作者|Mahnoor Javed
编译|VK
来源|Towards Data Science
电子邮件分类是一个机器学习问题,属于监督学习范畴。

这个电子邮件分类的小项目的灵感来自J.K.Rowling以笔名出版的一本书。Udacity的“机器学习简介”提供了算法和项目的全面研究:https://www.udacity.com/course/intro-to-machine-learning--ud120
几年前,罗琳写了一本书《布谷鸟的呼唤》,作者名是罗伯特·加尔布雷思。这本书受到了一些好评,但是没有人关注它,直到Twitter上的一位匿名线人说这是J.K.罗琳。伦敦《星期日泰晤士报》邀请了两位专家,将“布谷鸟”的语言模式与罗琳的《临时空缺》以及其他几位作者的著作进行了比较。在他们的分析结果强烈指向罗琳是作者之后,《泰晤士报》直接询问出版商他们是否是同一个人,出版商证实了这一点。这本书一夜之间大受欢迎。
电子邮件分类工作在相同的基本概念上。通过浏览电子邮件的文本,我们将使用机器学习算法来预测电子邮件是由一个人写的还是另一个人写的。
数据集
数据集可以从以下GitHub存储库获取:https://github.com/MahnoorJaved98/Email-Classification
在这个数据集中,我们有一组电子邮件,其中一半由同一公司的一个人(Sara)编写,另一半由另一个人(Chris)编写。数据基于字符串列表。每个字符串都是电子邮件的文本,经过一些基本的预处理。
我们将根据邮件的文本对邮件进行分类。我们将逐一使用以下算法:朴素贝叶斯、支持向量机、决策树、随机森林、KNN和AdaBoost分类器。
存储库有2个pickle文件:word_data 和email_authors。
email_preprocess python文件用于处理pickles文件中的数据。它将数据拆分为10%测试数据和90%的训练数据。
朴素贝耶斯
朴素贝耶斯方法是一组基于Bayes定理的有监督学习算法,在给定类变量值的情况下,假设每对特征之间条件独立且贡献相等。Bayes定理是计算条件概率的一个简单的数学公式。
高斯朴素贝叶斯是一种朴素贝叶斯,其中特征的可能性被假定为高斯。假设与每个特征相关联的连续值按照高斯分布进行分布。在绘制时,它给出了一条关于特征值平均值对称的钟形曲线。

我们将使用scikit学习库中的Gaussian-naivebayes算法对两位作者的邮件进行分类。
下面是你可以在任何python的ide上实现的python代码,确保你的系统上安装了所需的库。
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
import numpy as np
# 利用高斯贝叶斯算法对邮件进行分类
# 算法是从sklearn库导入的
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 初始化测试和训练集
# 函数preprocess是从email_preprocess.py导入的
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = GaussianNB()
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的准确度
print("Accuracy of Naive Bayes: ", accuracy_score(pred,labels_test))
运行该代码将得到以下结果:
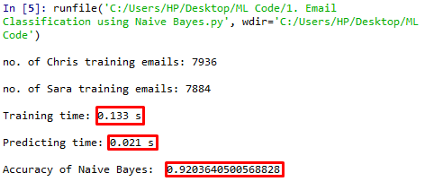
0.9203的准确度。不错吧?即使是算法的训练次数和预测次数也相当合理。
支持向量机
支持向量机也是一种用于分类、回归和异常检测的有监督学习。通过一个平面将数据点划分为两类,利用SVM算法将数据点分类为2类。SVM具有一个直接的决策边界。SVM算法具有通用性,可为决策函数指定不同的核函数。
SVM算法是基于超平面的两类分离,间隔越大,分类越好(也称为间隔最大化)。
我们的分类器是线性核的C支持向量分类,值为C=1
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是训练集和测试集的特征
### labels_train 和 labels_test是对应的标签
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = SVC(kernel = 'linear', C=1)
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的准确度
print("Accuracy of SVM Algorithm: ", clf.score(features_test, labels_test))
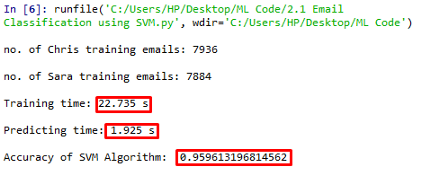
SVM算法的准确度为0.9596。我们可以看到在准确性和训练时间之间有明显的折衷。算法的准确性提高是训练时间较长(22.7s,朴素贝叶斯是0.13s)的结果。我们可以减少训练数据,这样可以在较少的训练时间内获得很好的准确率!
我们将首先将训练数据集分割到原始大小的1%,以释放99%的训练数据。在代码的其余部分不变的情况下,我们可以看到训练时间显著缩短,但是降低了准确性。
使用以下代码将训练数据分割为1%:
features_train = features_train[:len(features_train)//100]
labels_train = labels_train[:len(labels_train)//100]
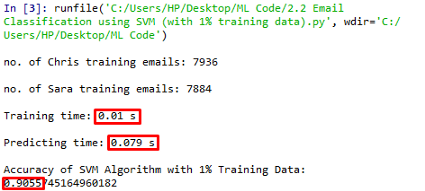
可见,在1%的训练数据下,算法的训练时间缩短到0.01s,精度降低到0.9055。
10%的训练数据,训练时间0.47s,准确度为0.9550。
我们也可以改变scikit-learn的C和核。
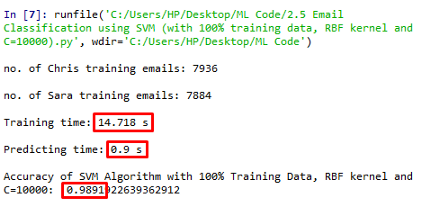
在训练数据100%,RBF核,C值为10000的情况下,训练时间为14.718s,得到了0.9891的精度。
决策树
决策树是一种用于分类和回归的非参数监督学习方法。决策树可以在数据集上执行多类分类。利用从数据特征推断出的决策规则,对每个节点上的数据进行逐步分类。决策树很容易可视化。我们可以通过可视化数据集通过树来理解算法,并在各个节点做出决定。
让我们看看这个算法是如何在我们的数据集上工作的。
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
from sklearn import tree
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是训练集和测试集的特征
### labels_train 和 labels_test是对应的标签
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = tree.DecisionTreeClassifier()
print("
Length of Features Train", len(features_train[0]))
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的准确度
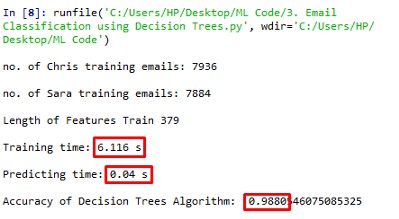
print("Accuracy of Decision Trees Algorithm: ", accuracy_score(pred,labels_test))
运行上述代码,我们的准确度为0.9880,训练时间为6.116s,这是一个非常好的准确性分数,不是吗?我们有100%的训练数据用于训练模型。
随机森林

随机森林是一种基于决策树的集成监督学习算法。随机森林用于回归和分类任务。该算法的名字来源于随机选择的特征。
我们可以在我们的数据集上使用sklearn库中的随机森林算法:RandomForestClassifier。
下面是在我们的电子邮件分类问题上运行随机森林算法的代码。
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是训练集和测试集的特征
### labels_train 和 labels_test是对应的标签
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = RandomForestClassifier(max_depth=2, random_state=0)
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的准确度
print("Accuracy of Random Forest Algorithm: ", accuracy_score(pred,labels_test))
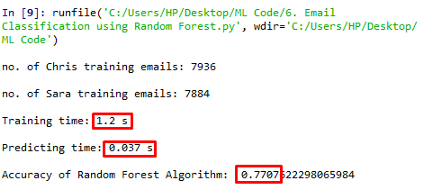
该算法的精度很低,即0.7707。训练时间是1.2秒,这是合理的,但总的来说,它并不是解决我们问题的好工具。特征选择的随机性是造成精度低的原因,而随机是随机森林的一种特性。
KNN
K近邻是一种有监督的机器学习算法,可用于分类和回归预测问题。KNN是懒惰学习。它依赖于距离进行分类,因此对训练数据进行规范化可以大大提高分类精度。
让我们看看使用sklearn库的KNeighborsClassifier的KNN算法对电子邮件进行分类的结果,该算法有5个最近邻和使用欧几里德度量。
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是训练集和测试集的特征
### labels_train 和 labels_test是对应的标签
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的精度
print("Accuracy of KNN Algorithm: ", accuracy_score(pred,labels_test))
该算法的精度为0.9379,训练时间为2.883s,但是可以注意到,模型工具预测类的时间要长得多。
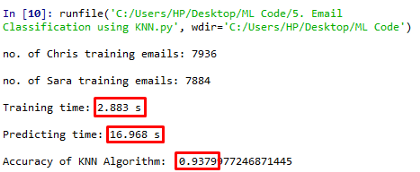
AdaBoost分类器

Ada-boost或自适应Boosting也是一种集成Boosting分类器。它是一种元估计器,首先在原始数据集上拟合一个分类器,然后在同一个数据集上拟合该分类器的附加副本,但是在这种情况下,错误分类实例的权重被调整,以便后续分类器更关注困难的情况。
我们将使用scikit库中的分类器。代码如下:
import sys
from time import time
sys.path.append("C:\Users\HP\Desktop\ML Code\")
from email_preprocess import preprocess
from sklearn.ensemble import AdaBoostClassifier
from sklearn.metrics import accuracy_score
### features_train 和 features_test 是训练集和测试集的特征
### labels_train 和 labels_test是对应的标签
features_train, features_test, labels_train, labels_test = preprocess()
# 定义分类器
clf = AdaBoostClassifier(n_estimators=100, random_state=0)
# 训练和测试时间的预测
t0 = time()
clf.fit(features_train, labels_train)
print("
Training time:", round(time()-t0, 3), "s
")
t1 = time()
pred = clf.predict(features_test)
print("Predicting time:", round(time()-t1, 3), "s
")
# 计算并打印算法的精度
print("Accuracy of Ada Boost Classifier: ", accuracy_score(pred,labels_test))
该分类器的训练时间为17.946s,精度为0.9653,但训练时间稍长。

结论
在本文中,我们使用了几种机器学习算法来对Chris和Sara之间的电子邮件进行分类。这些算法在0.77-0.98的范围内产生了不同的准确度得分。从下表中可以看出,模型是通过提高准确度排列的:
-
随机森林算法的准确度得分最低
-
支持向量机算法训练时间最长
-
参数优化为C=10000和RBF核的支持向量机算法的精度得分最高
-
naivebayes算法的预测时间最快
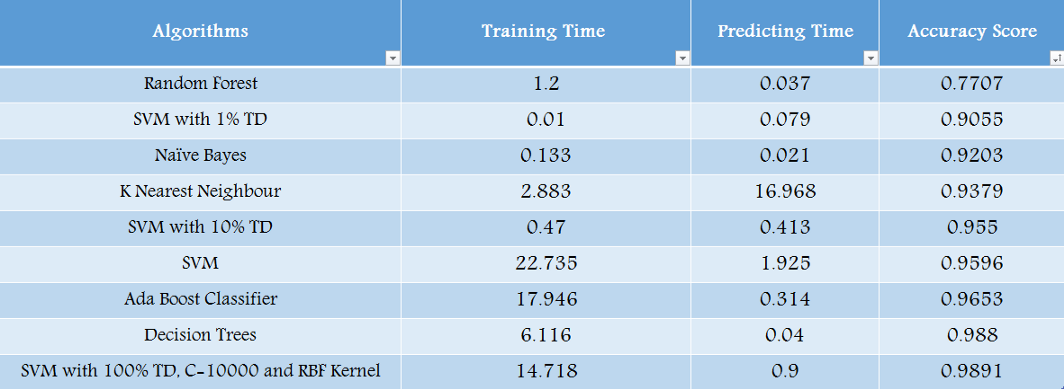
虽然有许多其他分类算法可用于我们的任务,但通过对数据集上运行的基本算法的比较得出结论,对于我们的特定问题,支持向量机是最准确的,因为它的参数是根据我们所处理的任务优化的。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/