作者|Andy Reagan
编译|VK
来源|Towards Datas Science
在MATLAB和数值计算的世界,for循环被剪掉,而向量为王。
在我的博士学位期间,Lakoba教授的数值分析课是我参加的最具挑战性的课程之一,在课程之后,我对向量代码有了深刻的理解。
我最喜欢的向量化例子是,一位同事在写了一篇非常酷的论文,对其中所涉及的大量计算做了脚注,与我分享了他的lorenz96代码。其中,内部的向量化速度比没有向量化快了4倍。
现在,快速向量代码使机器学习成为可能。例如QR分解,虽然我还没做过,但我确信现在我可以用MATLAB或Numpy或Julia编写。
我在MassMutual做的很多工作基本上都是数值计算,一条耗时数小时与耗时数秒的管道之间的差异巨大。秒意味着我们可以迭代,尝试更多的选项。不过,为了灵活性,很多数值代码都是用纯Python(没有Cython,没有Numba)编写的。我要说这是个坏想法!下面是一封同事的转述邮件:
在伪代码中,这是几个月前我遇到的“精算”编码难题:
EOM = 0
for months in years:
PREM = 50
BOM = EOM + PREM
WIT = 5
EOM = BOM – WIT一个简单的例子,但是我认为显示了BOM/EOM的相互依赖性(还有一些其他变量具有相似的关系)。你不能在不知道EOM的情况下对BOM进行向量化,而且在知道BOM之前也不能对EOM进行向量化。如果WIT>0,PREM=0。基本上会出现很多相互依赖的情况。现在很多函数都不容易出现向量化。
好吧,我可以向量化这个,我做到了。以下是Python中的非向量化版本:
import numpy as np
years = 10
bom = np.zeros(years*12)
eom = np.zeros(years*12)
for month in range(1, years*12):
prem = 50
bom[month] = eom[month-1] + prem
wit = 5
eom[month] = bom[month] - wit
这是向量化版本:
import numpy as np
years = 10
prem = 50
wit = 5
eom = np.arange(years*12)*prem - np.arange(years*12)*wit
# 如果你仍希望将bom表作为数组:
bom = eom + np.arange(years*12)*wit
我还通过使用一系列字典来编写for循环:
years = 10
prem = 50
wit = 5
result = [{'bom': 0, 'eom': 0}]
for month in range(1, years*12):
inner = {}
inner.update({'bom': result[month-1]['eom'] + prem})
inner.update({'eom': inner['bom'] - wit})
result.append(inner)
上面的这个返回一个不同类型的东西,一个dict列表…而不是两个数组。
我们还可以导入Pandas来填充上述三个结果的结果(因此它们是一致的输出,我们可以保存到excel中,等等)。如果加载了Pandas,则可以使用空数据帧进行迭代,因此还有一个选项:
import numpy as np
import pandas as pd
years = 10
prem = 50
wit = 5
df = pd.DataFrame(data={'bom': np.zeros(years*12), 'eom': np.zeros(years*12)})
for i, row in df.iterrows():
if i > 0:
row.bom = df.loc[i-1, 'eom']
row.eom = row.bom - wit
对于所有这些类型的迭代,以及返回数据帧作为结果的选项,我们得到的结果是:
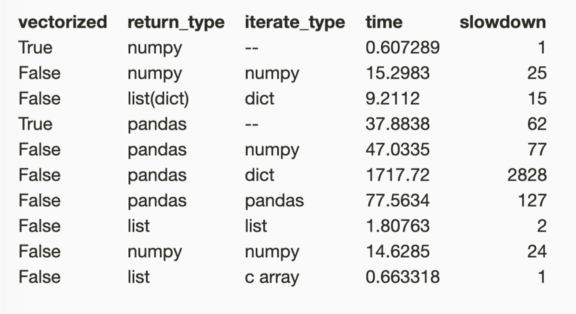
Cython 和Numba
我还添加了一些Cython版本的代码,说明使用C可以在不使用numpy的情况下获得向量化的性能,这确实可能在可读性还有速度之间达到最佳平衡(保持for循环!)。
Numba也可以加速(它可能和Cython/Vectorized Numpy一样快)。在这两种情况下(Cython/Numba),你必须小心使用哪些数据类型(因为没有dicts或pandas!)。我认为,如果你对如何集成Cython+Numpy循环更聪明的话,它将有可能使Cython+Numpy循环与向量化Numpy一样快。
所有代码,包括Cython,都可以在这里找到:https://github.com/andyreagan/vectorizing-matters。
原文链接:https://towardsdatascience.com/vectorizing-code-matters-66c5f95ddfd5
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/