编译|VK
来源|Towards Data Science
介绍
作为人类,我们有能力将在一项任务中获得的知识迁移到另一项任务中去,任务越简单,利用知识就越容易。一些简单的例子是:
-
了解数学和统计学→学习机器学习
-
学会骑自行车→学骑摩托车
到目前为止,大多数机器学习和深度学习算法都是针对解决特定任务而设计的。如果分布发生变化,这些算法会再次被重建,并且很难重建和重新训练,因为它需要计算能力和大量的时间。
迁移学习是关于如何使用预训练好的网络,并将其应用到我们的定制任务中,将它从以前的任务中学到的知识进行迁移。
迁移学习我们可以采用VGG 16和ResNet等架构。这些架构经过了广泛的超参数调整,基于他们已经学到的,我们将这些知识应用到一个新的任务/模型中,而不是从头开始,这就是所谓的迁移学习。
一些迁移学习模型包括:
- Xception
- VGG16
- VGG19
- Resnet, ResnetV2
- InceptionV3
- MobileNet
应用迁移学习实现医学应用
在此应用程序中,我们将检测患者是否患有肺炎。我们使用Kaggle数据集进行分类。下面给出了数据集和代码的链接。
数据集链接:
https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia
代码链接:
https://github.com/ajaymuktha/DeepLearning/blob/master/TransferLearning/transfer-learning.ipynb
数据集由一个训练集和测试集组成,子文件夹为normal(正常)和pneumonia(肺炎)。pneumonia文件夹有肺炎患者的胸部x光图像,normal文件夹中有正常的图像,即没有肺部疾病。
安装Tensorflow
如果你的电脑没有GPU,你可以使用google colab,或者你可以使用Jupyter Notebook。如果你使用你的系统,请升级pip,然后安装TensorFlow,如下所示
导入库
from keras.layers import Input, Lambda, Dense, Flatten
from keras.models import Model
from keras.applications.vgg16 import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
import numpy as np
from glob import glob
import matplotlib.pyplot as plt
调整图像大小
这里,我们将调整所有图像的大小为224*224,因为我们使用VGG16模型,它接受224*224大小的图像。
# 调整图像大小
IMAGE_SIZE = [224, 224]
训练和测试路径
我们将指定训练和测试路径。
train_path = 'Datasets/train'
valid_path = 'Datasets/test'
导入VGG16
vgg = VGG16(input_shape=IMAGE_SIZE + [3], weights='imagenet', include_top=False)
在这里,我们将为我们的应用程序导入VGG16模型权重。我们应该向模型声明一个图像大小,我们已经在上一步中完成了,参数3表示图像将接受RGB图像,即彩色图像。
为了训练我们的模型,我们使用imagenet权重,include_top = False意味着它将从模型中删除最后的层。
训练
像VGG16、VGG19、Resnet等模型已经在成千上万的图像上进行了训练,这些权重用于对数千个类进行分类,因此我们使用这些模型权重对模型进行分类,因此我们不需要再次训练模型。
# 不要训练现有的权重
for layer in vgg.layers:
layer.trainable = False
类数量
我们使用glob来找出模型中类的数量。train文件夹中的子文件夹数表示模型中的类数。
folders = glob('Datasets/train/*')
Flattening
不管我们从VGG16得到的输出是什么,我们都要把它展平,我们把VGG16的最后一层去掉,这样我们就可以保留我们自己的输出层了。我们用问题陈述中的类别数替换最后一层。我们使用softmax做我们的激活函数,我们把它附加到x上。
x = Flatten()(vgg.output)
prediction = Dense(len(folders), activation='softmax')(x)
模型
我们将把它包装成一个模型,其中输入指的是我们从VGG16得到的,而输出是指我们在上一步中创建的输出层。
model = Model(inputs=vgg.input, outputs=prediction)
model.summary()
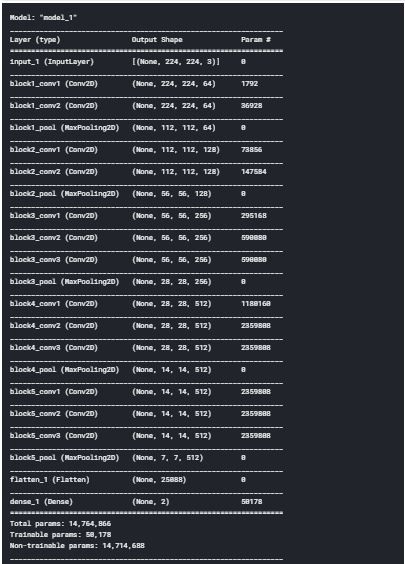
上图是我们模型的摘要,在全连接层,我们有两个节点,因为两个不同的类别我们有肺炎和正常。
编译
我们使用categoricaa_cross_entropy作为损失,adam优化器和精度作为度量标准来编译我们的模型。
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
预处理
为了避免过度拟合,我们将对训练图像进行一些变换,如果不进行变换,训练集和测试集的精度会有很大的差异。
我们执行一些几何变换,比如水平翻转图像、垂直翻转图像、放大、缩小等等,我们应用它,这样我们的模型就不会过拟合我们的训练图像。我们使用ImageDataGenerator类执行上述方法。
我们不为测试集应用转换,因为我们只使用它们来评估,我们测试集的唯一任务就是重新调整图像大小,因为在训练部分,我们为图像定义了一个可以输入网络的目标大小。
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale = 1./255,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True)
test_datagen = ImageDataGenerator(rescale = 1./255)
flow_from_directory将图像增强过程连接到我们的训练集。我们需要传递我们训练集的路径。Target size是需要输入神经网络的图像的大小。batch size定义32,class mode是分类(categorical)的,因为我们只有两个输出。
training_set = train_datagen.flow_from_directory('Datasets/train',
target_size = (224, 224),
batch_size = 32,
class_mode = 'categorical')
现在我们定义从目录导入测试映像的测试集。我们定义了参数,跟训练集一样。
test_set = test_datagen.flow_from_directory('Datasets/test',
target_size = (224, 224),
batch_size = 32,
class_mode = 'categorical')
拟合模型
我们将拟合我们的模型,并声明epoch的数量为5,每个epoch的长度是训练集的长度,验证的长度是测试集的长度。
r = model.fit_generator(
training_set,
validation_data=test_set,
epochs=5,
steps_per_epoch=len(training_set),
validation_steps=len(test_set)
)
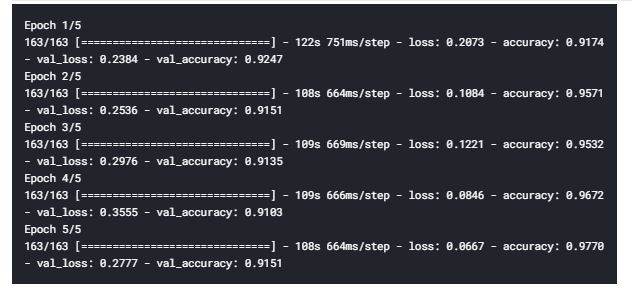
很好,我们达到了97.7%的准确率和91.5%的验证准确率,这就是迁移学习的力量。希望你喜欢这篇关于迁移学习的教程。
原文链接:https://towardsdatascience.com/introduction-to-transfer-learning-c59f6f27e3e
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/