作者|Michael Chau
编译|VK
来源|Towards Data Science

大家都知道Scikit-Learn——它是数据科学家基本都知道的产品,提供了几十种易于使用的机器学习算法。它还提供了两种现成的技术来解决超参数调整问题:网格搜索(GridSearchCV)和随机搜索(RandomizedSearchCV)。
这两种技术都是找到正确的超参数配置的强力方法,但是这是一个昂贵和耗时的过程!
如果想加快这个过程呢
在这篇博客文章中,我们介绍了tune-sklearn(https://github.com/ray-project/tune-sklearn),它使得在使用Scikit-Learn API的同时更容易利用这些新算法。
Tune sklearn是Scikit Learn模型选择模块的一个替代品,采用了先进的超参数调整技术(贝叶斯优化、早期停止、分布式执行)——这些技术比网格搜索和随机搜索提供了显著的加速!
以下是tune sklearn提供的功能:
-
与Scikit Learn API的一致性:tune sklearn是GridSearchCV和RandomizedSearchCV的一个替换,因此你只需要在标准Scikit Learn脚本中更改不到5行即可使用API。
-
现代超参数调整技术:tune-sklearn允许你通过简单地切换几个参数,就可以轻松地利用贝叶斯优化、超空间和其他优化技术。
-
框架支持:tune-sklearn主要用于调优Scikit-Learn模型,但它也支持并为许多其他具有Scikit-Learn框架提供示例,例如Skorch (Pytorch)、KerasClassifiers(Keras)和XGBoostClassifiers(XGBoost)。
-
分布式:Tune sklearn利用Ray Tune,一个分布式超参数调优库,高效透明地并行化多核甚至多台机器上的交叉验证。

Tune sklearn也很快。为了看到这一点,我们在标准的超参数扫描上,将tune sklearn(启用早期停止)与本机Scikit Learn进行基准测试。在我们的基准测试中,我们可以看到普通笔记本电脑和48个CPU核心的大型工作站的显著性能差异。
对于更大的基准48核计算机,Scikit Learn花了20分钟在大小为40000的数据集上搜索75个超参数集。Tune sklearn只花了3.5分钟,并且以最小影响性能的方式执行。

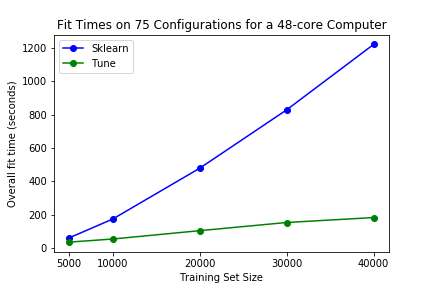
第一个图:在个人双核i5 8gb ram笔记本电脑上,搜索6个超参集。第二个图:在一台48核250gb ram的大型计算机上,搜索75个超参集。
注意:对于较小的数据集(10000个或更少的数据点),在试图应用早期停止时,可能会牺牲准确性。我们预计这不会对用户产生影响,因为该库旨在用大型数据集加速大型训练任务。
简单的60秒漫游
运行pip install tune-sklearn ray[tune]开始下面章节的示例代码。
让我们来看看它是如何工作的。
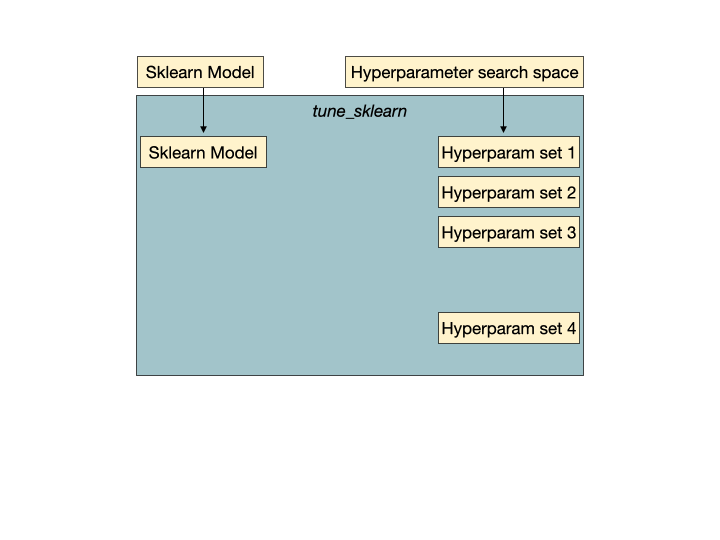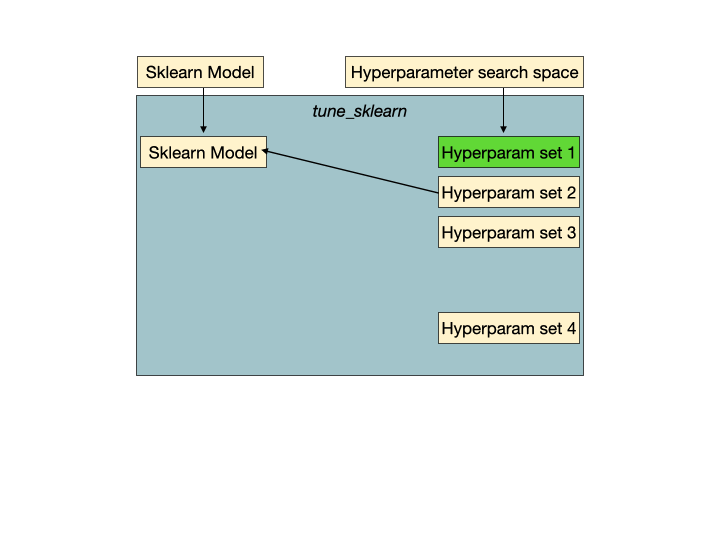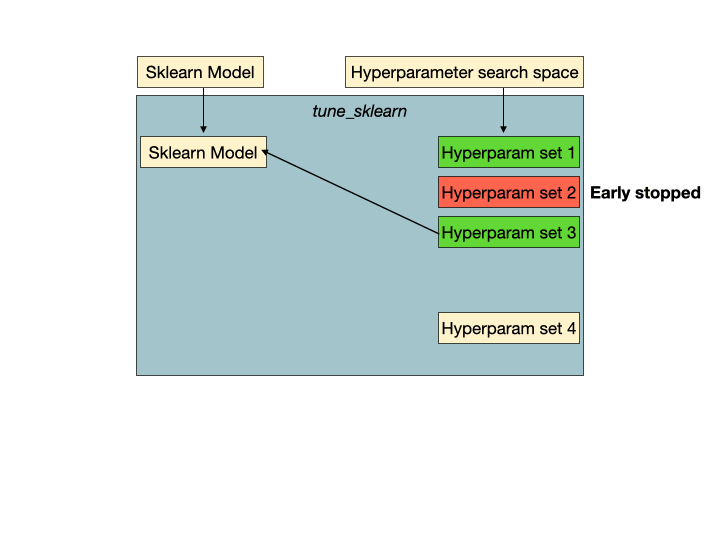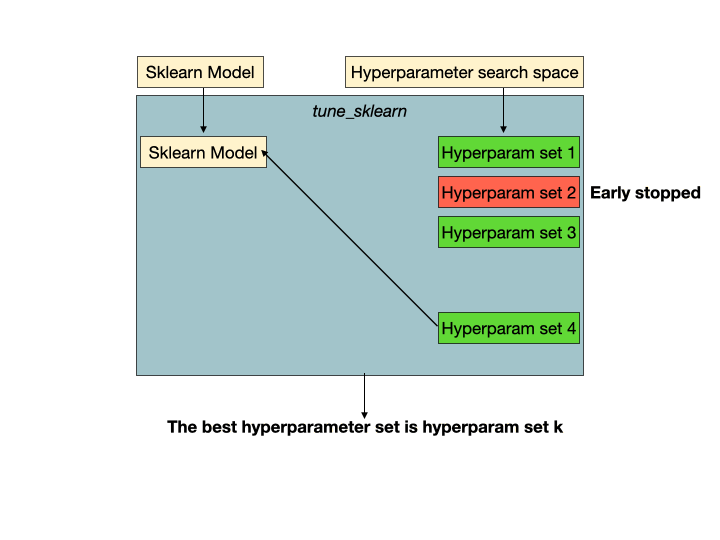
Hyperparam set 2是一组没有希望的超参数,它将被tune的早期停止机制检测到,并提前停止以避免浪费训练时间和资源。
TuneGridSearchCV示例
首先,只需更改import语句即可获得Tune的网格搜索交叉:
# from sklearn.model_selection import GridSearchCV
from tune_sklearn import TuneGridSearchCV
从这里开始,我们将像在Scikit Learn的接口风格中继续!让我们使用一个“虚拟”自定义分类数据集和一个SGD分类程序来对数据进行分类。
我们选择SGDClassifier是因为它有一个partial_fit的 API,这使得它能够停止拟合特定超参数配置的数据。如果估计器不支持早期停止,我们将回到并行网格搜索。
# 导入其他库
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDClassifier
# 设置训练集和验证集
X, y = make_classification(n_samples=11000, n_features=1000, n_informative=50,
n_redundant=0, n_classes=10, class_sep=2.5)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1000)
# 从SGDClassifier调优的示例参数
parameters = {
'alpha': [1e-4, 1e-1, 1],
'epsilon':[0.01, 0.1]
}
如你所见,这里的设置正是你为Scikit Learn所做的设置!现在,让我们试着拟合一个模型。
tune_search = TuneGridSearchCV(
SGDClassifier(),
parameters,
early_stopping=True,
max_iters=10
)
import time # 比较拟合时间
start = time.time()
tune_search.fit(X_train, y_train)
end = time.time()
print("Tune Fit Time:", end - start)
pred = tune_search.predict(X_test)
accuracy = np.count_nonzero(np.array(pred) == np.array(y_test)) / len(pred)
print("Tune Accuracy:", accuracy)
请注意我们在上面介绍的细微差别:
-
一个新的early_stopping变量,以及
-
max_iters参数
early_stopping决定何时停止,MedianStoppingRule 是一个很好的默认设置,但是请参阅Tune的关于调度器的文档,以获得可供选择的完整列表:https://docs.ray.io/en/master/tune-schedulers.html
max_iters是给定的超参数集可以运行的最大迭代次数;如果提前停止搜索超参数集,则可以运行较少的迭代。
请尝试将其与GridSearchCV进行比较
from sklearn.model_selection import GridSearchCV
# n_jobs=-1 使用所有内核
sklearn_search = GridSearchCV(
SGDClassifier(),
parameters,
n_jobs=-1
)
start = time.time()
sklearn_search.fit(X_train, y_train)
end = time.time()
print("Sklearn Fit Time:", end - start)
pred = sklearn_search.predict(X_test)
accuracy = np.count_nonzero(np.array(pred) == np.array(y_test)) / len(pred)
print("Sklearn Accuracy:", accuracy)
TuneSearchCV贝叶斯优化示例
除了网格搜索接口之外,tunesklearn还提供了一个接口TuneSearchCV,用于从超参数分布中进行采样。
此外,只需几行代码更改,就可以轻松地对TuneSearchCV中的发行版启用贝叶斯优化。
运行pip install scikit-optimize以尝试以下示例:
from tune_sklearn import TuneSearchCV
# 其他导入
import scipy
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDClassifier
# 设置训练集和验证集
X, y = make_classification(n_samples=11000, n_features=1000, n_informative=50,
n_redundant=0, n_classes=10, class_sep=2.5)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1000)
# 从SGDClassifier调优的示例参数
# 注意,如果需要贝叶斯优化,则使用元组
param_dists = {
'alpha': (1e-4, 1e-1),
'epsilon': (1e-2, 1e-1)
}
tune_search = TuneSearchCV(SGDClassifier(),
param_distributions=param_dists,
n_iter=2,
early_stopping=True,
max_iters=10,
search_optimization="bayesian"
)
tune_search.fit(X_train, y_train)
print(tune_search.best_params_)
第17、18和26行是为启用贝叶斯优化而更改的代码行
如你所见,将tunesklearn集成到现有代码中非常简单。你可以看看更详细的例子:https://github.com/ray-project/tune-sklearn。
另外请看一看Ray对joblib的替代,它允许用户在多个节点(而不仅仅是一个节点)上并行化训练,从而进一步加快了训练速度。
文档和示例
-
示例:Skorch with tune-sklearn:https://github.com/ray-project/tune-sklearn/blob/master/examples/torch_nn.py)
-
示例:Scikit-Learn Pipelines with tune-sklearn:https://github.com/ray-project/tune-sklearn/blob/master/examples/sklearn_pipeline.py
-
示例:XGBoost with tune-sklearn:https://github.com/ray-project/tune-sklearn/blob/master/examples/xgbclassifier.py
-
示例:KerasClassifier with tune-sklearn:https://github.com/ray-project/tune-sklearn/blob/master/examples/keras_example.py
-
示例:LightGBM with tune-sklearn:https://github.com/ray-project/tune-sklearn/blob/master/examples/lgbm.py
注意:从导入ray.tune如链接文档所示,仅在nightly Ray wheels上可用,不久将在pip上提供
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/